Table of Contents
The process of understanding complex datasets often begins with Exploratory Data Analysis (EDA). One of the most powerful and intuitive tools in the EDA toolkit is the pairs plot, also formally known as a scatterplot matrix. This visualization technique provides a comprehensive overview of the relationships between all possible pairs of variables within a given dataset. Instead of generating individual scatterplots for every combination, the pairs plot efficiently organizes these visualizations into a single, cohesive matrix, making it indispensable for identifying complex structures, potential correlations, and underlying patterns that might influence subsequent statistical modeling. Utilizing powerful libraries within Python, such as Pandas and Seaborn, data scientists can rapidly generate these matrices, transforming raw data into actionable visual insights.
A core function of the pairs plot is the immediate detection of correlation. When variables are plotted against one another, the resulting scatter patterns immediately reveal whether a linear, non-linear, or no relationship exists. Furthermore, the diagonal axis of the matrix typically displays the univariate distribution of each individual variable—often represented as a histogram or kernel density estimate—providing crucial context regarding the data’s shape, central tendency, and variance. This dual focus on both pairwise relationships and individual distributions allows analysts to assess data quality and distributional assumptions simultaneously. Mastering the creation and interpretation of the pairs plot is fundamental for anyone working with multivariate data, offering a streamlined approach to preliminary hypothesis generation.
The Role of Pairs Plots in Data Visualization
The standard approach to visualizing multivariate data can become cumbersome as the number of variables increases. If a dataset contains N variables, generating all pairwise scatterplots requires N * (N – 1) / 2 visualizations. The pairs plot elegantly solves this scalability challenge by condensing all these plots into a single, symmetrical matrix. Each cell off the diagonal represents the relationship between two distinct variables, with the row variable typically mapped to the y-axis and the column variable mapped to the x-axis. This standardized layout ensures consistency and readability, enabling rapid visual comparison across different variable pairs.
In Python, the library of choice for generating high-quality statistical visualizations is typically Seaborn, which is built upon Matplotlib. Seaborn provides the dedicated pairplot() function, designed specifically to automate the creation of this scatterplot matrix. This function handles the heavy lifting of data preparation and plot arrangement, requiring minimal code input from the user. By default, pairplot() is intelligent enough to analyze the input DataFrame and automatically select only the numerical variables for inclusion, excluding categorical features unless explicitly instructed otherwise using arguments like hue. This ease of use makes it the preferred tool for preliminary data exploration.
Setting Up the Python Environment and Data
Before generating any statistical plots, it is essential to ensure that the necessary libraries are imported and the data is loaded correctly. We rely on three foundational Python libraries: Pandas for efficient data manipulation, Matplotlib for foundational plotting capabilities (often implicitly used by Seaborn), and Seaborn for the specialized statistical visualizations. For demonstration purposes, we will utilize the renowned iris dataset, which is conveniently pre-loaded within the Seaborn library, offering four numerical features (sepal length, sepal width, petal length, and petal width) and one categorical target variable (species).
The implementation requires standard importing conventions. Notice how we alias Pandas as pd, Matplotlib’s plotting module as plt, and Seaborn as sns. These aliases are industry standards and help keep the code concise and readable, especially when invoking multiple functions across different packages. After defining the imports, the data loading step is straightforward, retrieving the iris DataFrame directly from the Seaborn repository using the load_dataset() function. This foundational preparation step ensures the code is reproducible and ready for visualization.
