Table of Contents
The two-sample t-test, also known as the independent samples t-test, represents one of the most fundamental tools in the field of inferential statistics. This analytical method is specifically designed to evaluate whether the arithmetic means of two distinct, independent groups are significantly different from one another. In many scientific and business contexts, researchers are not just interested in describing the data they have collected but in making broader generalizations about populations. For instance, if a pharmaceutical company wants to test the efficacy of a new drug, they might compare a treatment group against a control group. By utilizing the t-test, researchers can determine if the observed differences in outcomes are likely due to the treatment itself or simply the result of random sampling error.
Mathematically, the two-sample t-test relies heavily on the t-distribution, which is a theoretical probability distribution that is similar to the normal distribution but features heavier tails. This characteristic makes it particularly useful when dealing with smaller sample sizes where the standard deviation of the entire population is unknown and must be estimated from the sample data. When sample sizes are large, the t-distribution eventually converges to the normal distribution, but for smaller groups, the t-test provides a more conservative and accurate estimate of statistical significance. By comparing the calculated t-statistic against a critical value from the t-table, or by deriving a p-value, analysts can confidently decide whether to reject or fail to reject their starting assumptions.
The basic formula for this test is expressed as t = (x1 – x2) / √(s1²/n1 + s2²/n2), where x1 and x2 are the sample means, s1 and s2 represent the standard deviation of each group, and n1 and n2 denote the respective sample sizes. This formula essentially scales the difference between the two sample means by the standard error of that difference. If the difference between the means is large relative to the variability within the groups, the resulting t-score will be high, increasing the likelihood that the difference is statistically significant. Consider a scenario where a researcher examines the test scores of students using two different study methods. By collecting a sample of 20 students for each method and applying the formula, the researcher can objectively quantify the effectiveness of one method over the other, moving beyond mere anecdotal evidence to robust data analysis.
Two Sample t-test: Definition, Formula, and Example
The Foundational Definition of the Two-Sample T-Test
A two-sample t-test serves as a robust statistical procedure employed to investigate whether the underlying means of two separate populations are significantly different. This test is a staple in research because it allows for the comparison of two groups that have no overlap, meaning the individuals in the first group are entirely distinct from those in the second group. This distinction is what separates the independent t-test from the paired t-test, where the same subjects are measured twice. By focusing on independent groups, researchers can analyze the effects of different conditions, demographics, or interventions across a broad spectrum of scientific disciplines.
The primary goal of this statistical methodology is to provide a framework for hypothesis testing. In every study, we begin with the assumption that there is no difference between the groups being studied. The t-test then uses the sample data to calculate the probability that the observed difference occurred purely by chance. If that probability—known as the p-value—is sufficiently low, we conclude that the difference is “statistically significant.” This process is vital for ensuring that scientific conclusions are based on evidence rather than random fluctuations in the data. Understanding the mechanics of this test is essential for anyone looking to interpret academic papers or conduct their own quantitative research.
This comprehensive guide will delve deep into the mechanics of the two-sample t-test, covering everything from the theoretical motivations to the practical application of the formula. We will explore the following key areas:
- The underlying motivation for conducting a comparison between two independent groups.
- A detailed breakdown of the mathematical formula used to generate the test statistic.
- The critical assumptions that must be satisfied to ensure the results of the test are valid and reliable.
- A step-by-step example involving biological data to illustrate how the test works in a real-world setting.
- How to interpret the final results to make informed decisions based on statistical evidence.
