Table of Contents
Undercoverage bias represents a fundamental challenge in the field of statistics and data science, occurring when the sampling frame—the list from which a sample is drawn—fails to include significant portions of the target population. When certain segments of a community or demographic are systematically excluded from the data collection process, the resulting sample cannot accurately reflect the diversity or characteristics of the whole. This discrepancy leads to systemic error, where the findings of a study are skewed toward the views or behaviors of the groups that were successfully reached, leaving the researchers with a distorted view of reality. Understanding this phenomenon is essential for anyone conducting empirical research or interpreting public opinion polls.
The primary danger of undercoverage bias lies in its ability to invalidate statistical inference. In a perfect world, a sample serves as a “miniature” version of the population, allowing researchers to extrapolate findings without the immense cost and time required to survey every single individual. However, if the sampling method is flawed, the extrapolation becomes mathematically unsound. For instance, if a researcher concludes that a city supports a specific policy based on a sample that excluded low-income neighborhoods, that conclusion is not just incomplete; it is potentially the opposite of the truth for the population as a whole.
Historically, undercoverage bias has been the culprit behind some of the most famous failures in polling history. A classic example is the 1936 Literary Digest poll, which predicted a landslide victory for Alf Landon over Franklin D. Roosevelt. The magazine’s sampling frame relied on automobile registrations and telephone directories—luxuries that many Americans could not afford during the Great Depression. Because the sample undercovered the lower socioeconomic classes who supported Roosevelt, the results were catastrophically inaccurate. This serves as a timeless reminder that a large sample size cannot compensate for a biased sampling methodology.
Theoretical Foundations: Why Undercoverage Bias Distorts Data
To understand why undercoverage bias is so problematic, one must first understand the relationship between a sample and its population. The goal of probabilistic sampling is to ensure that every individual in the target population has a known, non-zero chance of being selected. When undercoverage bias is present, the probability of selection for certain groups becomes zero. This creates a “blind spot” in the research. If the excluded group differs significantly in their opinions or characteristics from those who were included, the final dataset will suffer from a lack of validity.
The severity of the bias is determined by two main factors: the proportion of the population that is excluded and the degree to which the excluded group differs from the included group. If the excluded group is small and shares similar traits with the rest of the population, the bias may be negligible. However, if a large or distinct segment is missing—such as excluding all rural residents from a study on national infrastructure—the statistical results will be deeply flawed. This is why defining a comprehensive sampling frame is the most critical step in the design of any survey.
Furthermore, undercoverage bias often works in tandem with other forms of selection bias, such as non-response bias. While undercoverage refers to people who never had a chance to be in the sample, non-response bias refers to people who were selected but chose not to participate. Both lead to an unrepresentative sample, but undercoverage is particularly insidious because it is a structural failure of the research design itself. It suggests that the researchers did not even consider or reach the doors of specific demographic groups, making the resulting data fundamentally exclusionary.
Practical Illustration: The Pitfalls of Convenience Sampling
One of the most common causes of undercoverage bias is convenience sampling. This is a non-probability sampling technique where subjects are selected because of their convenient accessibility and proximity to the researcher. While this method is often faster and less expensive than more rigorous techniques, it is highly prone to sampling bias. A classic example involves researchers attempting to gauge public opinion on a new local ordinance by interviewing individuals at a public library.
While gathering data at a library may seem like a productive way to reach the community, it inherently excludes several vital groups. These groups include:
- Housebound individuals who cannot physically travel to the library due to age, illness, or disability.
- Citizens who do not use public library services or prefer digital resources, who might have different educational or social backgrounds.
- Commuters and workers who utilize libraries in different districts or cities, or whose work schedules conflict with library hours.
