Table of Contents
Analyzing and ordering data is a fundamental requirement in data management, especially when utilizing powerful tools like Google Sheets. One of the common challenges encountered during data sorting is handling tied values—situations where two or more entries share the exact same numeric score or measurement. When standard sorting mechanisms are applied, these ties can lead to ambiguity or require manual intervention to ensure meaningful ranking integrity. Fortunately, Google Sheets provides specialized functions designed explicitly to resolve these ambiguities automatically, offering precise control over how tied data points are represented within a ranked list.
The primary tool for this purpose is the set of RANK functions. Understanding how these functions—specifically `RANK.EQ` and `RANK.AVG`—interpret and process tied scores is crucial for accurate analysis. Whether you need to assign the minimum rank (e.g., 1st place) to all tied entries, calculate a statistically representative average rank (e.g., 1.5th place), or even break the tie based on the order of entry, Google Sheets offers elegant formulaic solutions. Mastering these techniques ensures that your data organization accurately reflects the desired analytical outcome, transforming raw scores into meaningful hierarchical information within your spreadsheet environment.
Effective ranking often requires more than just assigning numbers; it demands thoughtful consideration of how shared positions should be treated. This guide delves into the three most effective methodologies for resolving ties in Google Sheets. We will explore the default behavior, the statistically sound average method, and an advanced technique combining the primary ranking function with the powerful COUNTIF function to establish definitive ordering even among identical scores. By the end of this tutorial, you will possess the expertise necessary to apply these complex ranking rules efficiently across any dataset.
Mastering Value Ranking with Ties in Google Sheets
When working with numerical data in a spreadsheet, the handling of duplicate values, or ties, is paramount to maintaining the integrity of your hierarchical analysis. Google Sheets provides distinct functions and formula structures that allow users to dictate precisely how these ties are managed. Depending on whether your goal is to replicate competitive ranking systems (where ties share the highest rank) or to provide a more statistically balanced average position, there are three primary, robust methods to achieve accurate results. Understanding the underlying logic of each approach is key to selecting the appropriate one for your specific data analysis needs.
These three methods rely fundamentally on the native Google Sheets ranking functions, specifically `RANK.EQ` (or the legacy `RANK`) and `RANK.AVG`. The critical distinction among the methods lies not just in the function used, but also in how auxiliary functions, like COUNTIF, can be integrated to introduce secondary sorting criteria, ensuring that every value, even those that are numerically identical, receives a unique position in the overall list if required. This versatility makes Google Sheets a powerful platform for complex data organization.
We will examine each technique, detailing the syntax and explaining the mathematical or logical outcome of its application. This provides a comprehensive framework for selecting the optimal tie-handling strategy, moving beyond simple ascending or descending sort orders to achieve true analytical precision in your datasets.
Method 1: Assign Highest Rank to Equal Values (RANK.EQ)
This methodology utilizes the standard, default behavior of the RANK function (which is synonymous with `RANK.EQ`). When two or more values are equal, this function assigns the highest possible rank among those tied positions to all of them. For instance, if the top two spots (ranks 1 and 2) are occupied by tied scores, both scores will be assigned rank 1, and the next unique score will start at rank 3. This approach is standard in competitive scenarios where sharing the highest possible achievement is the desired outcome.
The structure of this formula is the simplest, requiring only the value to be ranked and the range against which it is being compared. It is robust and straightforward, ideal for most basic ranking tasks where statistical averaging is not necessary. The primary goal here is clarity: identifying all entities that achieved a specific performance threshold and placing them equally at the top of the hierarchy.
The specific formula used below illustrates the application of this default mechanism across the specified data range. It automatically determines the highest rank available for the tied positions and applies it uniformly to all relevant cells.
=RANK(B2,$B$2:$B$11)
This particular formula will assign the same rank—the minimum rank number corresponding to the performance level—to equal values found within the absolute range B2:B11. Note the use of absolute references (the dollar signs, $) around the range, which is critical for ensuring the reference range remains fixed when the formula is copied down to other rows.
