Table of Contents
In the realm of data analysis, the ability to quickly summarize large volumes of information and present findings visually is paramount. The Pandas library in Python offers sophisticated tools that streamline this process, particularly through the combination of its powerful grouping mechanism and its built-in plotting functionalities. When working with complex datasets, analysts often need to segment data based on categorical variables and then visualize how different segments behave over time or across different metrics. This seamless integration of data manipulation and graphical output is what makes the combination of Pandas Groupby and Pandas Plot an essential technique for any data scientist working with a Pandas DataFrame.
The core utility of this approach lies in its efficiency. Instead of manually filtering subsets of data and generating individual charts for each group, Pandas allows the user to execute both the aggregation and the visualization steps in a concise, chained operation. This not only reduces the amount of code required but also ensures that the resulting visualizations are consistent and directly comparable. The output, whether a single plot displaying multiple series or several distinct subplots, facilitates rapid identification of critical patterns, outliers, and trends that might otherwise be obscured in raw tabular data. Mastering this technique is fundamental for deriving actionable insights from real-world datasets, which are invariably messy and require significant preparatory work.
This guide delves into the practical application of these methods, demonstrating two primary strategies for visualizing grouped data: plotting all groups on a single axis for direct comparison, and generating individual subplots for focused examination of each group. Both methods are invaluable, depending on the specific analytical goals. By preserving the original structure of the underlying code examples, we aim to provide a practical, hands-on understanding of how to leverage the full potential of Pandas for effective data visualization.
The Power of Pandas Groupby
The groupby() function is arguably one of the most important operations within the Pandas DataFrame ecosystem, embodying the “split-apply-combine” paradigm. This three-step process is crucial for data aggregation: first, the data is split into partitions based on the values of one or more keys (columns); second, a function (like summing, averaging, or plotting) is applied independently to each partition; and finally, the results are combined back into a new structure. When this process is coupled with visualization, the “apply” step becomes the plotting function, enabling immediate graphical representation of the grouped results without requiring an intermediate aggregation table.
Traditional data processing often requires creating pivot tables or intermediate summarized dataframes before plotting can occur. While such methods are valid, chaining the groupby() call directly into the plot() method significantly simplifies the workflow. When Pandas encounters a chained operation like df.groupby('category')['value'].plot(), it understands that the resulting series for each group should be treated as a distinct data series suitable for plotting. This automatic handling of multiple series is particularly advantageous for time-series analysis or tracking performance metrics across different segments, such as tracking sales of various products over a specific period.
Effective use of groupby requires careful consideration of the grouping column(s) and the target columns. The grouping column must be categorical or convertible into discrete groups. The target column, usually numerical, is the data we wish to observe. In the context of plotting, if we group by ‘Product’ and plot ‘Sales’, Pandas will create a separate line for each unique product, using the index (often time or day) as the x-axis reference. This highly flexible structure ensures that complex segmentation tasks are handled efficiently, setting the stage for clear, insightful visualizations.
Integrating Groupby with Visualization: The Plot Method
The plot() method in Pandas acts as a convenient wrapper around the powerful Matplotlib library, offering a simplified and highly accessible interface for generating charts directly from a Pandas DataFrame or Series object. When plot() is called immediately after a Pandas Groupby operation, it intelligently interprets the resulting grouped data structure. Instead of plotting a single resulting series (as would happen after a typical aggregation like sum()), it creates a plot for every unique group identified by the grouping key.
The visualization generated by this chaining technique typically defaults to a line chart, which is highly suitable for visualizing trends across a sequential index (like time or days). However, the versatility of the plot() method allows users to specify different chart types, such as bar plots, histograms, or scatter plots, using the kind argument. For example, while plotting sales trends typically utilizes kind='line', visualizing the distribution of a grouped metric might require kind='hist'. The seamless transition from grouped data preparation to visual output minimizes computational steps and maximizes analytical speed.
Furthermore, controlling the aesthetic elements, such as legends and subplots, is critical for producing publishable results. Pandas provides arguments within the plot() function, such as legend=True, to automatically label the distinct series based on the grouping key. We will explore two key strategies for visual output: the first involves plotting all grouped lines onto a single coordinate system, which is ideal for comparing relative performance; the second utilizes the subplots=True argument to dedicate a separate chart to each group, thereby isolating and simplifying the analysis of individual trends.
Prerequisites: Setting Up the Example DataFrame
To effectively demonstrate the methods of grouping and plotting, we must first establish a representative dataset. The following example utilizes a simple Pandas DataFrame tracking the daily sales figures for two distinct products, ‘A’ and ‘B’, over a five-day period. This structure mimics common business datasets where metrics are tracked sequentially across different categorical segments. The initial setup requires importing the Pandas library and defining the data dictionary containing ‘day’, ‘product’, and ‘sales’ columns.
The creation of the DataFrame is an essential first step. The ‘day’ column serves as our temporal index, ‘product’ is the categorical variable we will use for grouping, and ‘sales’ is the numerical variable we intend to visualize the trends of. Note that the ‘day’ values repeat, which is necessary because each product has sales recorded for each day. This specific structure, where the temporal component is a regular column rather than the index, informs how we structure our subsequent groupby and set_index operations.
We begin by generating and viewing the DataFrame. This foundational code block ensures reproducibility and clarity before we dive into the visualization methods. Note the utilization of standard Python practices for defining the DataFrame structure.