The Core Motivation for Comparing Independent Groups
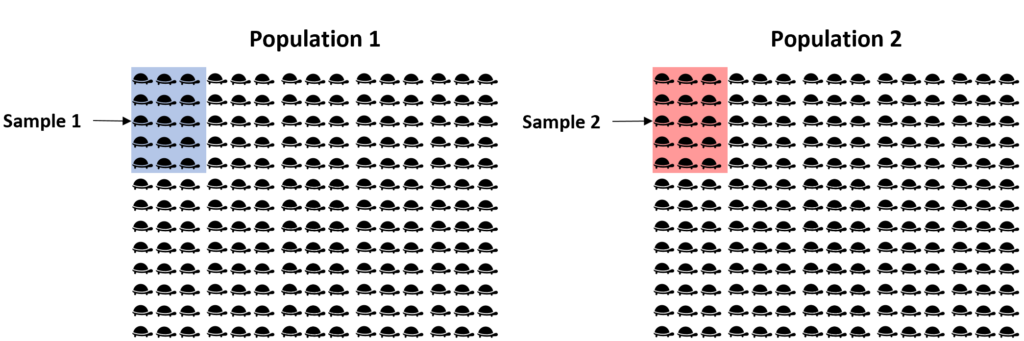
To understand the necessity of the two-sample t-test, consider the practical limitations of modern research. Imagine a biologist who suspects that two different species of turtles living in separate regions have different average body weights. In an ideal world, the researcher would weigh every single turtle in both populations to find the exact population mean. However, given that there could be tens of thousands of turtles spread across vast geographical areas, conducting a full census is physically impossible, financially prohibitive, and logically unnecessary. This is where the power of statistical sampling becomes apparent.
Rather than measuring every individual, the researcher selects a simple random sample from each species. By weighing a manageable number of turtles—for example, 15 from each group—the researcher can calculate the sample mean for both populations. While these sample means provide an estimate of the true population averages, they are rarely identical. Even if the two species actually had the exact same average weight, the two samples would likely show a slight difference due to the inherent variability of nature. The central challenge for the researcher is determining whether the measured difference is large enough to suggest a real biological distinction or if it is just a minor discrepancy caused by the luck of the draw in the sampling process.

The two-sample t-test provides the mathematical rigor needed to solve this dilemma. It helps us navigate the boundary between “noise” and “signal” in our data. By accounting for the variance within each sample and the size of the groups, the test assesses statistical significance. Without this tool, researchers would be forced to make subjective guesses about their data, which could lead to incorrect conclusions and wasted resources. By using the t-test, we can attach a level of confidence to our findings, stating whether the observed weight difference in our turtles is a finding that likely applies to the entire species population.
Formulating Hypotheses for the Two-Sample T-Test
Every two-sample t-test begins with the formulation of two competing hypotheses: the null hypothesis and the alternative hypothesis. The null hypothesis, denoted as H0, is the default assumption that there is no effect or no difference between the two groups. In the context of our turtle study, the null hypothesis would state that the mean weight of species 1 is exactly equal to the mean weight of species 2. We assume this is true until we have enough evidence to prove otherwise, much like the “innocent until proven guilty” principle used in legal systems.
- H0: μ1 = μ2 (The population means of the two groups are equal).
The alternative hypothesis, denoted as H1, represents the claim that the researcher actually wants to investigate. Depending on the goals of the study, the alternative hypothesis can take three different forms. A two-tailed test is used when we simply want to know if the means are different, regardless of which one is larger. A left-tailed test is used if we specifically suspect the first mean is smaller than the second, while a right-tailed test is used if we suspect the first mean is larger. Choosing the correct tail is crucial, as it affects how the p-value is calculated and interpreted.
- H1 (two-tailed): μ1 ≠ μ2 (The two population means are not equal).
- H1 (left-tailed): μ1 < μ2 (The mean of population 1 is less than population 2).
- H1 (right-tailed): μ1 > μ2 (The mean of population 1 is greater than population 2).
Selecting the appropriate hypothesis structure is the first step in the statistical inference process. It defines the “burden of proof” required to reject the null hypothesis. Most general research uses the two-tailed approach to be as objective as possible, ensuring that an unexpected difference in either direction is captured. However, in specific clinical trials or industrial quality control, one-tailed tests might be preferred if the direction of the change is the only outcome of interest. Regardless of the choice, the hypothesis must be clearly stated before the data is analyzed to maintain the integrity of the scientific method.