Method 2: Calculating Average Ranks for Ties (RANK.AVG)
In contrast to assigning the highest rank, the `RANK.AVG` function provides a statistically balanced approach to handling tied values. When this function encounters identical scores that would naturally occupy multiple sequential ranks (e.g., ranks 4, 5, and 6), it calculates the mathematical average of those ranks and assigns that mean value to all tied entries. In this example, the average of 4, 5, and 6 is 5; thus, all three tied scores would receive rank 5.
This method is particularly valuable in academic grading or analytical settings where the objective is to reflect the central tendency of the tied positions rather than merely their superiority. Using the average rank prevents an artificial inflation of the top ranks that can occur with the standard `RANK.EQ` method, providing a more granular and representative measure of performance relative to the entire dataset. While the resulting ranks may contain decimal values, they accurately represent the statistical position of the tied scores.
The syntax for `RANK.AVG` mirrors that of the standard ranking function, requiring only the value and the range. It is an extremely efficient built-in solution for achieving this specialized statistical result without needing to construct complex array formulas or conditional logic.
=RANK.AVG(B2,$B$2:$B$11)
This particular formula will assign the calculated average rank to equal values across the specified range B2:B11. This ensures that the collective position of the tied scores is represented accurately, bridging the gap between the lowest and highest ranks that the tied values would otherwise occupy individually.
Method 3: Resolving Ties Based on Appearance Order (RANK + COUNTIF)
The third method is arguably the most sophisticated, as it provides a mechanism to definitively break ties, ensuring that every data point, regardless of numerical similarity, receives a unique sequential rank. This is achieved by combining the standard RANK function with the powerful COUNTIF function. The combined formula first calculates the standard rank (assigning the same rank to ties) and then uses COUNTIF to introduce a small, variable offset based on the order in which the tied values appear in the list.
The core logic behind this advanced technique is to use COUNTIF on a dynamic, expanding range (e.g., `B$2:B2`) anchored at the start ($B$2). As the formula is copied down the column, the COUNTIF portion incrementally counts how many times the current value has already appeared up to that row. For the first instance of a tied value, COUNTIF returns 1. For the second instance, it returns 2, and so on. By adding this count and subtracting 1, we effectively ensure that the first occurrence retains the highest rank (Rank + 1 – 1 = Rank), while subsequent tied occurrences are demoted by one rank step (Rank + 2 – 1 = Rank + 1).
This approach is ideal for scenarios where a strict, non-fractional sequential ordering is required, such as allocating limited resources or determining priority based on entry order or submission time, even when the primary metric is identical. It transforms the result of the `RANK` function from one that tolerates ambiguity into one that demands precise sequence.
=RANK(B2,$B$2:$B$11)+COUNTIF(B$2:B2,B2)-1
