Table of Contents
Understanding the Foundations of Effect Size in Research
In the realm of quantitative research, Effect size serves as a fundamental metric that quantifies the magnitude of a relationship or the specific difference between variables. While many researchers traditionally focus on whether a result is likely to have occurred by chance, this metric shifts the focus toward the actual strength or impact of the phenomenon under investigation. By providing a standardized measure of magnitude, it allows practitioners to move beyond the binary conclusion of significance to a more nuanced understanding of how much one variable influences another. This distinction is vital in fields such as medicine, psychology, and education, where the practical utility of a finding often outweighs its mathematical probability.
The importance of Effect size cannot be overstated, as it empowers researchers to accurately compare the efficacy of various interventions or treatments across different studies. When evaluating complex data, simply knowing that a treatment “works” is rarely sufficient; decision-makers need to understand the degree to which it works to make informed choices regarding resource allocation and practical implementation. By emphasizing the practical significance of results, this measure ensures that findings are not just statistically visible but are meaningful in real-world contexts. Furthermore, it plays a critical role in enhancing the reproducibility of research, providing a consistent benchmark that other scientists can use to verify or challenge previous findings.
Beyond its descriptive capabilities, this statistical tool is essential for the planning phases of future empirical inquiries. It is a primary component in Sample size calculations, helping researchers determine how many participants are required to detect a meaningful impact with sufficient power. Additionally, it serves as the backbone of a Meta-analysis, where results from multiple independent studies are synthesized into a single, cohesive conclusion. Without a standardized measure like this, combining data from studies with different scales and populations would be nearly impossible. Ultimately, it remains a cornerstone for the rigorous interpretation and application of scientific research findings.
As the eminent statistician Gene V. Glass famously noted, Statistical significance is often the least interesting aspect of a result. He argued that researchers should prioritize describing findings in terms of magnitude—focusing not just on whether a treatment affects individuals, but specifically how much it affects them. This philosophy highlights the shift from a “yes/no” approach to a more descriptive, high-resolution view of data. By adopting this perspective, the scientific community can better communicate the true value of their discoveries to the public and to policymakers who rely on evidence-based data.
The Disconnect Between P-Values and Practical Impact
In contemporary statistical practice, researchers frequently rely on Statistical significance to determine if an observed difference between two groups is unlikely to be a result of random variation. For instance, consider a scenario where an educator wishes to determine if two distinct studying techniques lead to varying test performance. In this experiment, one group of 20 students prepares using Technique A, while a second group of 20 students prepares using Technique B. After the preparation period, all students complete the same assessment to measure their retention and understanding of the material.
Upon analyzing the results via a T-test for a difference in means, the researcher might find a P-value of 0.001. If a standard alpha level of 0.05 is applied, this result indicates a statistically significant difference between the two groups. From this, one might conclude that the studying technique definitely has an impact on the scores. However, this conclusion remains incomplete because the P-value only addresses the existence of a difference, not the intensity or the practical value of that difference in a classroom setting.
While the P-value confirms that the technique has an impact, it fails to describe the size of that impact. For example, Technique A might lead to scores that are only 0.5% higher than Technique B. While this might be statistically significant in a very controlled or large sample, it may be entirely irrelevant to a teacher deciding which method to implement. To bridge this gap, we must turn to Effect size, which provides the necessary context to determine if the findings are truly useful or merely mathematically detectable.
In practice, Effect size metrics are often more compelling and informative than P-value results. They allow for a deeper level of analysis that considers the human or physical implications of the data. By quantifying the magnitude of the difference, researchers can categorize results as trivial, moderate, or substantial, thereby providing a clearer roadmap for how the findings should be applied in professional or clinical environments. This ensures that scientific conclusions are grounded in the reality of the effects they describe.
Standardized Mean Difference and Cohen’s d
When the primary objective of a study is to compare the average scores or values between two distinct groups, the most appropriate measure is the standardized mean difference. This approach allows researchers to compare results from different studies even if they used different measurement scales. The most widely recognized and utilized formula for this calculation is known as Cohen’s d. This metric provides a clear, unit-less value that represents how many standard deviations separate the means of the two groups being compared.
The mathematical expression for Cohen’s d is calculated as the difference between the sample means of the two groups (x₁ – x₂), divided by the Standard deviation of the population from which the groups were drawn. By using the Standard deviation as a denominator, the resulting value is standardized, making it universally interpretable regardless of the original unit of measurement, such as points on a test, milligrams of a drug, or seconds of reaction time.
Interpreting this value is straightforward: a Cohen’s d of 1.0 signifies that the two group means differ by exactly one Standard deviation. A value of 2.0 indicates a difference of two standard deviations, while a value of 2.5 suggests a very large gap of 2.5 standard deviations. This scalability allows for a precise description of how much the groups overlap or diverge. Another intuitive way to perceive this is through the lens of percentile rankings; for example, an Effect size of 0.3 implies that the average person in the second group scores higher than 62% of the individuals in the first group.
