Table of Contents
When working with external data sources like an Excel file, a common requirement is ensuring that the imported dataset has meaningful and descriptive column names. While many data processing tools offer an option to automatically designate the first row of data as the header, this approach is often inadequate when the source file lacks explicit headers or when custom labels are required for analysis. Proper naming is crucial for subsequent operations, ensuring clarity and avoiding errors stemming from default integer or placeholder labels.
If your spreadsheet already includes headers in the first row, most import utilities, including the Pandas library in Python, will recognize and utilize them by default. However, when headers are missing, or if you need to enforce a standardized set of names across multiple files, you must explicitly define these labels during the import process. This prevents the loss of your first data record, which would otherwise be incorrectly consumed as metadata. This guide focuses on leveraging the powerful names argument within the Pandas read_excel() function to achieve precise control over your imported DataFrame structure.
The Challenge of Missing or Misaligned Headers
Data imported from real-world sources frequently presents irregularities. One of the most common issues encountered by data analysts is an Excel file where the first row contains actual data points rather than descriptive headers. When using standard data ingestion libraries without specific instructions, the default behavior is often to promote this first row of data to serve as the labels for the subsequent columns. This results in two major problems: the loss or misinterpretation of the first data record, and the creation of hard-to-read column names that are numerical or arbitrary strings taken from the data itself.
To maintain data integrity and ensure high-quality, reproducible analysis, we must instruct the importing tool—in this case, Pandas—exactly how to handle the header structure. This explicit definition avoids relying on assumption-based default settings. Furthermore, defining headers explicitly allows for consistent naming conventions, which is paramount in complex analytical pipelines where multiple datasets must be merged, filtered, or joined based on standardized identifiers.
Core Syntax: Explicitly Defining Column Names
When utilizing the Pandas library in Python, the primary mechanism for importing data from spreadsheets is the read_excel() function. To explicitly define the column names during this process, you must utilize the names argument. This argument accepts a list of strings, where each string corresponds to the desired name for each column in the final DataFrame.
The structure is straightforward and integrates seamlessly into the standard import function call. The following basic syntax demonstrates how to set these custom column names when importing an Excel file into Pandas:
colnames = ['col1', 'col2', 'col3'] df = pd.read_excel('my_data.xlsx', names=colnames)
The names argument is designed to accept an ordered list of strings (colnames), which are then applied sequentially to the columns of the imported data. By providing this list, you are simultaneously achieving two critical goals: establishing meaningful column labels and instructing Pandas to treat the first row of the Excel file as the first row of data, rather than consuming it as a header row. This is the fundamental difference between using the names argument and relying on default header detection.
Understanding the Behavior of the names Argument
The names parameter in read_excel() fundamentally alters how Pandas interprets the input data stream. When names is provided, the function assumes that the source file does not contain a header row. Consequently, it treats every row, starting with the very first one (index 0), as data records. The supplied list of names is then applied directly to the resulting DataFrame columns.
If you were to omit the names argument, Pandas would typically default to header=0, meaning it expects the header to be in the first row (row index 0) of the spreadsheet. When names is provided, the effective behavior shifts to header=None, even if that parameter is not explicitly set. This ensures that the data content is fully preserved, preventing valuable records from being incorrectly assigned to metadata roles. Understanding this interplay between names and header is essential for robust data preparation.
