Table of Contents
A complete guide to the diamonds dataset in R provides a comprehensive overview of this rich resource, detailing its variables, underlying structure, and key characteristics necessary for robust data analysis. It serves as an essential resource by demonstrating practical functions, commands, and executable examples for effectively manipulating and visualizing the data within the R environment. Furthermore, such a guide delves into advanced data processing techniques, covering essential steps like handling missing values, performing rigorous Exploratory Data Analysis (EDA), and constructing reliable predictive models. Ultimately, mastering this guide empowers data scientists and analysts to leverage the dataset fully, enabling them to formulate and validate answers to specific research questions concerning the characteristics and pricing of diamonds.
1. The Essential R Resource: Introducing the Diamonds Dataset
The diamonds dataset is a highly valued, high-volume data resource that comes natively built into the popular ggplot2 package in R. It is widely used in data science education and practice as a benchmark for visualization techniques and regression modeling due to its clear structure and the meaningful relationships between its variables.
This extensive dataset captures detailed measurements across 10 distinct variables for an exceptionally large sample size: 53,940 individual diamonds. These variables encompass crucial attributes used in diamond grading, such as price, color, clarity, and physical dimensions. Analyzing this data provides invaluable insights into how various physical characteristics correlate with the final retail price of a diamond.
This tutorial explains how to explore, summarize, and visualize the diamonds dataset, offering a step-by-step methodology for conducting initial data inspection and laying the foundation for advanced statistical modeling in R.
2. Setting Up Your Environment: Loading Dependencies
Since the diamonds dataset is intrinsically linked to the ggplot2 package, this graphics library must be installed and loaded before the data can be accessed. If you have not previously installed ggplot2, you should execute the
install.packages()
command first. This installation is only required once per R environment setup.
Following installation, we use the standard
library()
function to load ggplot2 into the current R session. This critical step ensures that the system recognizes the data object we are about to call and makes all associated plotting functions available for use.
The code below demonstrates the necessary procedure for initializing the environment and loading the required libraries:
# Install ggplot2 if not already installed. This only needs to be run once.
install.packages('ggplot2')
# Load the ggplot2 package into the current R session.
library(ggplot2)3. Initial Data Inspection: Loading and Viewing the Head
With ggplot2 loaded, we can explicitly load the diamonds dataset into our active workspace using the
data()
function. While the data may sometimes be automatically available, this explicit command ensures robust script execution.
To confirm successful loading and to get a preliminary feel for the data structure, we use the
head()
function. This crucial step in Exploratory Data Analysis (EDA) allows us to visually inspect the first six observations, confirming variable types, names, and checking for initial data quality issues.
Observe the column names and the variety of values present, which include numerical measurements (like carat and price) and categorical factors (cut, color, and clarity):
Once we’ve loaded ggplot2, we use the data() function to load the diamonds dataset:
data(diamonds)We can take a look at the first six rows of the dataset by using the head() function:
# View first six rows of the diamonds dataset to inspect structure
head(diamonds)
carat cut color clarity depth table price x y z
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.290 Premium I VS2 62.4 58 334 4.2 4.23 2.63
5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
4. Statistical Summarization using R’s summary() Function
To quickly obtain a comprehensive understanding of all variables, we employ the powerful summary() function in R. This function automatically adjusts its output based on the variable type: providing Descriptive Statistics for numerical columns and frequency counts for categorical (factor) columns.
This rapid summarization step is paramount in EDA as it immediately highlights the central tendency, spread, and potential boundary issues (like outliers or zero values in dimension measurements) that need further investigation.
For example, reviewing the price variable summary helps us understand the typical cost of a diamond in the dataset, while the summary of the carat variable reveals the typical size distribution.