The following table illustrates the relationship between the magnitude of the Effect size and the corresponding percentage of individuals in Group 2 who would rank below the average person in Group 1:
- 0.0: 50%
- 0.2: 58%
- 0.4: 66%
- 0.6: 73%
- 0.8: 79%
- 1.0: 84%
- 1.2: 88%
- 1.4: 92%
- 1.6: 95%
- 1.8: 96%
- 2.0: 98%
- 2.5: 99%
- 3.0: 99.9%
Generally, a Cohen’s d of 0.2 or less is regarded as a small Effect size, while 0.5 represents a medium effect and 0.8 or higher is considered a large effect. If the means of two groups do not differ by at least 0.2 standard deviations, the difference is often deemed trivial in a practical sense, even if the P-value suggests statistical significance. This benchmark helps prevent overstating the importance of minor variations that have little real-world consequence.
The Pearson Correlation Coefficient as an Effect Measure
When researchers aim to examine the quantitative relationship between two continuous variables rather than comparing group means, they utilize the Pearson correlation coefficient. Denoted as r, this statistic measures the strength and direction of the linear association between two variables, typically referred to as X and Y. It is one of the most versatile measures in statistics, providing a value that ranges from -1.0 to +1.0, which allows for a concise summary of how two factors move in relation to one another.
The interpretation of the Pearson correlation coefficient is based on its proximity to the extreme values of its range. A value of +1 indicates a perfect positive linear relationship, where an increase in one variable corresponds exactly to an increase in the other. Conversely, a value of -1 represents a perfect negative linear relationship. A value of 0 indicates that no linear association exists between the variables whatsoever. The further the coefficient is from zero, the more powerful the relationship, serving as a direct indicator of the Effect size of the correlation.
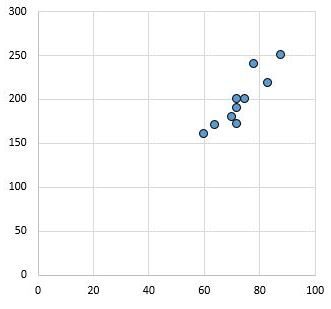
Visualizing these relationships through scatterplots is an effective way to understand the magnitude of the correlation. For instance, a scatterplot displaying a correlation coefficient of r = 0.94 would show data points clustered very tightly along a rising line, indicating a very strong positive relationship. In contrast, a scatterplot with a value of r = 0.03 would appear as a random cloud of points, suggesting that changes in one variable have virtually no predictable impact on the other. This visualization reinforces the concept that the Effect size tells the story of the data’s consistency and strength.

As seen in the visual representations, the density and alignment of the data points provide an immediate sense of the relationship’s utility. In the second example below, the lack of alignment demonstrates why a low correlation coefficient implies a negligible Effect size, making the relationship unreliable for predictive purposes.

Standard benchmarks for the Pearson correlation coefficient generally categorize an r value of 0.1 as a small effect, 0.3 as a medium effect, and 0.5 or greater as a large effect. However, these thresholds can vary significantly depending on the field of study. In the social sciences, a correlation of 0.3 might be considered quite substantial, whereas in the physical sciences, a much higher value might be required to be considered meaningful. Understanding these context-specific nuances is essential for any rigorous data analysis.
Utilizing the Odds Ratio for Categorical Outcomes
In studies involving categorical outcomes—such as “success” versus “failure” or “recovered” versus “not recovered”—the Odds ratio is the preferred method for calculating Effect size. This measure compares the odds of an event occurring in a treatment group to the odds of that same event occurring in a control group. It is particularly prevalent in clinical trials and epidemiological research, where it helps determine the relative risk or benefit of a specific medical intervention or exposure factor.
To calculate this metric, researchers typically use a 2×2 contingency table that organizes the number of successes and failures for both the treatment and control groups. For example:
- Treatment Group: A (Successes), B (Failures)
- Control Group: C (Successes), D (Failures)
The formula for the Odds ratio is expressed as (A * D) / (B * C). The resulting value indicates how much more (or less) likely the outcome is to occur in one group compared to the other. If the ratio is equal to 1, it implies that there is no difference in the odds between the groups, suggesting that the treatment has no effect. The further the ratio deviates from 1, the more significant the impact of the treatment is considered to be, providing a clear numerical representation of the Effect size.
An Odds ratio greater than 1 suggests that the treatment increases the likelihood of the outcome, while a ratio less than 1 suggests it decreases the likelihood. This information is vital for healthcare professionals and researchers who must weigh the potential benefits of a treatment against its risks. By quantifying the relative odds, this measure provides a practical perspective on the effectiveness of interventions that simple percentage differences might obscure, especially when dealing with rare events or small probabilities.
Comparing the Benefits of Effect Size and P-Values
One of the primary advantages of utilizing Effect size over P-value measurements is the clarity it provides regarding the magnitude of a finding. While a P-value can only indicate whether a result is statistically significant—essentially a “yes” or “no” answer—the Effect size describes the strength of the association or the size of the difference. This allows researchers to distinguish between results that are statistically significant but practically negligible, and those that represent a major breakthrough in the field.
