Table of Contents
The Theoretical Foundation of Fisher’s Exact Test
Fisher’s Exact Test is a sophisticated statistical procedure used to determine if there are non-random associations between two categorical variables. Named after the eminent statistician Sir Ronald Fisher, this test is uniquely powerful because it provides an exact p-value, rather than an approximation. While many researchers rely on the Chi-Square Test for large datasets, the Fisher’s Exact Test is the gold standard when dealing with small sample sizes or sparse data where the assumptions of larger tests are violated. It is fundamentally built upon the principles of the hypergeometric distribution, allowing it to calculate the precise probability of observing a specific distribution of data points within a contingency table.
In the realm of research and clinical trials, the necessity for such a test arises when the expected frequencies in any given cell of a data table are low. Traditionally, when one or more cells in a 2×2 table have an expected frequency of less than five, the Chi-Square Test of Independence loses its accuracy. In these instances, Fisher’s Exact Test becomes indispensable, providing a rigorous mathematical framework to assess the null hypothesis. This hypothesis typically posits that no association exists between the variables under study, and the test seeks to determine if the observed data deviates enough from this assumption to be considered statistically significant.
The application of this test is particularly prevalent in fields like medicine, genetics, and the social sciences, where obtaining large sample sizes can be either ethically challenging or prohibitively expensive. By utilizing this method, researchers can maintain high standards of statistical significance without the need for thousands of observations. Understanding the underlying mechanics of how Fisher’s Exact Test operates is the first step toward conducting robust data analysis within professional software environments like Microsoft Excel.
Distinguishing Fisher’s Exact Test from the Chi-Square Method
Choosing the correct statistical tool is paramount for the validity of any analytical conclusion. The primary distinction between the Chi-Square Test and Fisher’s Exact Test lies in the sample size and the way p-values are derived. The Chi-Square method is a “large-sample” test that relies on an approximation of the distribution. As the sample size grows, this approximation becomes increasingly accurate. However, for small datasets, the approximation can lead to “Type I” errors, where a researcher might incorrectly reject a true null hypothesis.
Conversely, Fisher’s Exact Test does not rely on such approximations. It calculates the exact probability of the observed configuration of the contingency table, as well as all other configurations that would be more extreme under the null hypothesis. This makes it an “exact” test. Because it accounts for every possible permutation of the data given the marginal totals of the table, it remains reliable even when the total sample size is extremely small, such as the 25-person sample size often seen in preliminary pilot studies.
In Excel, while there isn’t a single “one-click” native button for Fisher’s Exact Test in the same way there is for an average or sum, the software’s mathematical functions allow for a manual yet precise execution. By understanding that the test is an alternative to the Chi-Square Test, users can better justify their choice of methodology in technical reports and academic papers. This distinction ensures that the statistical significance reported is both accurate and appropriate for the data’s scale.
Structural Requirements: Designing the 2×2 Contingency Table
Before any calculations can begin in Excel, the data must be meticulously organized into a contingency table. This structure, often referred to as a cross-tabulation, displays the frequency distribution of the variables. For Fisher’s Exact Test, the most common format is a 2×2 table, which compares two categorical variables, each having exactly two levels or categories. For example, one variable might be “Gender” (Male/Female) and the other might be “Preference” (Choice A/Choice B).
In an Excel worksheet, this table should be laid out so that the rows represent one variable and the columns represent the other. The intersections of these rows and columns, known as cells, contain the counts of individuals or items that fall into both categories. It is vital to include the row totals, column totals, and the overall grand total, as these values (known as marginal totals) are critical inputs for the mathematical functions that follow. Accuracy at this stage is essential; a single miscounted entry will skew the final p-value and lead to erroneous conclusions.
Properly labeling your table within Excel not only helps in the calculation phase but also ensures the data is interpretable for stakeholders. Using clear headers for each row and column allows the contingency table to serve as a standalone summary of the raw data. Once the frequencies are entered, the researcher can visualize the distribution and begin to suspect whether an association exists before even running the formal test. This preliminary visual check is a hallmark of diligent data analysis.
Utilizing the Hypergeometric Distribution for Statistical Analysis
While some statistical packages offer a dedicated command for Fisher’s Exact Test, Excel users typically leverage the HYPGEOM.DIST function to achieve the same result. The hypergeometric distribution is the mathematical engine behind the test, modeling the probability of a specific number of successes in a sequence of draws from a finite population without replacement. This aligns perfectly with the logic of the test, where we assume the marginal totals of our contingency table are fixed.
The HYPGEOM.DIST function in Excel requires five specific arguments to return the correct probability. These include the number of successes in the sample, the size of the sample, the number of successes in the population, the size of the population, and a boolean value for cumulative distribution. Understanding how to map the values from your 2×2 contingency table to these arguments is the most technical aspect of performing the test manually. When configured correctly, the function evaluates the likelihood of the observed data occurring by chance.