We can use the summary() function to quickly summarize each variable in the dataset:
# Summarize diamonds dataset to inspect descriptive statistics
summary(diamonds)
carat cut color clarity depth
Min. :0.2000 Fair : 1610 D: 6775 SI1 :13065 Min. :43.00
1st Qu.:0.4000 Good : 4906 E: 9797 VS2 :12258 1st Qu.:61.00
Median :0.7000 Very Good:12082 F: 9542 SI2 : 9194 Median :61.80
Mean :0.7979 Premium :13791 G:11292 VS1 : 8171 Mean :61.75
3rd Qu.:1.0400 Ideal :21551 H: 8304 VVS2 : 5066 3rd Qu.:62.50
Max. :5.0100 I: 5422 VVS1 : 3655 Max. :79.00
J: 2808 (Other): 2531
table price x y z
Min. :43.00 Min. : 326 Min. : 0.000 Min. : 0.000 Min. : 0.000
1st Qu.:56.00 1st Qu.: 950 1st Qu.: 4.710 1st Qu.: 4.720 1st Qu.: 2.910
Median :57.00 Median : 2401 Median : 5.700 Median : 5.710 Median : 3.530
Mean :57.46 Mean : 3933 Mean : 5.731 Mean : 5.735 Mean : 3.539
3rd Qu.:59.00 3rd Qu.: 5324 3rd Qu.: 6.540 3rd Qu.: 6.540 3rd Qu.: 4.040
Max. :95.00 Max. :18823 Max. :10.740 Max. :58.900 Max. :31.800 5. Interpreting Descriptive Statistics and Frequency Counts
The summary() output is structured to provide deep insights quickly. For all numerical variables, the core metrics define the distribution’s five-number summary plus the mean, allowing analysts to check for skewness (e.g., comparing Mean vs. Median) and data bounds.
For each of the numeric variables we can see the following information:
- Min: The absolute minimum value recorded.
- 1st Qu: The value of the first quartile (Q1, 25th percentile).
- Median: The middle value (Q2, 50th percentile).
- Mean: The arithmetic average of all values.
- 3rd Qu: The value of the third quartile (Q3, 75th percentile).
- Max: The absolute maximum value recorded.
For the categorical variables in the dataset (cut, color, and clarity) we observe a frequency count of each level. This is crucial for understanding the distribution of diamond quality attributes within the sample.
For example, the summary for the cut variable reveals that the highest proportion of diamonds are graded as Ideal, reflecting high-quality manufacturing or a bias in the data collection process:
- Fair: This value occurs 1,610 times.
- Good: This value occurs 4,906 times.
- Very Good: This value occurs 12,082 times.
- Premium: This value occurs 13,791 times.
- Ideal: This value occurs 21,551 times.
6. Determining Dataset Dimensions and Variable Names
To confirm the total number of observations and variables, we use the
dim()
function. This function returns the dimensions of the dataset, expressed as rows followed by columns, providing assurance regarding the scale of the data being analyzed.
The execution confirms the dataset’s substantial size, which is critical for statistical power.
We can use the dim() function to get the dimensions of the dataset in terms of number of rows and number of columns:
# Display rows and columns
dim(diamonds)
[1] 53940 10
We can see that the dataset has 53,940 rows and 10 columns.
Furthermore, clear referencing of variables is mandatory for coding. The
names()
function is used to explicitly display all column names in the data frame, ensuring correct syntax when calling individual variables for plotting or modeling.
We can also use the names() function to display the column names of the data frame:
# Display column names
names(diamonds)
[1] "carat" "cut" "color" "clarity" "depth" "table" "price" "x"
[9] "y" "z"
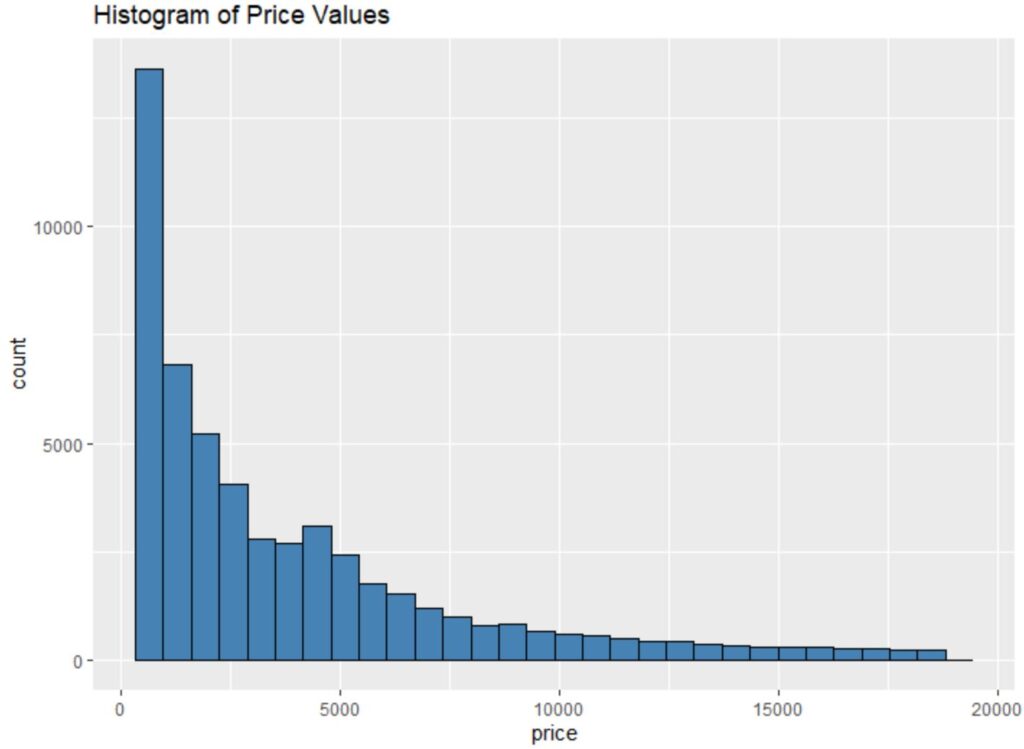
7. Visualizing Distributions: Creating the Price Histogram
Visualizing data is the most intuitive way to perform Exploratory Data Analysis. Using the ggplot2 package, we can create compelling plots, starting with a histogram to observe the distribution of a single continuous variable.