This particular formula will assign the highest available rank to the value that appears first among two equal values in the range B2:B11. The subsequent tied value will then receive the next sequential rank, successfully breaking the tie based on physical list appearance.
Practical Application: Setting Up the Dataset
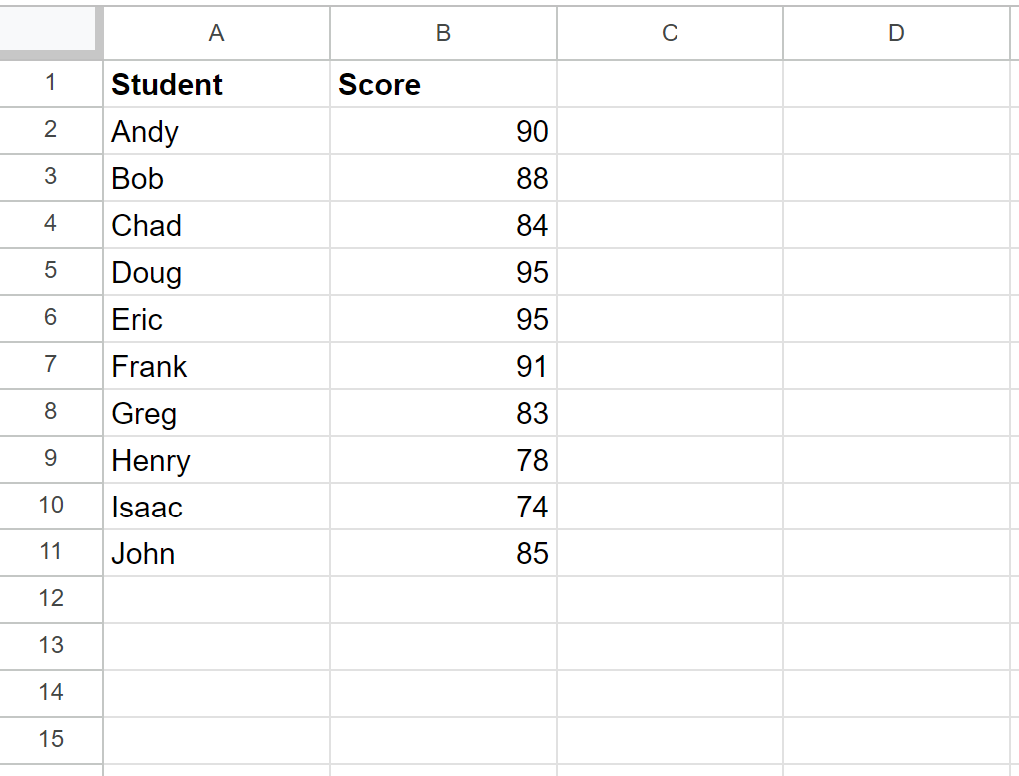
The preceding three methodologies demonstrate theoretical concepts; however, seeing them applied to a real-world dataset highlights their practical differences. For this example, we will use a common scenario: tracking student performance based on exam scores. Suppose we have a small dataset representing scores received by various students in a class. Our objective is to rank these scores from highest (rank 1) to lowest, while specifically observing how the different formulas manage the inevitable tied results.
To set up this demonstration in Google Sheets, we first establish two columns: Student Name and Exam Score. The raw data provides the basis for our analysis, and we will dedicate three additional columns—one for each ranking method—to display the comparative results side-by-side. This arrangement ensures a clear visual comparison of how each formula interprets the ties present in the score column.
Suppose we have the following dataset in Google Sheets that shows the exam scores received by various students:

Our goal is to assign a rank to each student based on their exam score, where the highest score receives rank 1 and the lowest score receives the highest rank number (in this case, 10, since there are 10 entries). This requires careful application of the respective formulas into the designated ranking columns (C, D, and E in our upcoming example).
Implementing the Three Ranking Formulas
To execute the ranking process, we must input the specific formula for each method into the first row of our ranking columns (C2, D2, and E2) and then drag them down to apply the calculation across the entire range (up to row 11). Since we are ranking the scores in column B, all formulas will reference B2 as the initial comparison value and B$2:B$11 as the absolute reference range.
The consistency in the reference structure is essential. The use of absolute references (using $) for the range ensures that as the formula is copied down, every individual score is compared against the exact same set of 10 scores, preventing calculation errors that arise from shifting reference ranges.
We can type the following formulas into cells C2, D2, and E2 to apply the three different ranking methods:
- C2: =RANK(B2,$B$2:$B$11) – Utilizes the default method (Method 1).
- D2: =RANK.AVG(B2, $B$2:$B$11) – Utilizes the average rank method (Method 2).
- E2: =RANK(B2,$B$2:$B$11)+COUNTIF(B$2:B2,B2)-1 – Utilizes the tie-breaking sequential method (Method 3).
Upon successful implementation and replication of the formulas, the resulting spreadsheet will display the ranks calculated by each method, providing a direct comparative view of how the various tie-handling protocols impact the overall list hierarchy.

Analyzing the Tie Resolution Outcomes
Observing the results, a clear instance of a tie exists: students Doug and Eric both achieved an exam score of 95. Since 95 is the highest score in the dataset, this tie directly impacts the assignment of ranks 1 and 2. The subsequent ranks (starting from 3) are assigned to the student with the next highest unique score, 90. Analyzing columns C, D, and E reveals precisely how each method navigated this specific tie.