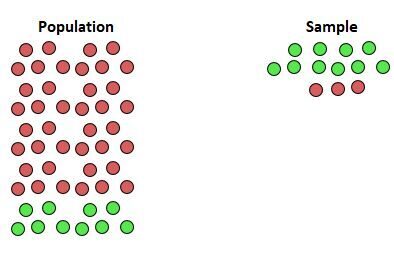
Because the study excludes these specific types of people, the results are unlikely to be representative. If the patrons of that particular library are more likely to support the law than the average citizen, the survey will report an inflated level of support. This creates a false consensus that does not exist in the broader community. The following visual illustrates how a sample can be heavily weighted toward one viewpoint while missing the diversity of the larger population:

In the illustration provided, the green circles represent individuals in favor of a law, while the red circles represent those opposed. Notice how the sampling process captured almost exclusively the green circles. This lack of representation means the study would erroneously conclude that the law has near-unanimous support, failing to reflect the significant opposition represented by the red circles in the target population. This is the essence of undercoverage bias: a failure to capture the true variance of the group being studied.
Real-World Case Study: Political and Medical Exclusions
In the realm of political science, undercoverage bias frequently occurs when voter sentiment is measured using sampling frames that only include “likely voters” or “registered voters.” While this might seem logical for predicting an election, it fails to capture the opinions of those who are not yet registered, such as young adults who have just reached the voting age, or non-citizens who may still be impacted by local policies. By ignoring these groups, pollsters may miss emerging political trends or shifts in public discourse that are driven by the very people excluded from the sample.
The healthcare and pharmaceutical industries also face significant risks from this bias. Consider a clinical trial designed to test the efficacy of a new, expensive medication. If the researchers only recruit participants from private clinics where patients can afford the treatment, the sample will suffer from undercoverage of lower-income individuals. This is problematic because socioeconomic status often correlates with other health determinants, such as diet, stress levels, and access to preventative care. Consequently, the study might find the medication to be highly effective within the sample, but those results might not be generalizable to the broader population who face different living conditions.
The ethical implications of undercoverage bias in medical research are profound. When marginalized groups are underrepresented in health data, the resulting medical guidelines may not be optimized for their specific needs. This can lead to health disparities where certain treatments are less effective or even harmful for the groups that were excluded during the experimental phase. Therefore, ensuring inclusive sampling is not just a matter of statistical accuracy, but also of social equity and patient safety.
Examining Further Examples: Accessibility and Socioeconomics
Another prevalent example of undercoverage bias can be found in urban planning and civic engagement. Researchers often attempt to learn what citizens think about a new public park by attending a town hall meeting. While this provides a platform for engaged citizens, it is a form of convenience sampling that excludes many. Those who lack transportation, those who work evening shifts, and those who are unaware the meetings exist are all underrepresented. As a result, the “public opinion” gathered at the meeting may only reflect the views of a privileged or particularly vocal subset of the population.
The methodology of telephonic surveys has also historically struggled with undercoverage. In the past, pollsters relied heavily on landline phonebooks to generate random digit dialing lists. However, as demographic shifts occurred, younger and more mobile populations moved exclusively to cell phones, often opting out of public directories. Additionally, very wealthy individuals frequently have unlisted numbers to maintain privacy. Studies that relied solely on landline directories thus undercovered both the youth and the wealthy, leading to data that was skewed toward older, middle-class demographics.
These socioeconomic barriers create a digital divide in modern data collection. As more surveys move online, undercoverage bias shifts toward those who lack reliable internet access or digital literacy. This typically affects rural populations, the elderly, and those living in poverty. If a government uses an online-only survey to determine the need for social services, they may ironically undercount the very people who need those services the most, as those individuals are the most likely to be excluded from the digital sampling frame.
The Impact of Location-Based Sampling at Local Establishments
Location-based sampling, such as conducting questionnaires at a local shopping mall, is another frequent source of undercoverage bias. Researchers might use this method to gauge opinions on traffic laws or urban development. However, the population of a mall is not representative of the city as a whole. It excludes people who prefer to shop online, those who cannot afford to shop at malls, and those who live in areas not served by public transit to that specific location.
Consider the following groups that are often excluded in a mall-based survey:
- Individuals with limited mobility who find navigating large shopping centers difficult.
