Table of Contents
An Introduction to the Binomial Distribution in Python
The Binomial Distribution serves as a fundamental pillar in the realm of statistics and probability theory, providing a robust framework for modeling the likelihood of a specific number of successes within a sequence of independent trials. Each trial in this context is characterized by a binary outcome—often referred to as a Bernoulli trial—where only two possibilities exist, such as success or failure, heads or tails, or pass or fail. In the modern data-driven landscape, utilizing Python to analyze these distributions allows researchers and data scientists to move beyond theoretical calculations and into high-performance computational modeling.
Within practical applications, the Binomial Distribution is indispensable for predicting outcomes in various professional fields. For instance, a marketing campaign manager might use it to estimate the probability of achieving a certain conversion rate among a fixed set of leads. Similarly, engineers in a manufacturing process utilize these mathematical models to determine the frequency of defects within a production batch. By understanding the underlying mechanics of this distribution, one can make data-backed decisions that mitigate risk and optimize operational efficiency.
Python has become the language of choice for such statistical analysis due to its extensive ecosystem of libraries. Tools such as SciPy and NumPy provide specialized modules, including the scipy.stats.binom module, which simplify the process of calculating complex probabilities and generating large-scale simulations. This tutorial will delve into the technical implementation of these concepts, ensuring that you can effectively visualize and interpret discrete probability data using the most authoritative tools available in the Python programming environment.
The Mathematical Foundation and Formula
To master the application of the Binomial Distribution, one must first comprehend the mathematical formula that governs it. The distribution describes the behavior of a random variable, typically denoted as X, which represents the number of successes in n trials. The probability of achieving exactly k successes is determined by the specific interplay between the number of trials, the probability of success in each individual trial, and the number of possible combinations of those successes.
The formal mathematical expression is defined as: P(X=k) = nCk * pk * (1-p)n-k. In this equation, the component nCk, often referred to as the binomial coefficient or “n choose k,” calculates the number of ways to arrange k successes among n total attempts. This ensures that the order of successes does not impact the final probability, focusing instead on the aggregate outcome of the experiment. The term p represents the constant probability of success for any single trial, while (1-p) represents the probability of failure.
Understanding these parameters is crucial for accurate modeling:
- n: Represents the total number of independent trials conducted in the experiment.
- k: Denotes the specific number of successful outcomes one wishes to calculate the probability for.
- p: The probability of success on any given individual trial, expressed as a decimal between 0 and 1.
- nCk: The combination formula used to find the number of distinct ways k items can be chosen from a set of n.
By defining these variables clearly, we can translate real-world scenarios into mathematical models. Whether you are analyzing a scientific experiment or a financial model, these parameters remain the consistent building blocks of the Binomial Distribution. In the following sections, we will explore how Python automates these calculations, allowing for the processing of vast datasets that would be impossible to handle manually.
Generating Binomial Samples with NumPy
One of the most powerful features of Python is the ability to simulate random events through stochastic modeling. By using the NumPy library, specifically the random.binomial function, users can generate an array of values that simulate the results of multiple binomial experiments. This is particularly useful for Monte Carlo simulations, where researchers need to observe the potential variability of outcomes over thousands of iterations.
The random.binomial function requires three primary arguments: the number of trials (n), the probability of success (p), and the size of the output array. The output is a collection of integers, where each integer represents the number of successes observed in a single set of trials. This provides a direct way to observe the law of large numbers in action, as the average of these successes will eventually converge toward the expected value of the distribution.
from numpy import random #generate an array of 10 values that follow a binomial distribution random.binomial(n=10, p=.25, size=10) array([5, 2, 1, 3, 3, 3, 2, 2, 1, 4])
In the code snippet provided above, the function generates 10 different results. Each result is derived from 10 independent trials where the success probability was set to 25%. For instance, an output of 5 suggests that in that specific instance of the experiment, half of the trials resulted in a success despite the relatively low probability. This variance is a natural characteristic of random variables and highlights why repeated simulation is necessary for accurate statistical analysis.
As you scale your analysis, NumPy remains highly efficient due to its vectorized operations, which allow it to handle millions of samples with minimal computational overhead. This makes it an essential tool for anyone working in computational statistics or machine learning, where the Binomial Distribution often appears as a component of larger, more complex models.