Case Study Setup: Importing Data Without Headers
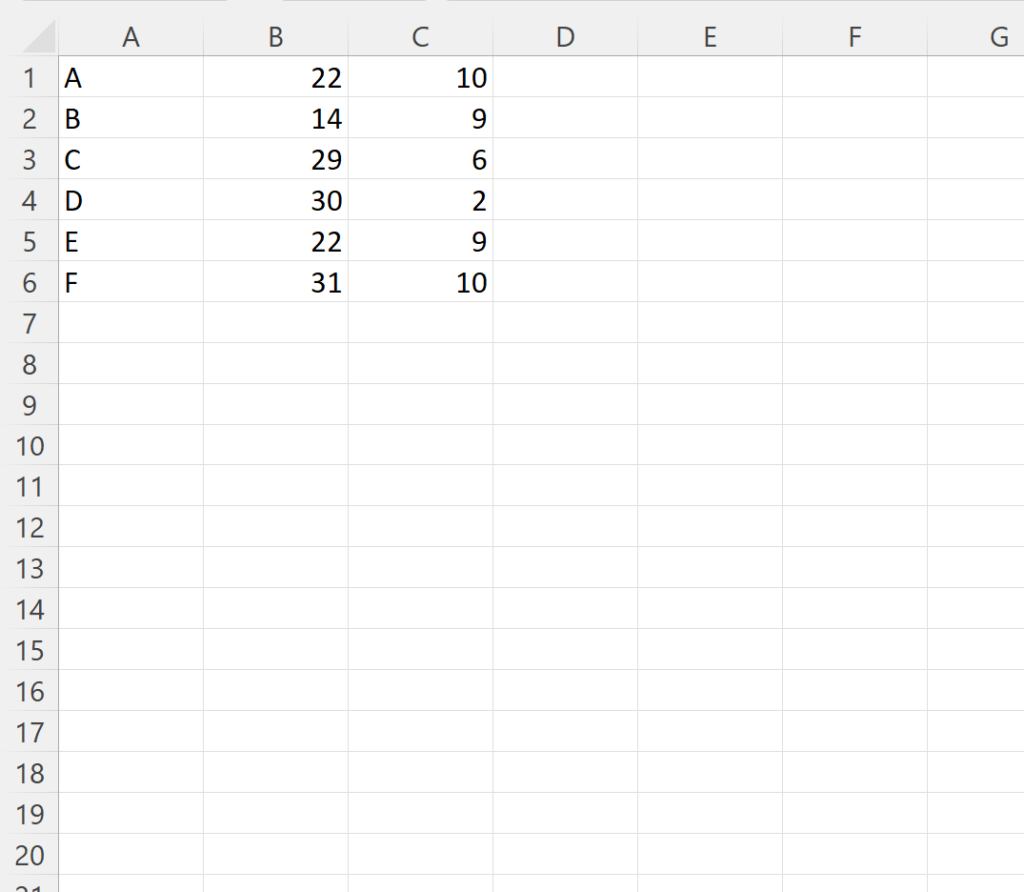
To illustrate the necessity of the names argument, consider a practical scenario involving player statistics. Suppose we have an Excel file named players_data.xlsx. This file contains three columns representing a player identifier, total points scored, and total rebounds. Crucially, the creator of this spreadsheet omitted the descriptive headers, meaning the very first row contains the statistics for the first player (e.g., Team A, 22 points, 10 rebounds).
If we proceed with a standard import using Pandas without defining the column structure, the resulting DataFrame will be improperly formatted. We must clearly demonstrate this default failure mode before applying the corrective action. The following image represents the raw structure of the players_data.xlsx file we are working with:

As clearly visible in the source file, the first row (A, 22, 10) does not contain any descriptive labels; it is purely data. This is the exact scenario where manual specification of column names becomes mandatory to preserve the integrity of the dataset.
Demonstration: Analyzing Default Import Behavior
If we attempt to import the players_data.xlsx file using only the basic read_excel() function, Pandas will execute its default behavior. This means it will automatically assume that the first row is intended to be the header row for the resulting DataFrame.
The consequence of this default assumption is the promotion of the first actual data record into the header row, resulting in column labels that are confusing (A, 22, 10) and the loss of that record from the main data body. Furthermore, the remaining rows are indexed numerically, as shown in the output below:
import pandas as pd #import Excel file using default settings df = pd.read_excel('players_data.xlsx') #view resulting DataFrame print(df) A 22 10 0 B 14 9 1 C 29 6 2 D 30 2 3 E 22 9 4 F 31 10
Observe the header row in the resulting DataFrame: it displays ‘A’, ’22’, and ’10’. These values should be the data points for the first observation, but instead, they are serving as cryptic column names. The actual data begins on index 0 with the values ‘B’, ’14’, and ‘9’. This output confirms that the default settings are unsuitable for Excel files lacking proper headers, necessitating the use of the names argument for correction.