The power of the hypergeometric distribution lies in its precision. Unlike normal or binomial distributions, which may assume an infinite population or replacement, the hypergeometric model respects the constraints of a small, fixed dataset. This ensures that the resulting p-value is “exact.” By mastering this function, Excel users can perform high-level statistical testing that rivals specialized software like SPSS or R, making it a versatile tool for any data scientist’s arsenal.
A Practical Demonstration: Gender and Political Preference
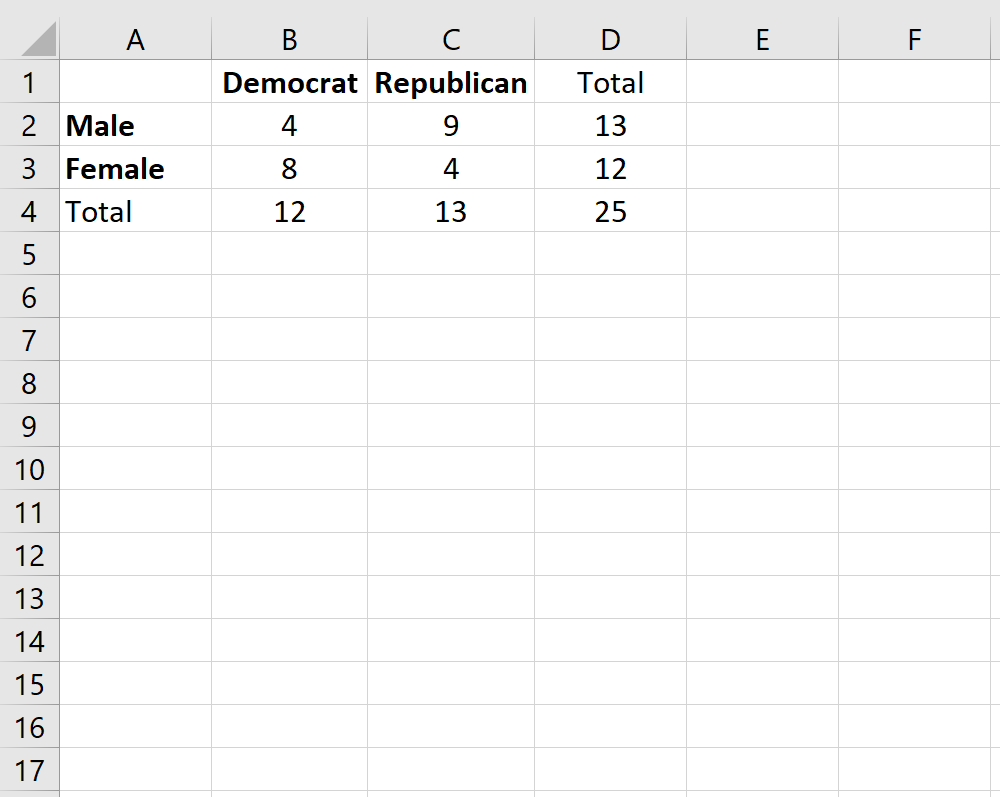
To illustrate the application of Fisher’s Exact Test, let us consider a study exploring the relationship between gender and political party preference. Suppose a researcher randomly polls 25 students at a college to see if there is an association between being Male or Female and identifying as a Democrat or a Republican. Given the small sample size of 25, a Chi-Square Test would be inappropriate, making this the perfect scenario for Fisher’s methodology. The observed frequencies are recorded in the table below:

In this example, the contingency table shows 4 female Democrats and 8 female Republicans, alongside 9 male Democrats and 4 male Republicans. The marginal totals reveal a total of 12 females, 13 males, 13 Democrats, and 12 Republicans. Our goal is to determine if the distribution of political preference differs significantly between genders or if the observed differences are merely the result of random sampling variation. This requires us to test the null hypothesis, which states that gender and political affiliation are independent.
By framing the problem this way, we can see how the variables are partitioned. We will select one cell to represent our “successes” in the hypergeometric distribution. In this case, we might choose the count of female Democrats (4). Using this value as our starting point, we will then use Excel functions to calculate the probability of seeing 4 or fewer female Democrats, given the total number of females and the total number of Democrats in the 25-student sample.
Step-by-Step Calculation of One-Tailed P-Values
To perform the calculation in Excel, we use the HYPGEOM.DIST function with the following syntax: =HYPGEOM.DIST(sample_s, number_sample, population_s, number_pop, cumulative). Each part of this formula must be carefully linked to the contingency table created earlier. The “sample_s” refers to the value in our individual cell of interest (4). The “number_sample” is the total for the column containing that cell (12). The “population_s” is the total for the row containing that cell (13). Finally, the “number_pop” is the grand total of the entire sample (25).
