Table of Contents
Understanding the Fundamental Principles of Statistical Correlation
In the expansive field of statistics, researchers and data scientists frequently seek to uncover and quantify the intricate relationships that exist between various numerical factors. Understanding how one variable changes in relation to another is not merely an academic exercise; it is a foundational requirement for predictive modeling, scientific discovery, and evidence-based decision-making. Whether analyzing economic indicators, biological markers, or educational outcomes, the ability to measure the association between variables provides the clarity needed to navigate complex datasets and derive meaningful conclusions about the world around us.
One of the most robust and widely utilized tools for this purpose is the Pearson correlation coefficient. This mathematical metric serves as a standardized measure of the linear association between two continuous variables, offering a precise numerical value that describes how closely the data points cluster around a straight line. By condensing the relationship into a single figure, the coefficient allows analysts to compare disparate types of data on a common scale, facilitating a deeper understanding of the underlying mechanics governing a particular system or phenomenon.
The Pearson correlation coefficient is constrained within a strict numerical range, specifically between -1 and 1. This bounded scale is critical for interpretation: a value of 1 signifies a perfect positive linear correlation, where an increase in one variable is consistently matched by a proportional increase in the other. Conversely, a value of -1 represents a perfect negative linear correlation, indicating that as one variable rises, the other falls in a predictable, linear fashion. A coefficient of 0 suggests that there is no linear relationship between the variables, meaning the movement of one does not provide information about the movement of the other.
Ultimately, the strength of the relationship is dictated by how far the coefficient deviates from zero. As the value approaches either extreme—1 or -1—the relationship becomes increasingly predictable and robust. In practical applications, perfectly correlated variables are rare; instead, analysts typically encounter varying degrees of correlation that require careful contextual interpretation to determine their scientific or business significance. By mastering the nuances of these coefficients, one gains the ability to transform raw data into a coherent narrative regarding the interplay of different forces.
Deconstructing the Structure and Purpose of a Correlation Matrix
While calculating the relationship between a single pair of variables is straightforward, modern research often involves high-dimensional data containing numerous interdependent factors. In such scenarios, a correlation matrix becomes an indispensable tool. A correlation matrix is essentially a square table that displays the correlation coefficients between all possible pairs of variables in a dataset. This structured format allows for the simultaneous examination of multiple relationships, providing a comprehensive overview of the data’s internal structure in a single, compact visualization.
The primary utility of the correlation matrix lies in its ability to synthesize large volumes of information. Instead of generating dozens of individual scatter plots or isolated correlation tests, an analyst can scan the matrix to identify the most significant associations. Each cell within the matrix corresponds to the intersection of two variables, containing the specific coefficient that defines their relationship. This grid-like arrangement ensures that no potential connection is overlooked, making it a critical first step in exploratory data analysis and subsequent model building.
Beyond simple identification, the matrix serves as a roadmap for more complex statistical procedures. By observing the distribution of coefficients, researchers can prioritize which variables warrant further investigation or inclusion in a predictive model. The systematic nature of the matrix also helps in spotting unexpected patterns or anomalies, such as variables that were hypothesized to be related but show no statistical association, or vice versa. In the context of large-scale data projects, the correlation matrix acts as a vital organizational framework that brings order to the initial chaos of raw information.
Practical Interpretation: An Educational Case Study
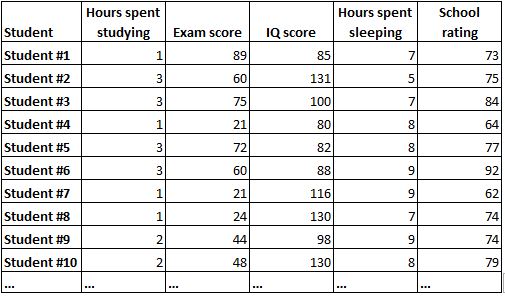
To better understand how to navigate this tool, let us consider a practical example involving educational metrics. The following correlation matrix illustrates the coefficients between several key variables: hours spent studying, exam scores, hours spent sleeping, IQ scores, and school ratings. This example demonstrates how the matrix presents a variety of relationships within a single analytical frame.

When interpreting a specific cell, we look at the intersection of a row and a column. For instance, if we examine the relationship between “hours spent studying” and “exam score,” we find a coefficient of 0.82. This high positive value indicates a strong positive correlation, suggesting that as students increase their study time, their exam scores tend to rise significantly. This finding confirms a common-sense intuition with empirical evidence, providing a quantified measure of the impact of academic effort on performance outcomes.

