Table of Contents
When visualizing data using a histogram, one of the most critical decisions is defining the appropriate number of bins. Bins determine how the continuous data is aggregated into discrete intervals, directly influencing the resulting visualization’s shape and interpretability. To effectively control this aggregation in the Pandas library, users must employ the hist() function‘s dedicated parameter: ‘bins’. This parameter accepts either an integer, specifying the exact count of bins, or an array-like sequence, which defines the specific bin edges.
The choice of bin count fundamentally affects the visualization’s granularity. A higher number of bins segments the data into smaller intervals, leading to a highly detailed, often jagged histogram that may highlight subtle variations but can sometimes exaggerate noise. Conversely, selecting a lower number of bins results in wider intervals, producing a smoother, coarser histogram that provides a high-level overview of the central tendency and overall spread, potentially obscuring fine-grained features or underlying structure in the data. Understanding this trade-off is essential for accurate exploratory data analysis.
Understanding the Role of Bins in Histograms
The primary purpose of a histogram is to represent the distribution of numerical data. It accomplishes this by partitioning the entire range of values into a series of intervals, or bins, and then counting how many values fall into each interval. The height of each bar is proportional to the frequency of data points within that specific bin. If the bin size is too small, the histogram might look sparse and spiky; if the bin size is too large, the histogram might fail to reveal the true shape of the distribution, potentially masking multiple modes or skewness in the underlying structure.
In the context of statistical visualization using Python’s data stack, Pandas offers convenient wrappers built on top of Matplotlib for generating these plots directly from a DataFrame or Series. Utilizing the bins argument is the standard procedure for customizing this partitioning process, allowing analysts to iterate on different views until the most informative visualization is achieved. By default, Pandas often selects a reasonable starting point, usually 10 bins, but this default is rarely optimal for all datasets, necessitating manual adjustment.
The ‘bins’ Parameter in the Pandas hist() Function
To explicitly modify the number of bins used in a Pandas histogram, the bins argument must be passed to the plot.hist() method or the standalone df.hist() method. This parameter is integral to controlling the resulting visualization. The simplest and most common approach involves passing a single positive integer, which instructs Pandas to divide the entire data range into that exact number of equally sized intervals. This overrides the library’s internal calculation methods, giving the user direct control over the aggregation level.
For example, if you wish to see a quick visualization of a column named ‘my_column’ using a specific bin count, the implementation is straightforward. Although 10 is the library’s default, the code snippet below explicitly demonstrates how to call the function and set the bins parameter to this baseline value for illustrative purposes, confirming the syntax required for adjustment:
You can use the bins argument to modify the number of bins used in a pandas histogram:
df.plot.hist(columns=['my_column'], bins=10)
While the previous example explicitly sets the bin count to 10, it is crucial to remember that this count represents the standard default behavior when the bins parameter is omitted entirely. Understanding this default baseline is key before experimenting with different values, as the choice of bin count directly impacts how data variance is perceived. We will now proceed with a practical demonstration involving a sample dataset to clearly illustrate the visual impact of manipulating this parameter.
Initial Setup: Preparing the Sample Pandas DataFrame
To provide a concrete illustration of bin manipulation, we will first generate a sample DataFrame. This DataFrame simulates a common scenario in sports analytics, containing information about points scored by fictional basketball players across various teams. This synthetic data allows us to control the underlying distribution, ensuring our visualization examples are predictable and easy to follow. We rely heavily on the NumPy library for efficient generation of normally distributed random data, mirroring continuous variables often encountered in real-world statistical analysis.
The following initialization script sets a seed for reproducibility, constructs the DataFrame, and provides a quick look at the first few rows to confirm the structure. The ‘points’ column, which we will analyze, follows a normal distribution centered around a mean score of 20, making it an excellent candidate for demonstrating how different bin counts reveal or hide characteristic statistical shapes:
import pandas as pd import numpy as np #make this example reproducible np.random.seed(1) #create DataFrame df = pd.DataFrame({'team': np.repeat(['A', 'B', 'C'], 100), 'points': np.random.normal(loc=20, scale=2, size=300)}) #view head of DataFrame print(df.head()) team points 0 A 23.248691 1 A 18.776487 2 A 18.943656 3 A 17.854063 4 A 21.730815
This initialization generates 300 data points across three teams. The subsequent analysis will focus exclusively on the continuous variable, points, aiming to visualize its frequency distribution across the dataset using the hist() function. The fixed data ensures that the observed changes in the histograms are solely due to the manipulation of the bins parameter, allowing for a clear, apples-to-apples comparison of the effects of bin count.