- People with minimalist lifestyles or those who avoid consumer-centric environments.
- Residents from different geographic quarters of the city who frequent different local hubs.
The exclusion of these groups is particularly relevant when the survey topic is traffic laws. People who do not go to the mall might be the very individuals who avoid driving due to poor road conditions or inadequate infrastructure. By only sampling those who successfully navigated the traffic to reach the mall, the researchers are inherently sampling a group that is less hindered by the current traffic issues. This results in a “survivor bias” variant of undercoverage, where the data only reflects the experiences of those who are not being excluded by the very problems the study intends to investigate.
Strategies for Mitigating and Preventing Undercoverage Bias
To eliminate or significantly minimize the effects of undercoverage bias, researchers must move away from convenience sampling and embrace more rigorous probability-based methods. The gold standard in this regard is simple random sampling. In a simple random sample, every member of the target population has an equal and independent chance of being selected. This requires a comprehensive and up-to-date sampling frame that includes every individual in the population, which, while difficult to achieve, provides the strongest protection against bias.
Another powerful technique is stratified random sampling. This involves dividing the population into subgroups (strata) based on specific characteristics, such as age, income, or geography, and then taking a random sample from each stratum. This ensures that even small minority groups are adequately represented in the final dataset. By oversampling certain groups that are traditionally hard to reach, researchers can correct for potential undercoverage and ensure the sample’s composition matches the population’s actual demographics.
In addition to sampling design, researchers can use statistical weighting techniques during data analysis to correct for known undercoverage. If a survey ends up with fewer young people than exist in the actual population, statisticians can assign a higher “weight” to the responses of the young people who did participate. While weighting is a useful tool, it is not a perfect substitute for a representative sample, as it assumes that the few individuals reached are truly representative of the entire excluded subgroup.
Ensuring Data Integrity and Extrapolative Validity
The ultimate goal of any statistical study is to produce reliable and valid results that can be applied to the real world. When undercoverage bias is avoided through a robust simple random sample, the confidence intervals and p-values generated by the study become meaningful. This allows policymakers, scientists, and business leaders to make evidence-based decisions with the assurance that the data reflects the needs and opinions of the entire population, rather than just a convenient subset.
Rigorous sampling also enhances the credibility of the researcher and the institution. In an era where misinformation and skewed data are prevalent, adhering to high methodological standards is essential. By transparently defining the sampling frame and acknowledging any potential limitations, researchers can provide a clear context for their findings. This transparency is vital for the peer-review process and for the general public’s trust in scientific results.
In summary, undercoverage bias is a critical methodological error that occurs when segments of a population are left out of a sample. Whether it arises from convenience sampling at a library, telephonic exclusions, or location-based biases at a mall, the result is the same: unrepresentative data and inaccurate conclusions. By employing random sampling, stratification, and inclusive research designs, we can ensure that every voice in a population is heard, leading to data that is not only statistically sound but also socially representative.
Cite this article
stats writer (2026). How to Identify and Avoid Undercoverage Bias in Your Data Collection. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/what-is-undercoverage-bias-and-can-you-provide-examples-to-explain-it/
stats writer. "How to Identify and Avoid Undercoverage Bias in Your Data Collection." PSYCHOLOGICAL SCALES, 3 Mar. 2026, https://scales.arabpsychology.com/stats/what-is-undercoverage-bias-and-can-you-provide-examples-to-explain-it/.
stats writer. "How to Identify and Avoid Undercoverage Bias in Your Data Collection." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/what-is-undercoverage-bias-and-can-you-provide-examples-to-explain-it/.
stats writer (2026) 'How to Identify and Avoid Undercoverage Bias in Your Data Collection', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/what-is-undercoverage-bias-and-can-you-provide-examples-to-explain-it/.
[1] stats writer, "How to Identify and Avoid Undercoverage Bias in Your Data Collection," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Identify and Avoid Undercoverage Bias in Your Data Collection. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.