Calculating Exact Probabilities with the PMF
While generating random samples is useful for simulation, many statistical questions require the calculation of an exact probability. This is achieved using the Probability Mass Function (PMF). The PMF provides the probability that a discrete random variable is exactly equal to some value. In Python, the SciPy library offers the binom.pmf function to perform this calculation with high precision.
Consider a scenario involving a basketball player, Nathan, who has a documented success rate for free throws. If we define a “success” as making a basket, we can model his performance over a set number of shots. This is a classic application of the Binomial Distribution because each shot is assumed to be independent and the probability of success remains constant across the trials.
Question 1: Nathan makes 60% of his free-throw attempts. If he shoots 12 free throws, what is the probability that he makes exactly 10?
from scipy.stats import binom #calculate binomial probability binom.pmf(k=10, n=12, p=0.6) 0.0639
The resulting value of 0.0639 indicates that there is approximately a 6.39% chance Nathan will land exactly 10 out of 12 shots. This type of analysis is vital in sports analytics and predictive modeling, where understanding the likelihood of specific performance benchmarks can inform coaching strategies or betting odds. By utilizing binom.pmf, you eliminate the risk of manual calculation errors, especially when dealing with large values for n and k.
Furthermore, the PMF is an essential concept when testing null hypotheses in statistical inference. By comparing observed results to the probabilities generated by the PMF, researchers can determine if a result is statistically significant or if it likely occurred by random chance. This precision is what makes SciPy an industry-standard tool for scientific computing and rigorous data analysis.
Determining Cumulative Probabilities with the CDF
In many real-world situations, we are less interested in an exact number of successes and more concerned with a range of outcomes, such as “at most” or “no more than” a certain value. To address these questions, we use the Cumulative Distribution Function (CDF). The CDF calculates the probability that the random variable X will take a value less than or equal to k. This is effectively the sum of the PMF values for all integers from 0 to k.
A simple example of this is a coin flip. If we flip a fair coin, the probability of heads is 0.5. If we want to know the likelihood of seeing a small number of heads over multiple flips, the CDF is the appropriate mathematical tool. This helps in understanding the lower tail of the distribution, which is often used in quality control and risk management to identify underperforming processes.
Question 2: Marty flips a fair coin 5 times. What is the probability that the coin lands on heads 2 times or fewer?
from scipy.stats import binom #calculate binomial probability binom.cdf(k=2, n=5, p=0.5) 0.5
The output of 0.5 means there is a 50% probability that Marty will see 0, 1, or 2 heads in 5 flips. Because the Binomial Distribution is symmetric when p = 0.5, this result aligns with our intuitive understanding of the scenario. The binom.cdf function in SciPy provides a streamlined way to reach this conclusion without having to manually sum individual probabilities.
Using the CDF is particularly important when evaluating thresholds. In a business context, if a manager knows that a project is only viable if the failure rate is kept below a certain percentage, the CDF can calculate the probability of staying within that safe zone. This makes it a cornerstone of decision science and probabilistic forecasting in both Python and general statistics.
Analyzing Range Probabilities and Complex Scenarios
Advanced statistical inquiries often require finding the probability that an outcome falls within a specific range, rather than just being above or below a single point. To calculate the probability of obtaining between a and b successes, we subtract the CDF of the lower bound (minus one) from the CDF of the upper bound. This technique is frequently used in political science and public policy to analyze survey results and polling data.
For example, if a legislative body is interested in public support for a new law, they might look at a sample of the population. If the general support level is known, they can calculate the probability that a random sample will accurately reflect that majority. This helps in assessing the reliability of small-scale surveys before making significant policy decisions.
Question 3: It is known that 70% of individuals support a certain law. If 10 individuals are randomly selected, what is the probability that between 4 and 6 of them support the law?
from scipy.stats import binom #calculate binomial probability binom.cdf(k=6, n=10, p=0.7) - binom.cdf(k=3, n=10, p=0.7) 0.3398
The calculation reveals a probability of 0.3398, or approximately 34%. By subtracting the probability of having 3 or fewer supporters from the probability of having 6 or fewer, we isolate the specific interval of 4, 5, and 6. This method is incredibly versatile and allows data analysts to answer nuanced questions about confidence intervals and variance within a dataset.