Example 1: Basic Pairs Plot for All Variables
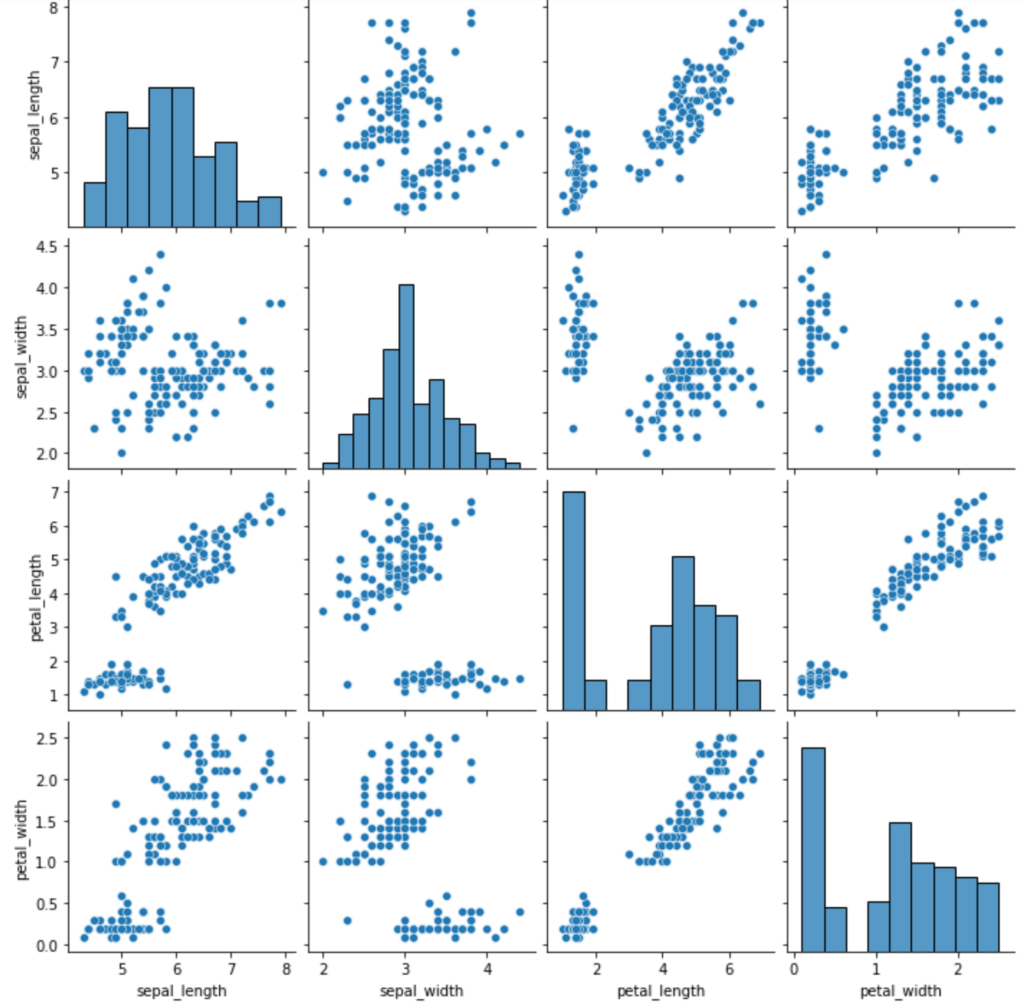
The simplest application of the pairplot() function involves passing the entire DataFrame as the sole argument. This command instructs Seaborn to analyze all columns and generate a matrix showing the pairwise relationships for every numerical variable present. This basic implementation serves as an instantaneous snapshot of the entire dataset structure, crucial for initial Exploratory Data Analysis. The resulting plot will be a square matrix where the number of rows and columns equals the count of numerical features.
The following code block demonstrates how to load the required libraries and immediately generate the default pairs plot for the iris dataset. The subsequent image illustrates the output, which encapsulates the distribution and bivariate relationships for all four primary measurements of the iris flowers.
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns #define dataset iris = sns.load_dataset("iris") #create pairs plot for all numeric variables sns.pairplot(iris)

Interpreting the Pairs Plot Matrix
Interpreting the resulting matrix requires understanding the standard conventions employed by Seaborn. The plot is fundamentally divided into two components: the diagonal elements and the off-diagonal elements. The diagonal cells are reserved for visualizing the univariate distribution of the variable named in that row/column. By default, Seaborn uses a histogram, which provides a clear view of the frequency distribution, skewness, and modality of the data for variables like sepal_length and petal_width. Observing the diagonal helps verify if variables are normally distributed or exhibit unusual characteristics.
The off-diagonal cells contain the scatterplot visualization, displaying the bivariate relationship between two distinct variables. Specifically, the cell at row R and column C shows variable R plotted against variable C. For instance, the cell located in the bottom-left corner of the matrix displays a scatterplot where the values of petal_width are plotted on the y-axis against sepal_length on the x-axis. Observing this pattern allows analysts to quickly gauge the strength and direction of the correlation. A tight cluster of points suggests a strong relationship, whereas a widely dispersed cloud suggests little to no linear association. This holistic view is what makes the pairs plot so effective for initial data assessment.
Example 2: Focusing on Specific Variables
In many analytical scenarios, the full matrix visualization might be unnecessary or overly complex, especially when dealing with datasets containing dozens of features. Fortunately, the pairplot() function allows users to select a subset of variables to include in the visualization, ensuring that only relevant interactions are displayed. This feature is particularly useful when performing focused EDA on a hypothesis concerning a limited number of predictors.