The “cumulative” argument is set to TRUE because we want to find the cumulative probability of obtaining a value as extreme as or more extreme than the one observed. This effectively calculates the one-tailed p-value. A one-tailed test is used when the researcher has a specific directional hypothesis—for example, that females are specifically less likely to be Democrats. In Excel, the implementation looks like this:

As shown in the calculation, the resulting one-tailed p-value is approximately 0.0812. This value represents the probability of observing exactly 4 or fewer female Democrats by pure chance, assuming there is no actual association between gender and party preference. While this gives us a directional insight, most scientific research requires a two-tailed p-value to account for deviations in either direction, ensuring a more conservative and rigorous statistical significance check.
Methodologies for Determining Two-Tailed Significance
Calculating the two-tailed p-value for Fisher’s Exact Test in Excel is slightly more complex because the hypergeometric distribution is not always symmetrical. To find the two-tailed probability, we must account for the probability of observing a result as extreme as our data in both directions. This involves summing the probability of our observed result with the probabilities of other results that are equally or more unlikely. In the context of our 2×2 table, this involves a specific two-step addition process.
First, we take the one-tailed p-value we already calculated (0.0812). Second, we calculate the probability at the opposite end of the distribution. This is done by finding 1 minus the probability of a specific count in the opposite direction, essentially mirroring our initial calculation. In our example, we would calculate 1 minus the probability of getting 8 “successes,” where 8 is derived from the column total minus our initial cell value. This ensures we are capturing the “extreme” tail on the other side of the distribution curve.

By adding these two probabilities together, we arrive at a final two-tailed p-value of 0.1152. This number is the final metric used to judge the null hypothesis. Because it considers possibilities in both directions—that females could be significantly more likely OR significantly less likely to prefer a party—it is the standard for reporting in most academic journals and professional research reports. This thoroughness is what makes Fisher’s Exact Test so reliable for small-scale data analysis.
Interpreting Statistical Outputs and the Null Hypothesis
Once the p-value has been calculated, the final and most critical step is interpretation. In statistical testing, we compare our p-value against a predetermined threshold known as alpha (typically set at 0.05). If the p-value is less than 0.05, we reject the null hypothesis and conclude that there is a statistically significant association between the variables. If the p-value is greater than 0.05, we fail to reject the null hypothesis, meaning the observed data does not provide enough evidence to suggest a relationship exists.
In our specific example regarding gender and political party preference, both the one-tailed value (0.0812) and the two-tailed value (0.1152) are greater than the 0.05 threshold. Consequently, we cannot reject the null hypothesis. Despite appearing to be a difference in the counts within our contingency table, the Fisher’s Exact Test informs us that these differences are likely due to random chance rather than a systemic association between gender and political leaning among the student population.
It is important to remember that failing to reject the null hypothesis does not “prove” that there is no association; it simply means that our current sample of 25 students does not provide sufficient evidence to confirm one. This is a vital distinction in data analysis. Researchers often use these results to determine if a larger follow-up study is warranted. In this case, the results suggest that if an association exists, it is quite weak, or our sample size was too small to detect it with confidence.
Enhancing Analysis with Excel’s Data Analysis Add-ins
While the manual method using HYPGEOM.DIST is highly accurate, Excel also supports various add-ins that can streamline Fisher’s Exact Test. The “Data Analysis” Toolpak, which is built into Excel, offers a range of tools for descriptive statistics and regression, though it lacks a direct Fisher’s button. However, third-party statistical add-ins like XLSTAT or Real Statistics Resource Pack can integrate directly into the Excel interface, providing a more automated way to generate reports and contingency table analyses.
These tools often provide additional statistical significance measures, such as odds ratios and confidence intervals, which offer a deeper look into the strength of the association. For professionals who perform data analysis frequently, investing time in setting up these add-ins can save significant effort and reduce the risk of manual formula errors. They also often provide a cleaner output, including formatted tables and automated interpretations of the p-value, which are ready for presentation.
In summary, Microsoft Excel remains a powerful and accessible environment for conducting Fisher’s Exact Test. Whether through the precise application of the hypergeometric distribution functions or the use of advanced add-ins, the software allows researchers to handle complex categorical variables with ease. By following these structured steps, you can ensure your research is backed by rigorous mathematical proof, making your findings credible and impactful in your respective field.
Cite this article
stats writer (2026). How to Perform Fisher’s Exact Test in Excel for Accurate Results. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-can-fishers-exact-test-be-performed-in-excel/
stats writer. "How to Perform Fisher’s Exact Test in Excel for Accurate Results." PSYCHOLOGICAL SCALES, 10 Mar. 2026, https://scales.arabpsychology.com/stats/how-can-fishers-exact-test-be-performed-in-excel/.
stats writer. "How to Perform Fisher’s Exact Test in Excel for Accurate Results." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-can-fishers-exact-test-be-performed-in-excel/.
stats writer (2026) 'How to Perform Fisher’s Exact Test in Excel for Accurate Results', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-can-fishers-exact-test-be-performed-in-excel/.
[1] stats writer, "How to Perform Fisher’s Exact Test in Excel for Accurate Results," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Perform Fisher’s Exact Test in Excel for Accurate Results. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.