This approach to range-based probability is a staple in quantitative research. Whether you are measuring the efficacy of a new drug in a clinical trial or the likelihood of a stock market index moving within a certain range, the ability to manipulate the CDF in Python provides a level of analytical depth that is essential for modern professional environments.
Visualizing the Distribution with Seaborn and Matplotlib
Data visualization is a critical step in any statistical workflow, as it allows for the immediate identification of patterns, skewness, and outliers. By plotting a Binomial Distribution, we can see how the probability is concentrated around the mean and how it tapers off toward the extremes. In Python, the combination of Matplotlib and Seaborn offers a powerful suite for creating high-quality, professional charts.
When visualizing these distributions, we typically use a histogram or a bar chart, as the binomial distribution is discrete rather than continuous. The x-axis represents the number of successes, while the y-axis represents the frequency or probability of those successes occurring. As the number of trials increases, the shape of the Binomial Distribution begins to resemble the Normal Distribution, a phenomenon known as the De Moivre-Laplace Theorem.
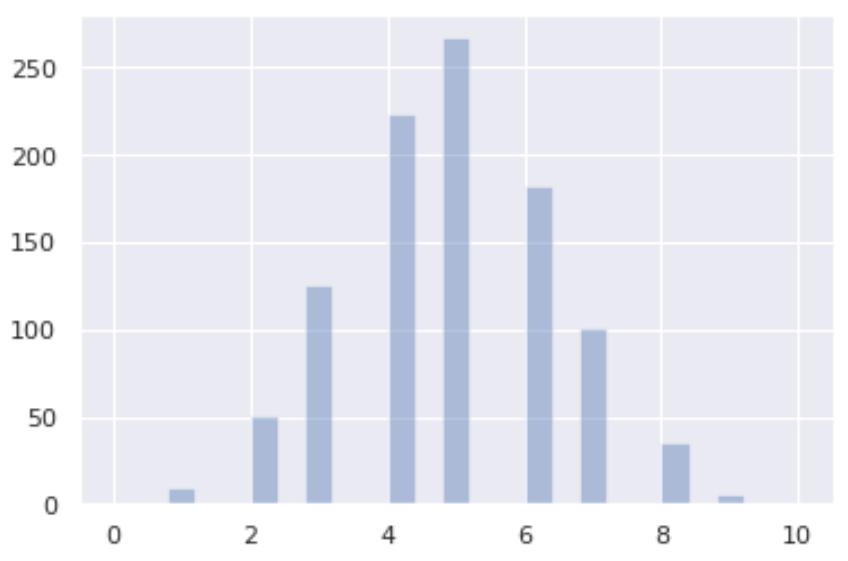
from numpy import random import matplotlib.pyplot as plt import seaborn as sns x = random.binomial(n=10, p=0.5, size=1000) sns.distplot(x, hist=True, kde=False) plt.show()

The resulting plot provides a clear visual representation of 1,000 experiments. The x-axis tracks the number of successes over 10 trials, while the y-axis shows how many times each outcome occurred. In this case, with a 50% success rate, the distribution is centered around 5 successes, forming a symmetric bell-shaped curve. Visual aids like this are indispensable for communicating complex statistical findings to stakeholders who may not have a technical background.
Mastering these visualization tools ensures that your data stories are both compelling and accurate. By using Seaborn to style your plots and Matplotlib to manage the figure structure, you can produce publication-ready graphics that clearly illustrate the behavior of stochastic processes. This concludes our exploration of how the Binomial Distribution is implemented and utilized within the Python ecosystem.
Cite this article
stats writer (2026). How to Implement the Binomial Distribution in Python. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-can-the-binomial-distribution-be-used-in-python/
stats writer. "How to Implement the Binomial Distribution in Python." PSYCHOLOGICAL SCALES, 16 Mar. 2026, https://scales.arabpsychology.com/stats/how-can-the-binomial-distribution-be-used-in-python/.
stats writer. "How to Implement the Binomial Distribution in Python." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-can-the-binomial-distribution-be-used-in-python/.
stats writer (2026) 'How to Implement the Binomial Distribution in Python', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-can-the-binomial-distribution-be-used-in-python/.
[1] stats writer, "How to Implement the Binomial Distribution in Python," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Implement the Binomial Distribution in Python. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.