Table of Contents
The Vital Role of Unique Identifiers in Modern Data Management
In the contemporary landscape of data analysis and information architecture, the ability to distinguish individual records within a vast dataset is paramount. A unique identifier, often referred to as a Primary Key in the context of relational databases, serves as a distinct label that ensures no two entries are confused. Within Microsoft Excel, generating these identifiers is not merely a matter of convenience but a fundamental practice for maintaining data integrity. Without a structured approach to identification, datasets become prone to errors, such as double-counting or the incorrect attribution of attributes to entities. By establishing a robust system for unique IDs, users can streamline their workflows and facilitate more complex operations like data merging and pivot table analysis.
The utility of unique identifiers extends across various professional domains, ranging from inventory management to human resources and academic research. In a spreadsheet, an identifier might represent a specific transaction, a unique customer, or, as seen in our practical example, a specific sports team. Utilizing Excel formulas to automate this process reduces the human error inherent in manual entry. Furthermore, these identifiers allow for the seamless integration of disparate data sources. When every row possesses a unique, immutable reference point, VLOOKUP and XLOOKUP functions become significantly more reliable, ensuring that the retrieval of information is both accurate and efficient.
Generating unique identifiers in Excel can be approached through several methodologies, depending on the specific requirements of the project. One sophisticated method involves the use of specialized functions or custom logic to create a 12-character alphanumeric string. This high-entropy approach ensures that the risk of collision—where two different entries are assigned the same ID—is virtually non-existent. Such identifiers are particularly useful for creating invoice numbers, tracking shipments, or managing digital assets. By leveraging the power of Excel’s calculation engine, users can transform a simple list into a structured database environment, fostering better data governance and long-term scalability.
Understanding the Logical Foundation of Identifier Generation
Before diving into the technical implementation, it is essential to understand the logic that governs the creation of unique IDs. At its core, an identifier must be unique within its scope. In some instances, you may require a simple sequential number, while in others, you might need a composite key that combines text strings with numeric values. Boolean logic plays a critical role here, as formulas must often check whether a value has appeared previously in a list before deciding whether to assign a new ID or repeat an existing one. This conditional logic is what allows Excel to behave dynamically, adjusting the output as new data is appended to the worksheet.
The process often involves a combination of lookup functions and logical tests. For example, the MATCH function is frequently employed to determine the position of an item within a range. When combined with the ISNA function, it can identify “new” items that have not yet been categorized. This synergy of functions allows for the creation of a dynamic array of identifiers that grow alongside your data. Understanding these underlying mechanics empowers users to troubleshoot their formulas and adapt them to unique business cases, such as handling case-sensitive data or ignoring whitespace during the identification process.
Moreover, the choice between numeric and alphanumeric identifiers often depends on the intended user interface and the software that will consume the data. Numeric IDs are computationally efficient and ideal for internal data processing. Conversely, alphanumeric IDs, which might include prefixes or dates, provide more context to the human observer and are often used in project management. By mastering the syntax of these complex formulas, an Excel user transitions from a basic data entry clerk to a proficient data architect, capable of building resilient systems that stand the test of time and volume.
Step-by-Step Implementation of Numeric Unique IDs
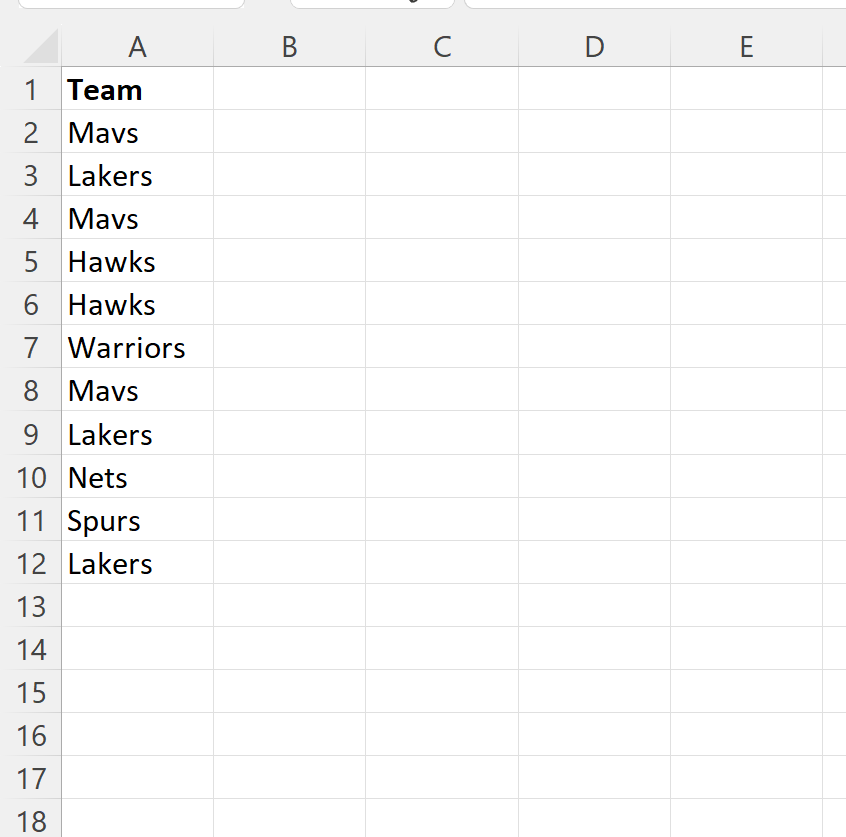
Often you may want to generate unique identifiers for values in a dataset in Excel. This is particularly common when you have repeating categories and you wish to assign a consistent number to each category. By doing so, you create a mapping that allows for easier statistical analysis and data visualization. The following example shows exactly how to do so, utilizing a list of basketball teams to demonstrate the practical application of these logical formulas.