For example, analyzing the price variable using
geom_histogram()
helps us understand the concentration of prices. Given the wide range, we often see a strong positive skew, meaning most diamonds are inexpensive, with a long tail extending towards high values.
The command below generates a histogram for diamond prices, specifying aesthetics (
aes
) and customizing the visual appearance:
We can also create some plots to visualize the values in the dataset.
For example, we can use the geom_histogram() function to create a histogram of the values for a certain variable:
# Create histogram of values for price
ggplot(data=diamonds, aes(x=price)) +
geom_histogram(fill="steelblue", color="black") +
ggtitle("Histogram of Price Values")

8. Exploring Bivariate Relationships with Scatterplots and Boxplots
To investigate the correlation between two continuous variables, such as carat weight and price, we utilize the
geom_point()
function to generate a scatterplot. This visualization quickly confirms the expected strong positive correlation, where heavier diamonds generally command higher prices.
We can further segment this relationship by mapping a categorical variable, like cut quality, to the color aesthetic. This layering technique provides granular insight into how non-numerical attributes influence the overall trend.
We can also use the geom_point() function to create a scatterplot of any pairwise combination of variables:
# Create scatterplot of carat vs. price, using cut as color variable
ggplot(data=diamonds, aes(x=carat, y=price, color=cut)) +
geom_point()

Finally, to compare the distribution of a continuous variable (price) across the levels of a categorical variable (cut), the
geom_boxplot()
function is indispensable. The boxplot concisely displays the five-number summary for each group, revealing differences in median price, interquartile range, and the presence of outliers per cut quality.
We can also use the geom_boxplot() function to create a boxplot of one variable grouped by another variable:
# Create boxplot of price, grouped by cut
ggplot(data=diamonds, aes(x=cut, y=price)) +
geom_boxplot(fill="steelblue")

9. Summary of Key Insights and Further Steps
By using these powerful functions from ggplot2—from simple summaries to complex visualizations—we can glean a great deal of information about the variables and their relationships within the diamonds dataset. This structured approach, encompassing data loading, statistical review, and visualization, forms a complete and repeatable methodology for any new data exploration task.
Proficiency with the diamonds dataset is a fundamental skill for any data professional working with R, providing a solid foundation for advanced regression analysis and predictive modeling centered on the factors that determine diamond pricing.
The following tutorials explain how to explore other datasets in R:
Cite this article
stats writer (2025). How to Analyze the Diamonds Dataset in R: A Step-by-Step Guide. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/what-is-a-complete-guide-to-the-diamonds-dataset-in-r/
stats writer. "How to Analyze the Diamonds Dataset in R: A Step-by-Step Guide." PSYCHOLOGICAL SCALES, 30 Nov. 2025, https://scales.arabpsychology.com/stats/what-is-a-complete-guide-to-the-diamonds-dataset-in-r/.
stats writer. "How to Analyze the Diamonds Dataset in R: A Step-by-Step Guide." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/what-is-a-complete-guide-to-the-diamonds-dataset-in-r/.
stats writer (2025) 'How to Analyze the Diamonds Dataset in R: A Step-by-Step Guide', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/what-is-a-complete-guide-to-the-diamonds-dataset-in-r/.
[1] stats writer, "How to Analyze the Diamonds Dataset in R: A Step-by-Step Guide," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, November, 2025.
stats writer. How to Analyze the Diamonds Dataset in R: A Step-by-Step Guide. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.