Conversely, the matrix can reveal negative correlations that highlight trade-offs between variables. In our example, the correlation between “hours spent studying” and “hours spent sleeping” is -0.22. While this is considered a relatively weak relationship, the negative sign indicates an inverse association: students who spend more time studying often experience a slight reduction in their sleep duration. This insight allows researchers to understand the hidden costs or secondary effects associated with certain behaviors within the studied population.

Finally, the matrix helps identify variables with little to no relationship. The coefficient between “hours spent sleeping” and “IQ score” is a mere 0.06, which is very close to zero. This implies that there is virtually no linear association between how much a student sleeps and their cognitive ability as measured by an IQ score. Such findings are crucial because they prevent analysts from making false assumptions about causality or connection where none exists, ensuring that subsequent models remain grounded in actual data trends.

Structural Properties: Symmetry and the Identity Diagonal
One of the most distinct visual characteristics of a correlation matrix is its perfect symmetry. Because the correlation between variable A and variable B is mathematically identical to the correlation between variable B and variable A, the values mirrored across the main diagonal are redundant. For example, if the top right cell represents the relationship between “hours spent studying” and “school rating,” the bottom left cell will contain the exact same value. This inherent property is a direct result of the commutative nature of the Pearson correlation coefficient calculation.

Another defining feature is the identity diagonal, which runs from the top-left to the bottom-right of the table. Every cell along this diagonal will always have a value of 1. This is because every variable is perfectly correlated with itself; an increase in “exam score” is, by definition, perfectly matched by an increase in “exam score.” While these cells are a necessary component of the matrix’s mathematical structure, they do not provide any useful analytical insight and are typically ignored during the interpretation process.

Recognizing these structural properties allows for more efficient data reading. Experienced analysts often focus on only one half of the matrix—either the upper or lower triangle—to avoid the mental clutter of redundant information. Understanding that the matrix is a reflection of itself simplifies the task of identifying key drivers within the dataset, allowing the researcher to focus on unique pairings and the stories they tell about the variables involved.
Variations in Visualization: From Tables to Heatmaps
Because the standard correlation matrix contains redundant information, many statistical packages and researchers choose to display only a portion of the table. A “lower triangular matrix” or “upper triangular matrix” removes the repeated coefficients, leaving behind a cleaner, more readable version of the data. This truncated format is particularly useful when dealing with very large datasets where a full square matrix would become visually overwhelming and difficult to interpret at a glance.
To further enhance interpretability, analysts often apply color coding to the matrix, creating what is known as a heatmap. In a correlation heatmap, the intensity of the color corresponds to the strength of the correlation coefficient. For instance, strong positive correlations might be represented by deep blue, while strong negative correlations appear in vibrant red, and values near zero remain neutral or white. This visual layer allows the human eye to immediately detect clusters of highly related variables without needing to read every individual numerical value.

These variations in visualization are not merely aesthetic choices; they are functional improvements that facilitate faster insight. By leveraging heatmaps or triangular formats, researchers can communicate complex statistical findings to non-technical stakeholders more effectively. Visualizing data in this way highlights the “big picture” trends while still maintaining the underlying precision of the Pearson correlation coefficient, bridging the gap between raw numbers and actionable intelligence.
The Role of the Correlation Matrix in Dataset Summarization
One of the primary reasons to generate a correlation matrix is its efficiency in summarizing large, complex datasets. Consider a dataset containing information on 1,000 different students across dozens of metrics. Attempting to understand the relationships between these variables by manually inspecting the raw data would be an impossible task. The sheer volume of rows and columns would obscure any meaningful patterns, leading to “analysis paralysis” or overlooked insights.