Here is how each ranking method handled this critical tie:
Method 1: RANK (Column C)
This method assigned the highest possible available rank—in this case, 1—to both tied values. Ranks 1 and 2 were technically occupied by the score of 95, but the default `RANK` function always reports the lowest numerical rank (highest position). Consequently, both Doug and Eric share the rank of 1, and the next unique score (90) correctly begins the sequence at rank 3, skipping the rank 2 slot. This is standard competitive ranking behavior.
Method 2: RANK.AVG (Column D)
The `RANK.AVG` method performed a statistical calculation. Since the two scores of 95 occupied the potential ranks 1 and 2, the function averaged these two positions: (1 + 2) / 2 = 1.5. Both Doug and Eric were assigned a rank of 1.5. This approach ensures that the total sum of ranks remains consistent with a non-tied list, fulfilling a crucial statistical requirement. The ranks then proceed sequentially from the next available integer rank, with the score of 90 correctly receiving rank 3.
Method 3: RANK + COUNTIF (Column E)
This method enforced a strict sequential order by leveraging the COUNTIF addition. This ensured that the score belonging to the student who appeared first in the dataset received the highest rank. Since Doug appeared before Eric in the original list, Doug received the rank of 1, and Eric, despite having the exact same score, was assigned rank 2. This successfully breaks the tie based on row position, maintaining an unbroken numerical sequence.
Selecting the Appropriate Ranking Strategy
Choosing the correct ranking method depends entirely on the context and the analytical goal of the spreadsheet. If the data represents a competition where shared first place is acceptable and desirable, such as recognizing all record holders, Method 1 (`RANK.EQ`) is the most appropriate choice. It clearly identifies all top performers without imposing artificial differentiation.
Conversely, if the ranking is part of a larger statistical model or requires fine-grained analysis where the average positional weight is important, Method 2 (`RANK.AVG`) should be used. While the ranks are fractional, they adhere strictly to statistical principles, ensuring that the mean rank position is accurately reflected. This is often preferred in research and academic scoring systems where the distortion caused by skipping ranks must be minimized.
Finally, Method 3 (the combination of RANK and COUNTIF) is reserved for scenarios that demand absolute uniqueness in ranking, even among tied scores. If the dataset requires a deterministic sequence—perhaps for sequential processing, prioritizing based on entry time, or generating a unique leader board—this method provides the necessary tie-breaking mechanism. It ensures a seamless 1-to-N ranking without any fractional or duplicate ranks.
Conclusion: Mastering Tie Resolution in Spreadsheets
Handling tied values is a crucial skill for advanced data analysis in Google Sheets. By utilizing the versatile `RANK` function family, users are empowered to define precisely how duplicate scores affect the hierarchy of their data. Whether the requirement is to assign the highest rank to all tied values, calculate a precise average rank, or enforce strict sequential ordering based on appearance, Google Sheets provides efficient and easy-to-implement formulaic solutions.
The key takeaway is that the choice between `RANK.EQ`, `RANK.AVG`, and the combined `RANK + COUNTIF` formula dictates the interpretation of the dataset. Careful selection of the appropriate function ensures that the final ranked output aligns perfectly with the intended analytical goal, moving beyond simple data sorting to provide meaningful, context-specific performance hierarchies. Mastering these techniques transforms the way data is managed and interpreted within the spreadsheet environment.
The following tutorials explain how to perform other common tasks in Google Sheets, building upon this foundational understanding of advanced formula application:
Cite this article
stats writer (2026). How to Rank Values with Ties in Google Sheets Easily. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-do-i-rank-values-with-ties-in-google-sheets/
stats writer. "How to Rank Values with Ties in Google Sheets Easily." PSYCHOLOGICAL SCALES, 31 Jan. 2026, https://scales.arabpsychology.com/stats/how-do-i-rank-values-with-ties-in-google-sheets/.
stats writer. "How to Rank Values with Ties in Google Sheets Easily." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-do-i-rank-values-with-ties-in-google-sheets/.
stats writer (2026) 'How to Rank Values with Ties in Google Sheets Easily', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-do-i-rank-values-with-ties-in-google-sheets/.
[1] stats writer, "How to Rank Values with Ties in Google Sheets Easily," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, January, 2026.
stats writer. How to Rank Values with Ties in Google Sheets Easily. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.
Comments are closed.