Furthermore, these standardized measures are indispensable for Meta-analysis. Unlike P-value results, which are heavily dependent on the specific parameters of a single study, Effect size metrics can be aggregated across multiple studies conducted in different settings with different populations. This quantitative synthesis allows scientists to identify overarching trends and reach more robust conclusions by combining the power of several smaller investigations into a unified analysis of magnitude.
Another critical distinction is that P-value outcomes are highly sensitive to Sample size. In studies with very large samples, even the most minute and meaningless differences can produce a low P-value, potentially misleading researchers into believing they have found something important. Conversely, Effect size remains relatively stable regardless of the number of participants, providing a more reliable indicator of the actual phenomenon’s strength without being artificially inflated by a large “N”.
Consider a practical comparison: two studies might both report a P-value of 0.04. Without further information, they appear equally important. However, if Study A has an Effect size of 0.8 and Study B has an effect of 0.1, the researcher immediately knows that Study A represents a much more powerful and potentially useful discovery. This depth of information is what makes magnitude measures superior for high-stakes decision-making in science and industry alike.
The Paradox of Large Sample Sizes and Significance
The relationship between Sample size and Statistical significance is a common point of confusion in data analysis. To illustrate this, let us revisit the example of two studying techniques. Suppose we compare two groups of 20 students. Group 1 has a mean score of 90.65 (SD = 2.77), and Group 2 has a mean of 90.75 (SD = 2.78). When an independent T-test is performed, the test statistic is -0.113 with a P-value of 0.91. In this scenario, the difference is clearly not significant.
However, if we were to increase the Sample size to 200 students per group while maintaining the exact same means and standard deviations, the outcome changes dramatically. The T-test would then yield a test statistic of -1.97, resulting in a P-value just under 0.05. Suddenly, the 0.10 point difference in test scores—which is arguably meaningless in a real-world grading context—becomes “statistically significant.” This paradox occurs because large samples increase the statistical power of the test to detect even the most trivial variations.
The mathematical reason for this phenomenon lies in the formula for the T-test statistic. The formula is expressed as the difference between the means divided by the square root of the sum of the variances divided by their respective sample sizes. As n₁ and n₂ (the sample sizes) increase, the denominator of the equation becomes smaller. Since we are dividing by a smaller number, the resulting test statistic (t) grows larger. A larger t-value naturally leads to a smaller P-value, often crossing the threshold of significance without any change in the underlying Effect size.
This reality highlights why relying solely on significance levels can be dangerous. It can lead to “p-hacking” or the over-interpretation of results that have no practical utility. By always reporting the Effect size alongside the P-value, researchers provide a safeguard against this inflation, ensuring that the reader understands that while a difference may be “real” in a mathematical sense, it may also be too small to matter in practice.
Establishing Benchmarks for Meaningful Results
A frequent question among students and early-career researchers is: “What is considered a good Effect size?” The most accurate answer is that there is no universal “good” or “bad” value. These metrics are objective measurements of magnitude, much like a ruler measures length; a measurement of two inches isn’t “bad” unless you were specifically hoping for five. The value simply reflects the reality of the data. However, to help interpret these numbers, researchers often look to established “rules of thumb” popularized by statisticians like Jacob Cohen.
For Cohen’s d, the following benchmarks are widely accepted across various scientific disciplines:
- Small Effect (d ≤ 0.2): The difference is negligible and may not be visible to the naked eye in a practical setting.
- Medium Effect (d ≈ 0.5): The difference is moderate and likely large enough to be discernible by a keen observer.
- Large Effect (d ≥ 0.8): The difference is substantial and likely has significant practical implications.
For the Pearson correlation coefficient (r), the absolute values are typically interpreted as follows:
- Low Effect (r ≈ 0.1): A weak relationship where one variable provides very little predictive power for the other.
- Medium Effect (r ≈ 0.3): A moderate relationship that suggests a noticeable trend.
- Large Effect (r ≥ 0.5): A strong relationship where the variables are closely linked.
It is crucial to remember that what constitutes a “strong” or “meaningful” correlation can vary significantly from one field to another. In clinical medical trials, a small Effect size might still be considered a massive success if it pertains to life-saving outcomes. Conversely, in engineering, a correlation of 0.5 might be considered unacceptably low for precision components. Researchers should always refer to the prevailing literature in their specific industry to gain a deeper understanding of how these values are traditionally valued and applied within their professional context.
Cite this article
stats writer (2026). How to Understand and Calculate Effect Size for Meaningful Results. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/what-is-effect-size-and-why-is-it-important/
stats writer. "How to Understand and Calculate Effect Size for Meaningful Results." PSYCHOLOGICAL SCALES, 5 Mar. 2026, https://scales.arabpsychology.com/stats/what-is-effect-size-and-why-is-it-important/.
stats writer. "How to Understand and Calculate Effect Size for Meaningful Results." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/what-is-effect-size-and-why-is-it-important/.
stats writer (2026) 'How to Understand and Calculate Effect Size for Meaningful Results', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/what-is-effect-size-and-why-is-it-important/.
[1] stats writer, "How to Understand and Calculate Effect Size for Meaningful Results," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Understand and Calculate Effect Size for Meaningful Results. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.