By condensing this massive amount of raw information into a compact correlation matrix, the analyst can quickly grasp the fundamental dynamics at play. The matrix acts as a high-level summary, highlighting which factors are movers of the system and which are merely noise. This summary is essential for the initial phase of any data science project, as it informs the researcher about which variables are worth including in more intensive longitudinal studies or predictive algorithms.
Furthermore, this summarization serves as a reality check for experimental design. If two variables that were expected to be highly related show a correlation near zero, it may indicate issues with data collection, measurement error, or an incorrect underlying hypothesis. In this sense, the correlation matrix is more than just a summary; it is a diagnostic tool that validates the integrity of the dataset before more advanced statistical modeling begins.
Advanced Diagnostic Uses: Detecting Multicollinearity
In the context of linear regression, the correlation matrix serves a vital diagnostic function by helping to identify multicollinearity. Multicollinearity occurs when two or more independent variables in a regression model are highly correlated with each other. This creates a problem because it becomes difficult for the model to isolate the individual effect of each variable on the dependent outcome, leading to unstable coefficient estimates and misleading statistical significance tests.
By reviewing a correlation matrix before running a linear regression, a researcher can proactively identify pairs of independent variables with high correlation coefficients (typically above 0.7 or 0.8). If such a relationship exists, the researcher might choose to remove one of the variables, combine them into a single index, or use specialized techniques like ridge regression to mitigate the impact of the overlap. This step is crucial for ensuring that the final model is both accurate and interpretable.
The detection of multicollinearity through a matrix is a standard best practice in econometrics and social science research. Without this check, a model might appear to have high predictive power while actually being fundamentally flawed in its explanation of how individual factors contribute to the result. Thus, the correlation matrix acts as a safeguard, protecting the validity of the conclusions drawn from multiple linear regression models.
Input for Complex Multivariate Models
Beyond its use as a summary and diagnostic tool, the correlation matrix is frequently used as a direct mathematical input for more advanced multivariate statistical techniques. For instance, exploratory factor analysis (EFA) relies on the matrix to identify underlying “latent” variables that explain the patterns of correlation among observed variables. By analyzing the matrix, EFA can group related items together, allowing researchers to reduce the dimensionality of their data and identify core themes.
Similarly, structural equation modeling (SEM) utilizes the correlation or covariance matrix to test complex hypotheses about the relationships between multiple dependent and independent variables simultaneously. In these advanced frameworks, the matrix is the literal foundation upon which the entire model is built. Accuracy in the initial correlation calculations is therefore paramount, as any errors at this stage will propagate through the more complex stages of the analysis.
The versatility of the correlation matrix in these contexts underscores its importance in the broader statistical landscape. It is not just a simple table for viewing; it is a sophisticated data structure that enables the transition from simple bivariate analysis to complex, multi-layered modeling of real-world systems. Whether used for psychometrics, marketing research, or genomic studies, the matrix remains a cornerstone of multivariate statistics.
Implementing Correlation Matrices in Statistical Software
In the modern era, analysts rarely calculate these matrices by hand. Instead, they rely on powerful statistics software and programming languages to generate them efficiently. Each platform offers unique advantages, ranging from the user-friendly interface of spreadsheet applications to the robust, scriptable environments of data science languages. Understanding how to generate a correlation matrix across these tools is a necessary skill for any data professional.
The following resources provide detailed, step-by-step guidance on how to create and interpret these matrices using the most popular tools in the industry today:
- How to Create a Correlation Matrix in Excel: Ideal for quick analysis and users who prefer a spreadsheet-based workflow.
- How to Create a Correlation Matrix in SPSS: A comprehensive guide for social scientists using the SPSS graphical interface.
- How to Create a Correlation Matrix in Stata: Targeted at economists and researchers who utilize Stata for rigorous data analysis.
- How to Create a Correlation Matrix in Python: A tutorial for data scientists using Python libraries like Pandas and Seaborn to generate and visualize matrices.
By leveraging these tools, you can transform raw datasets into clear, actionable correlation matrices, enabling a deeper understanding of the connections that define your data. Whether you are performing a simple check of linear association or preparing data for a structural equation modeling project, mastering the interpretation of the correlation matrix is an essential step in your analytical journey.
Cite this article
stats writer (2026). How to Interpret a Correlation Matrix in 5 Easy Steps. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/what-is-the-process-for-interpreting-a-correlation-matrix/
stats writer. "How to Interpret a Correlation Matrix in 5 Easy Steps." PSYCHOLOGICAL SCALES, 6 Mar. 2026, https://scales.arabpsychology.com/stats/what-is-the-process-for-interpreting-a-correlation-matrix/.
stats writer. "How to Interpret a Correlation Matrix in 5 Easy Steps." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/what-is-the-process-for-interpreting-a-correlation-matrix/.
stats writer (2026) 'How to Interpret a Correlation Matrix in 5 Easy Steps', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/what-is-the-process-for-interpreting-a-correlation-matrix/.
[1] stats writer, "How to Interpret a Correlation Matrix in 5 Easy Steps," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Interpret a Correlation Matrix in 5 Easy Steps. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.