The Mathematical Formula and Pooled Variance
To calculate the test statistic, we use a specific formula that incorporates the means, variances, and sample sizes of both groups. The resulting value, the t-statistic, represents the number of standard errors by which the two sample means differ. The formula is structured as follows:
Test statistic: (x1 – x2) / sp(√1/n1 + 1/n2)
In this equation, x1 and x2 are the sample means, while n1 and n2 represent the number of observations in each sample. The term sp is the pooled standard deviation, which is a weighted average of the standard deviations of the two samples. Using a pooled estimate is appropriate when we assume that the two populations have similar variances. By pooling the data, we create a more stable estimate of the overall variability within the populations, which increases the statistical power of the test. The formula for the pooled standard deviation is:
sp = √ ((n1-1)s1² + (n2-1)s2² / (n1+n2-2))
The denominator of the test statistic represents the standard error of the difference between the means. It quantifies how much we expect the difference between the two sample means to fluctuate due to random chance. If the actual difference (x1 – x2) is much larger than this standard error, the t-statistic will be large, suggesting that the difference is unlikely to be the result of chance alone. This mathematical structure is what allows us to convert raw data into a standardized score that can be compared against a t-distribution table.
Finally, we must consider the degrees of freedom (df), which for a two-sample t-test is calculated as n1 + n2 – 2. The degrees of freedom adjust the t-distribution’s shape to account for the sample size; as the degrees of freedom increase, the t-distribution becomes narrower and more similar to a normal distribution. By comparing our calculated t-value with the degrees of freedom and our chosen significance level (usually 0.05), we can determine the p-value. If the p-value is lower than the significance level, we have sufficient evidence to reject the null hypothesis and conclude that a significant difference exists.
Critical Assumptions for Valid T-Test Results
For the results of a two-sample t-test to be accurate and reliable, several underlying assumptions must be satisfied. If these assumptions are violated, the resulting p-value may be misleading, potentially leading to Type I errors (false positives) or Type II errors (false negatives). The first and most critical assumption is independence. This means that the observations in the first sample must be completely independent of the observations in the second sample. There should be no relationship or pairing between the subjects in the two groups, as such dependencies would require a different statistical approach, such as a paired t-test.
The second major assumption is normality. This requires that the data in both populations follow an approximately normal distribution. While the t-test is relatively robust to minor deviations from normality, especially with larger sample sizes (thanks to the Central Limit Theorem), extreme outliers or highly skewed data can distort the results. Researchers often use visual tools like Q-Q plots or formal tests like the Shapiro-Wilk test to verify this assumption before proceeding with the t-test. If the data is severely non-normal, non-parametric alternatives like the Mann-Whitney U test might be more appropriate.
The third assumption is the homogeneity of variance, also known as homoscedasticity. This assumes that the two populations being compared have approximately the same variance. If one group is much more spread out than the other, the standard pooled t-test formula becomes unreliable. In cases where this assumption is violated, statisticians recommend using Welch’s t-test, which adjusts the degrees of freedom to account for unequal variances. Finally, the data should be collected using a simple random sample to ensure that the sample is representative of the broader population, minimizing selection bias.
A Practical Example: Comparing Turtle Weights
To illustrate the application of these concepts, let us return to our study of turtle weights. We want to determine if there is a significant difference in the mean weight between two species. We decide to set our significance level (alpha) at 0.05. This means we are willing to accept a 5% risk of concluding that a difference exists when it actually does not. By following a structured 5-step process, we can move from raw data to a definitive scientific conclusion.
Step 1: Gather the sample data. In our study, we successfully collect data from two independent groups of turtles. The results are summarized below:
- Sample 1: n1 = 40, x1 = 300 grams, s1 = 18.5 grams
- Sample 2: n2 = 38, x2 = 305 grams, s2 = 16.7 grams
Step 2: Define the hypotheses. We establish our testing framework by stating our null hypothesis and alternative hypothesis. We are performing a two-tailed test because we are interested in any significant weight difference, regardless of which species is heavier.