Suppose we have the following list of basketball team names in Excel, where several team names repeat throughout the column:

Suppose we would like to create a unique identifier value for each team. In this scenario, every instance of “Mavs” should receive the same ID, while “Lakers” should receive a different, unique ID. To begin this process, we can choose the first unique identifier to be any value we’d like. Setting a starting point provides the algorithm with a baseline for its subsequent calculations. For example, we could use the value 1 for the first team listed in our data range:

Next, we need a formula that can look at the current team name and determine if it has appeared earlier in the list. If it has, the formula should retrieve the existing ID. If it has not, it should increment the maximum current ID by one. We can type the following formula into cell B3 to initiate this conditional logic:
=IF(ISNA(MATCH(A3,A2:$A$2,0)),MAX(B2:$B$2)+1,VLOOKUP(A3,A2:$B$2,2,FALSE))
We can then click and drag this formula down to each remaining cell in column B. This action utilizes relative references and absolute references (denoted by the dollar signs) to ensure the search range expands as the formula is copied downward. This ensures that every row is evaluated against all preceding rows, maintaining the uniqueness of the generated IDs throughout the entire dataset.

Analyzing the Mechanics of the Match and Lookup Formula
The formula used in the previous section is a powerful example of nested functions in Excel. To truly master data manipulation, one must understand how these components interact. The IF function acts as the primary decision-maker. It first checks a condition: ISNA(MATCH(…)). The MATCH function searches for the current team name in the range of cells above it. If the name is not found, MATCH returns an #N/A error. The ISNA function catches this error and returns TRUE, signaling to the IF function that this is a new, unique entry that requires a new identifier.
When a new entry is detected, the formula executes MAX(B2:$B$2)+1. This takes the highest number found in the ID column so far and adds one to it, ensuring a sequential and unique number. This is a classic technique in computer science for generating auto-incrementing keys. By anchoring the start of the range with a dollar sign (e.g., $B$2), we ensure that Excel always looks from the very top of the list down to the cell immediately above the current one, providing a comprehensive audit trail of previously assigned numbers.
Conversely, if the team name is found (meaning MATCH does not return an error), the formula executes the VLOOKUP function. This function searches the preceding rows for the team name and returns the ID that was previously assigned to it. The use of FALSE as the final argument in VLOOKUP is crucial, as it forces an exact match. This logic ensures that “Lakers” will always be 2 and “Mavs” will always be 1, regardless of how many times they appear in the spreadsheet. This consistency is the hallmark of high-quality data management.
Creating Alphanumeric Identifiers for Enhanced Categorization
While sequential numbers are effective, there are many scenarios where an alphanumeric identifier is more appropriate. These IDs often incorporate parts of the original data, making them more descriptive and easier for humans to parse at a glance. For instance, in a logistics or inventory system, an ID might combine a product category code with a unique sequence number. This creates a hierarchical identification system that can be sorted and filtered more intuitively than simple integers. Excel provides a variety of text functions that facilitate the creation of these complex strings.
In the following approach, we combine the LEFT function with the COUNTIF function to generate a unique ID for every single row, even if the team names repeat. This is useful for tracking specific occurrences or iterations of an event. For example, instead of just identifying the team, we are identifying the “first time the Mavs appear,” the “second time the Mavs appear,” and so on. This level of granularity is vital for time-series analysis or event logging. The formula for this method is as follows:
=LEFT(A2,3)&"-"&COUNTIF($A$2:A2,A2)*1
This formula utilizes the ampersand (&), which is the concatenation operator in Excel. It joins different pieces of data together into a single string. By taking the first three characters of the team name and appending a hyphen and a count, we create a distinct serial number for every record. You can then click and drag this formula down to each remaining cell in column B to apply the logic to the entire list of teams:

Column B now contains a unique ID for each row, providing a traceable and descriptive index. As seen in the results, the first instance of “Mavs” becomes “Mav-1”, while the second instance becomes “Mav-2”. This method is highly effective for auditing and ensures that every single entry in your workbook has a one-of-a-kind signature that can be referenced in future data processing tasks.