Visualizing Data with the Default Number of Bins (10)
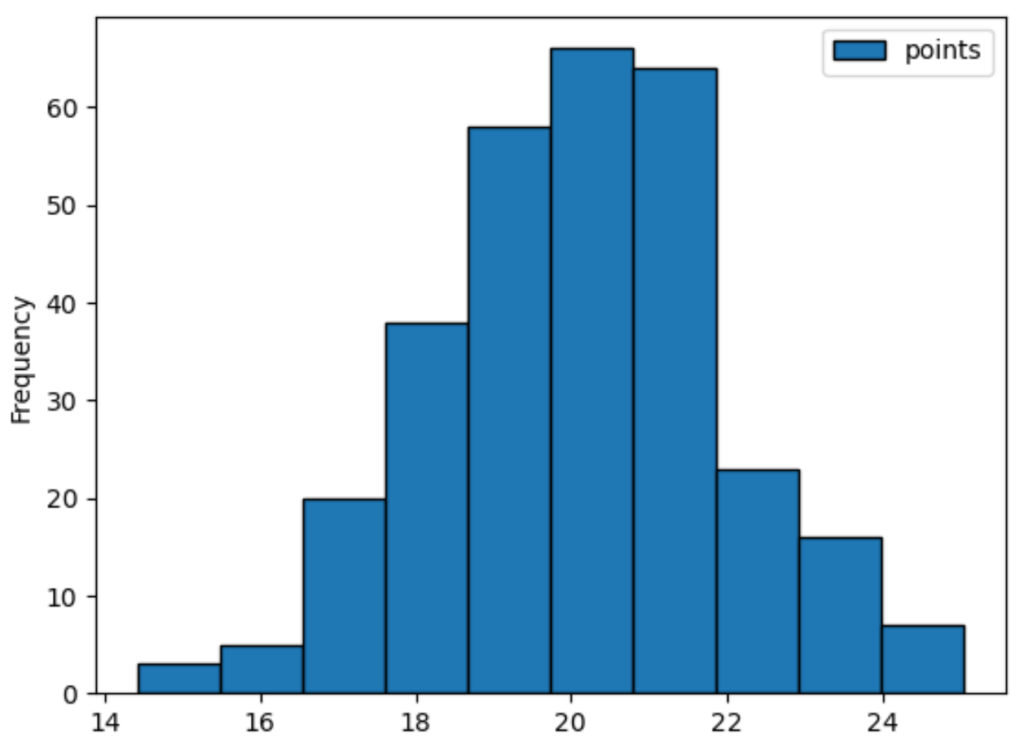
When we first attempt to visualize the frequency distribution of the points variable without explicitly specifying the bins parameter, Pandas automatically defaults to using 10 bins. This default setting is generally based on heuristics designed to provide a reasonable balance for many standard datasets, minimizing both over-smoothing and excessive noise. The following code executes this initial visualization, adding an edgecolor='black' parameter simply to enhance the visual separation between the bars for clearer interpretation.
#create histogram to visualize distribution of points
df.plot.hist(column=['points'], edgecolor='black')
Executing this command generates the baseline histogram. If you carefully examine the generated plot below, you will confirm that the visualization consists of exactly 10 distinct bars. Each bar represents an equal interval of the ‘points’ range, summarizing the frequency of scores that fall within that specific band. This visual representation serves as the benchmark against which changes introduced by modifying the bins parameter will be measured.

This default view provides a good initial estimate of the data’s central tendency and overall shape, clearly indicating that the points are clustered around the mean, characteristic of a normal distribution. However, this level of aggregation might mask certain features, especially if the data were less perfectly Gaussian, leading us to investigate the effects of increasing the bin count for greater resolution.
Increasing Granularity: Using More Bins for Detailed Distribution Analysis
To investigate the data distribution with greater detail, we can double the number of intervals by explicitly setting the bins parameter to 20. Increasing the bin count significantly reduces the width of each bin, thus making the visualization far more granular. This technique is particularly valuable when we suspect that the default 10 bins may be smoothing over important, localized details, such as subtle shifts in density or minor peaks within the core data cluster.
By executing the histogram plot with bins=20, we instruct Pandas to create 20 segments across the same range of point scores. The resulting histogram will consequently appear much more jagged and varied than the default version, reflecting the lower frequency counts captured within these smaller intervals. This change allows for a more minute examination of where the scores concentrate along the continuum.
#create histogram with 20 bins
df.plot.hist(column=['points'], edgecolor='black', bins=20)Observe the transformation in the resulting visualization below. We now clearly see 20 bars, confirming the increased granularity achieved by narrowing the bin widths. While the overall bell-curve shape remains evident, the added detail reveals more jaggedness. This higher resolution view can be highly beneficial for precise analysis of the data’s density at specific score ranges, provided this detail represents true data features rather than random sampling noise.