To achieve this focused view, we simply pass a subset of the DataFrame to the pairplot() function. In Python Pandas syntax, this is done by indexing the DataFrame with a list of the desired column names. In the example below, we narrow the focus exclusively to the relationships between sepal_length and sepal_width. Since we are only analyzing two variables, the resulting matrix will be 2×2, showing the distribution of each variable along the diagonal and the scatterplot of their relationship in the off-diagonal cells. This controlled visualization reduces clutter and highlights specific interactions of interest.
sns.pairplot(iris[['sepal_length', 'sepal_width']])

Example 3: Incorporating Categorical Separation (The Hue Argument)
While a basic pairs plot is excellent for examining numerical relationships, its true power in statistical analysis is revealed when a categorical variable is introduced to segment the data visually. This is achieved using the hue argument within the pairplot() function. By specifying a categorical column name—such as species in the iris dataset—Seaborn automatically colors the data points in every single plot (both the scatterplots and the distributions) based on their category membership.
The introduction of the hue argument transforms the interpretation dramatically. Instead of seeing a single mass of points, the analyst can now visually distinguish how the relationships and distributions differ across groups. For instance, in the iris example, coloring by species immediately highlights the distinct clustering of the three species in the scatterplots, demonstrating that petal dimensions are highly effective differentiators. Furthermore, the diagonal histograms become layered or stacked, showing the distinct distribution profiles for each category. This capability is absolutely vital for tasks like classification and assessing feature separation.
The code below demonstrates the inclusion of the hue parameter, resulting in a far more detailed and insightful visualization that clearly separates the three distinct iris species using color coding. This enhanced visualization capability moves beyond simple correlation assessment into multivariate pattern detection.
sns.pairplot(iris, hue='species')

Advanced Customization: Modifying Plot Elements
While the default Seaborn output is highly functional, pairplot() offers extensive customization options to tailor the visualization to specific analytical needs or aesthetic requirements. Analysts can specify different plot types for the off-diagonal (lower and upper triangles) and the diagonal, allowing for sophisticated visual comparisons. For example, one might replace the standard scatterplots in the upper triangle with Kernel Density Estimates (KDEs) to emphasize density concentration rather than individual data points.
The key arguments for customization include diag_kind, kind, corner, and plot_kws. The diag_kind argument controls the diagonal plot type (e.g., 'hist', 'kde', or 'none'). The kind argument determines the type of plot used in the off-diagonal cells (e.g., 'scatter', 'reg' for regression, or 'kde'). Utilizing these parameters allows the analyst to create a visualization that focuses precisely on the required statistical interpretation, such as adding linear regression lines to all scatterplots to immediately quantify the linear relationship or correlation.
Conclusion: Leveraging Pairs Plots for Effective EDA
The pairs plot stands as a cornerstone visualization technique in modern data science, offering unparalleled efficiency in visualizing multivariate data relationships. Its ability to simultaneously display univariate distributions along the diagonal and bivariate scatterplots in the off-diagonal cells provides a comprehensive foundation for Exploratory Data Analysis. Whether used in its simplest form to identify initial linear trends or customized extensively using the hue parameter to differentiate complex groupings, the pairplot() function in Seaborn simplifies what would otherwise be a tedious process of generating multiple individual plots.
By following the examples provided, users can quickly transition from raw data to insightful visualizations, significantly accelerating the process of hypothesis testing and feature selection within their Python environments. Continuous practice with customizing these plots—exploring options like different markers, colors, and diagonal representations—will further solidify proficiency in statistical data visualization, making the pairs plot an indispensable asset in any data professional’s arsenal.
Cite this article
stats writer (2025). How to Easily Create a Pairs Plot in Python. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-to-create-a-pairs-plot-in-python/
stats writer. "How to Easily Create a Pairs Plot in Python." PSYCHOLOGICAL SCALES, 5 Dec. 2025, https://scales.arabpsychology.com/stats/how-to-create-a-pairs-plot-in-python/.
stats writer. "How to Easily Create a Pairs Plot in Python." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/how-to-create-a-pairs-plot-in-python/.
stats writer (2025) 'How to Easily Create a Pairs Plot in Python', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-to-create-a-pairs-plot-in-python/.
[1] stats writer, "How to Easily Create a Pairs Plot in Python," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, December, 2025.
stats writer. How to Easily Create a Pairs Plot in Python. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.