Deep Dive into String Concatenation and Conditional Counting
The beauty of the alphanumeric approach lies in its versatility. The LEFT function is a string manipulation tool that extracts a specified number of characters from the start of a text string. In our example, LEFT(A2, 3) takes the first three letters of the team name. This provides an immediate visual cue about the data the ID represents. In professional environments, these prefixes are often standardized into taxonomies, ensuring that all metadata follows a consistent format across different departments or software systems.
The COUNTIF function serves as the engine for uniqueness in this formula. By using a mixed reference—$A$2:A2—we create a “running count.” As the formula is dragged down, the start of the range remains fixed at the top, but the end of the range moves with the row. This allows Excel to count how many times the specific team name has appeared from the beginning of the list up to the current line. It is a brilliant way to handle duplicates by turning them into unique sub-entries, effectively creating a version control system within a single column.
Combining these elements with a separator, such as a hyphen or underscore, improves readability. This practice is common in coding and database design to prevent ambiguity. By multiplying the COUNTIF result by 1, we ensure that Excel treats the result as a number, though in the context of concatenation, Excel is usually smart enough to handle type conversion automatically. This formula structure is a staple for those working with big data in Excel, as it provides a way to generate unique keys without needing complex VBA (Visual Basic for Applications) scripts or Power Query transformations.
Ensuring Data Integrity and Avoiding Collision in Large Spreadsheets
As datasets grow in size and complexity, the risk of data collision or formula slowdown increases. In a spreadsheet with tens of thousands of rows, complex lookup formulas can lead to significant latency because Excel must recalculate the ranges every time a change is made. To mitigate this, it is often recommended to “freeze” identifiers once they have been generated. This can be done by copying the generated IDs and using Paste Special > Values. This converts the dynamic formula into a static string or number, protecting the primary key from accidental changes if the source data is sorted or modified.
Another aspect of data integrity is ensuring that the identifiers remain immutable. In database theory, a primary key should ideally never change. If you base your unique ID on a team name and that team name is later corrected for a typo, a dynamic formula will change the ID, potentially breaking links in other parts of your workbook. Therefore, it is vital to decide early in the data modeling phase whether your IDs should be deterministic (based on the data) or surrogate (randomly generated or sequential). Both have their merits, but surrogate keys are generally more resilient to changes in the underlying attributes.
Finally, users should be aware of the limitations of Excel regarding calculation modes. In very large files, users might switch to Manual Calculation mode to save time. If this is the case, the unique ID formulas will not update until the user triggers a recalculation (usually by pressing F9). Understanding these operational nuances is essential for anyone acting as a data steward. By combining robust formula logic with sound administrative practices, you can ensure that your Excel projects remain accurate, professional, and ready for high-level business intelligence applications.
Future-Proofing Your Excel Data Structures
Generating unique identifiers is just the first step in creating a scalable data solution. As you become more comfortable with these techniques, you may want to explore Power Query (also known as Get & Transform), which offers a dedicated “Index Column” feature. This tool is specifically designed to handle large-scale data preparation and can generate unique IDs much more efficiently than standard worksheet formulas. Power Query also records the steps of your data transformation, providing an automated and repeatable process for future data imports.
Additionally, for those working in the Office 365 ecosystem, the introduction of dynamic array functions like UNIQUE and SEQUENCE has revolutionized how we handle distinct values. While the traditional MATCH and VLOOKUP methods remain highly relevant for backwards compatibility and specific logic, the newer functions allow for much cleaner syntax and spilled array behavior. Staying updated with the latest Excel updates ensures that your skills remain competitive and your spreadsheets remain optimized for performance.
In conclusion, whether you choose a numeric sequential approach or a descriptive alphanumeric method, the goal remains the same: to provide a solid foundation for your data. By implementing these unique identifiers, you are not just organizing a list; you are building a relational structure that can support advanced data analytics, automation, and reporting. The following tutorials explain how to perform other common tasks in Excel, further expanding your toolkit for data mastery:
- How to Remove Duplicates in Excel
- How to Use VLOOKUP with Multiple Criteria
- Advanced Data Cleaning Techniques in Power Query
- Creating Dynamic Named Ranges for Better Formulas
Cite this article
stats writer (2026). How to Generate Unique IDs in Excel Easily. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-can-i-generate-unique-identifiers-in-excel/
stats writer. "How to Generate Unique IDs in Excel Easily." PSYCHOLOGICAL SCALES, 25 Feb. 2026, https://scales.arabpsychology.com/stats/how-can-i-generate-unique-identifiers-in-excel/.
stats writer. "How to Generate Unique IDs in Excel Easily." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-can-i-generate-unique-identifiers-in-excel/.
stats writer (2026) 'How to Generate Unique IDs in Excel Easily', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-can-i-generate-unique-identifiers-in-excel/.
[1] stats writer, "How to Generate Unique IDs in Excel Easily," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, February, 2026.
stats writer. How to Generate Unique IDs in Excel Easily. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.