Solution Implementation: Applying the names Parameter
To correctly import the data and assign appropriate labels, we must utilize the names argument in the read_excel() function. We define a list of meaningful strings that accurately describe the contents of each column—in this case, 'team', 'points', and 'rebounds'.
By passing this list via the names parameter, we explicitly instruct Pandas to ignore any potential header information in the file and instead use our supplied list as the definitive column names. This action ensures that the first row of data is correctly retained as the initial record in the DataFrame.
import pandas as pd #specify desired column names colnames = ['team', 'points', 'rebounds'] #import Excel file and use specified column names df = pd.read_excel('players_data.xlsx', names=colnames) #view resulting DataFrame print(df) team points rebounds 0 A 22 10 1 B 14 9 2 C 29 6 3 D 30 2 4 E 22 9 5 F 31 10
The resulting DataFrame now exhibits the intended structure. The descriptive column names—team, points, and rebounds—are correctly applied. Furthermore, the first record from the Excel file (A, 22, 10) is now properly included in the data body, assigned to index 0, demonstrating the successful bypass of the default header detection mechanism.
Alternative Approaches and Advanced Considerations
While the names argument is the most direct way to assign explicit column labels when a file has no header row, there are scenarios where alternative or complementary parameters might be useful:
Using
header=None: Settingheader=Noneforces Pandas to assign default integer column names (0, 1, 2, …). This is useful if you intend to rename the columns immediately after import using thedf.columns = [...]attribute assignment. However, usingnamesis generally preferred as it completes both steps (import and rename) in a single, atomic operation.Handling Data with Skip Rows: If the metadata or arbitrary comments exist above the actual data, you might need to combine
nameswith theskiprowsargument. For example,skiprows=5tellsread_excel()to ignore the first five lines before starting the import process, and then thenameslist is applied to the first record encountered after the skip.Partial Column Selection: If you only need a subset of the columns, you can use the
usecolsargument in conjunction withnames. This allows you to specify which columns (by index or letter) should be imported, and yournameslist must correspond only to the columns that are actively being loaded into the DataFrame.
These advanced methods ensure that analysts have maximum flexibility when dealing with complex or messy Excel file formats, maintaining clean, descriptive, and functional column names regardless of the source file’s initial configuration. The key principle is always to avoid relying on implicit assumptions about data structure.
Conclusion and Further Resources
Explicitly setting column names during the import of an Excel file into Pandas is a fundamental skill for data preparation, particularly when dealing with raw data that lacks standardized headers. By leveraging the names argument in the read_excel() function, data integrity is preserved, and the resulting DataFrame is immediately ready for analysis with clear, descriptive labels. This technique eliminates ambiguity and significantly improves code readability and maintenance.
For more detailed information on all available parameters and advanced functionality regarding spreadsheet ingestion, it is highly recommended to consult the official documentation for the function. Mastery of arguments like names, header, skiprows, and usecols allows developers to handle virtually any Excel file format effectively and efficiently.
Note: You can find the complete documentation for the pandas read_excel() function here, which details all parameters, including the critical names argument.
Cite this article
stats writer (2025). How to Easily Set Column Names When Importing Excel Files. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-do-i-set-column-names-when-importing-an-excel-file/
stats writer. "How to Easily Set Column Names When Importing Excel Files." PSYCHOLOGICAL SCALES, 21 Nov. 2025, https://scales.arabpsychology.com/stats/how-do-i-set-column-names-when-importing-an-excel-file/.
stats writer. "How to Easily Set Column Names When Importing Excel Files." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/how-do-i-set-column-names-when-importing-an-excel-file/.
stats writer (2025) 'How to Easily Set Column Names When Importing Excel Files', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-do-i-set-column-names-when-importing-an-excel-file/.
[1] stats writer, "How to Easily Set Column Names When Importing Excel Files," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, November, 2025.
stats writer. How to Easily Set Column Names When Importing Excel Files. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.