- H0: μ1 = μ2 (Mean weights are equal).
- H1: μ1 ≠ μ2 (Mean weights are not equal).
Step 3: Calculate the test statistic t. First, we calculate the pooled standard deviation (sp) to combine the variability of both groups. Using the formula provided earlier, we find: sp = √ ((40-1)18.5² + (38-1)16.7² / (40+38-2)) = 17.647. Next, we plug this value into the t-test formula: t = (300-305) / 17.647(√1/40 + 1/38) = -1.2508. This negative value simply indicates that the mean of the first group is lower than the mean of the second group.
Step 4: Calculate the p-value. Using the calculated t-statistic of -1.2508 and the degrees of freedom (40 + 38 – 2 = 76), we consult a p-value calculator or a statistical table. The resulting p-value is 0.21484. This value represents the probability of observing a difference of 5 grams (or more) if the true population means were actually identical.
Step 5: Draw a conclusion. We compare our p-value (0.21484) to our significance level (0.05). Since the p-value is significantly higher than 0.05, we fail to reject the null hypothesis. In plain language, the difference we observed is not large enough to be considered statistically significant. We do not have sufficient evidence to claim that these two species of turtles have different average weights; the 5-gram difference is likely just due to sampling variability.
Implementation Across Modern Statistical Software
While performing these calculations by hand is excellent for understanding the logic of the two-sample t-test, modern researchers almost always use software to handle large datasets and complex calculations. Tools like Microsoft Excel provide built-in functions such as T.TEST that can quickly return a p-value. For more advanced social science research, SPSS and Stata offer comprehensive menus for conducting t-tests while also checking for assumptions like the homogeneity of variance through Levene’s test.
In the world of data science and programming, Python and R are the gold standards. Using libraries like SciPy in Python allows for the execution of a t-test in a single line of code, providing detailed outputs including confidence intervals and effect sizes. Even handheld technology, such as the TI-84 Calculator, includes dedicated statistical menus that walk students through the process of inputting sample data and calculating test statistics. These tools have made statistical testing more accessible than ever before.
Regardless of the software chosen, the fundamental principles remain the same. The user must still ensure that the data meets the necessary assumptions and that the hypotheses are correctly formulated. Software can perform the math, but the researcher must provide the interpretation. By mastering the two-sample t-test, you gain the ability to look at two groups and determine with mathematical certainty whether the differences you see are real or just a trick of the data. This skill is invaluable in a world increasingly driven by data-driven decision-making.
The following tutorials explain how to perform a two-sample t-test using different statistical programs:
How to Perform a Two Sample t-test in Excel
How to Perform a Two Sample t-test in SPSS
How to Perform a Two Sample t-test in Stata
How to Perform a Two Sample t-test in Python
How to Perform a Two Sample t-test on a TI-84 Calculator
Cite this article
stats writer (2026). How to Perform a Two Sample T-Test: Definition, Formula, and Example. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/what-is-the-definition-formula-and-example-of-a-two-sample-t-test/
stats writer. "How to Perform a Two Sample T-Test: Definition, Formula, and Example." PSYCHOLOGICAL SCALES, 13 Mar. 2026, https://scales.arabpsychology.com/stats/what-is-the-definition-formula-and-example-of-a-two-sample-t-test/.
stats writer. "How to Perform a Two Sample T-Test: Definition, Formula, and Example." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/what-is-the-definition-formula-and-example-of-a-two-sample-t-test/.
stats writer (2026) 'How to Perform a Two Sample T-Test: Definition, Formula, and Example', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/what-is-the-definition-formula-and-example-of-a-two-sample-t-test/.
[1] stats writer, "How to Perform a Two Sample T-Test: Definition, Formula, and Example," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Perform a Two Sample T-Test: Definition, Formula, and Example. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.