The decision to increase the number of bins should always be driven by the need to reveal finer details of the underlying distribution without succumbing to over-fitting. For normally distributed data like this, excessive bins may just introduce visual clutter, but in more complex datasets, this method is crucial for discovering underlying multimodal structures.
Reducing Granularity: Using Fewer Bins for Summary Visualization
Alternatively, we might prioritize focusing on the macro features of the distribution, intentionally smoothing out local variations to highlight the core trend. This is accomplished by significantly decreasing the number of bins, resulting in wider intervals and a coarser, more abstract histogram. For our example, if we set the bins parameter to 5, we are effectively summarizing the data into five large frequency categories. This highly aggregated approach is often ideal for communicating the primary shape of the data to a general audience, where excessive detail might be counterproductive.
By reducing the bin count, we consolidate data points, making the bars taller (as they represent a much larger frequency count) and fewer in number. This emphasis on mass aggregation helps to quickly identify the major clusters and the overall symmetry or skewness of the dataset without dwelling on minor, noisy fluctuations. This provides a robust, high-level summary.
#create histogram with 5 bins
df.plot.hist(column=['points'], edgecolor='black', bins=5)The result of this decreased bin count is immediately apparent in the plot below. With only 5 bars, the visualization is significantly smoother. It clearly highlights the central peak around the mean but obscures most of the variation seen in the 10-bin or 20-bin versions. While this high degree of aggregation is excellent for providing a generalized view, analysts must be cautious not to eliminate structural features essential for accurate interpretation.

Advanced Bin Specification: Defining Custom Edges
While providing an integer for the bins argument is the most common method, Pandas offers greater flexibility by permitting the passing of an array or list of values. If an array is provided to the hist() function, these values are interpreted as the specific edges where the bins should start and end, allowing for the creation of intervals that are not necessarily of equal width. This advanced technique is crucial when domain knowledge dictates specific, unequal thresholds or categories that the data must adhere to, such as predefined salary brackets or age groups in demographic studies.
This control allows the analyst to align the visualization directly with real-world segmentation rules. For instance, an analyst might define custom bin edges like bins=[15, 18, 20, 22, 25]. This would result in four unequal bins: 15 to 18, 18 to 20, 20 to 22, and 22 to 25. This granular control ensures that the histogram aligns perfectly with established metrics or categorical requirements within the data domain, overriding the automatic, equal-width interval calculation performed by the visualization library.
Practical Considerations for Optimal Bin Selection
Choosing the optimal number of bins is arguably the most subjective step in creating a histogram, often requiring iterative testing coupled with expert statistical judgment. However, there are established guidelines and statistical rules designed to provide a mathematically sound starting point for bin selection, helping to move the process away from pure guesswork. A poorly chosen bin quantity can lead to significant misinterpretation, either by over-smoothing the data and hiding essential patterns or by over-detailing it and focusing heavily on statistical noise.
As a general rule, keep the following critical considerations in mind when determining the optimal value for the bins argument:
- Risk of Over-Smoothing: If you choose too few bins, the true underlying pattern, such as bimodality or significant skewness in the data, may be entirely hidden. The histogram will appear overly blocky and simplistic, failing to convey the nuances of the population distribution effectively.
- Risk of Noise Visualization: Conversely, if you choose too many bins, the visualization becomes highly fragmented and sparse. You may end up primarily visualizing the inherent statistical noise or random sampling variability rather than the stable, underlying structure of the data’s distribution.
One helpful way to determine a statistically robust number of bins is to utilize established statistical rules, such as Sturges’ formula, the Freedman-Diaconis rule (FD), or Scott’s rule. These formulas calculate an objective bin width based on the dataset size and variability, often yielding a more appropriate number than the fixed default of 10. Modern Pandas plotting functions can automatically implement these rules by passing specific string arguments (e.g., bins='auto' or bins='fd'), but understanding the manual integer adjustment via the bins parameter remains foundational for custom analysis and fine-tuning.
Cite this article
stats writer (2025). How to Customize Histogram Bin Count in Pandas. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-do-i-change-the-number-of-bins-used-in-a-pandas-histogram/
stats writer. "How to Customize Histogram Bin Count in Pandas." PSYCHOLOGICAL SCALES, 21 Nov. 2025, https://scales.arabpsychology.com/stats/how-do-i-change-the-number-of-bins-used-in-a-pandas-histogram/.
stats writer. "How to Customize Histogram Bin Count in Pandas." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/how-do-i-change-the-number-of-bins-used-in-a-pandas-histogram/.
stats writer (2025) 'How to Customize Histogram Bin Count in Pandas', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-do-i-change-the-number-of-bins-used-in-a-pandas-histogram/.
[1] stats writer, "How to Customize Histogram Bin Count in Pandas," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, November, 2025.
stats writer. How to Customize Histogram Bin Count in Pandas. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.