We will use the following Pandas DataFrame for all subsequent examples:
import pandas as pd #create DataFrame df = pd.DataFrame({'day': [1, 2, 3, 4, 5, 1, 2, 3, 4, 5], 'product': ['A', 'A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'B'], 'sales': [4, 7, 8, 12, 15, 8, 11, 14, 19, 20]}) #view DataFrame df day product sales 0 1 A 4 1 2 A 7 2 3 A 8 3 4 A 12 4 5 A 15 5 1 B 8 6 2 B 11 7 3 B 14 8 4 B 19 9 5 B 20
Visualization Strategy 1: Merging Groups onto a Single Plot
The first method focuses on generating a single plot where the trends for all grouped segments are overlaid. This strategy is highly effective when the primary goal is to compare the performance or magnitude of different groups directly. In our case, we want to see how the sales of Product A compare to Product B over the five-day period on the same set of axes. To achieve this, a critical prerequisite is setting the desired sequential variable (‘day’) as the index of the Pandas DataFrame before the plotting operation is initiated.
By setting ‘day’ as the index using the set_index() function, we explicitly tell Pandas which column should serve as the shared x-axis for all plotted series. The subsequent chained operation—calling Pandas Groupby on ‘product’ and then calling Pandas Plot on the ‘sales’ column—automatically generates separate lines for each product. The inclusion of the legend=True argument is vital here, as it ensures that each line is correctly identified by its corresponding ‘product’ label, maintaining clarity despite the density of the overlapping data.
This approach provides an immediate visual comparison. For instance, in the resulting chart, one can instantly discern if Product B consistently outsells Product A, or if there are specific days where their trends converge or diverge significantly. This method is concise and leverages the internal efficiency of Pandas’ visualization integration. Below is the code implementation for this first strategy, followed by the resulting graphical output.
Method 1: Group By & Plot Multiple Lines in One Plot
The following code shows how to first define the index and then group the DataFrame by the ‘product’ variable to plot the ‘sales’ of each product within a single chart:
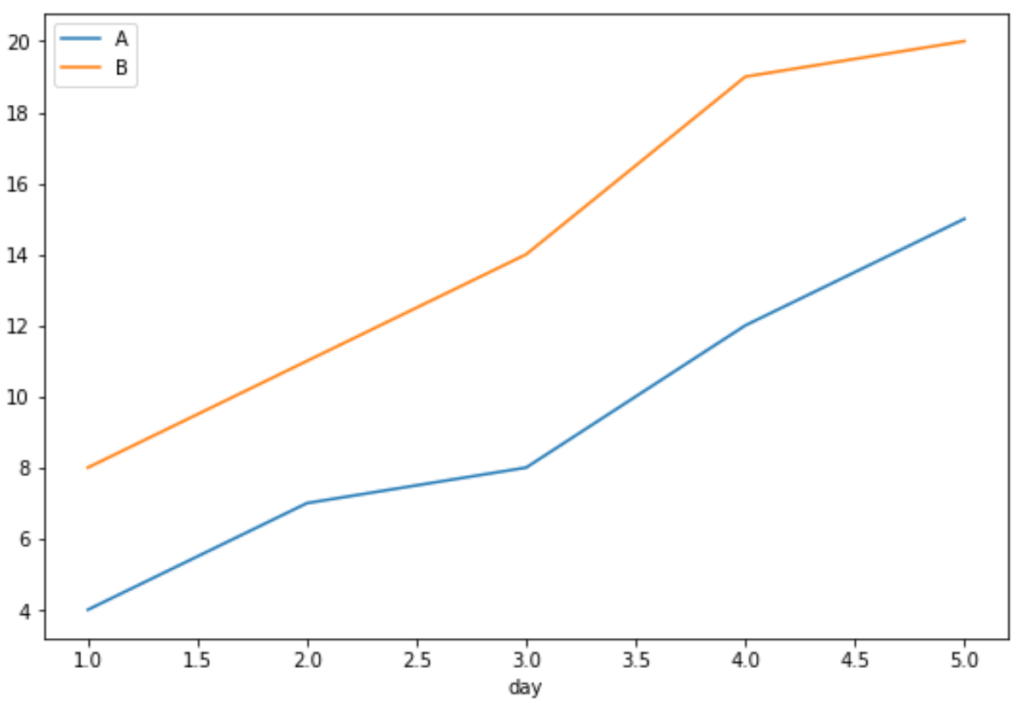
#define index column df.set_index('day', inplace=True) #group data by product and display sales as line chart df.groupby('product')['sales'].plot(legend=True)

In this combined visualization, the x-axis displays the progression by day, the y-axis quantifies the sales volume, and each distinct line represents the sales trend for an individual product segment. Observing this output clearly illustrates the relative performance and scaling trajectory of Product A versus Product B over the measured period, confirming that Product B generally maintains higher sales figures.
Visualization Strategy 2: Isolating Groups in Individual Subplots
While plotting all groups on one axis is useful for comparison, visualizing them in individual subplots is often superior for analyzing the intrinsic trends and characteristics of each group without distraction from other data series. This technique, achieved by setting the subplots=True argument within the plot() function, ensures that each product’s sales trajectory is isolated in its own dedicated graph. This separation is particularly beneficial when the scales of the groups vary widely, or when the sheer number of groups would make a single plot cluttered and unreadable.
However, executing this strategy directly after a groupby operation can sometimes lead to an incorrect plot structure, especially if the index is not perfectly aligned for pivoting. A more robust and highly recommended technique for creating separate subplots from grouped data involves reshaping the Pandas DataFrame using the pivot_table function. The pivot_table rearranges the data such that the grouping variable (‘product’) becomes the column header, the sequential variable (‘day’) remains the index, and the values (‘sales’) populate the matrix.
Once the data is pivoted into this wide format, calling plot(subplots=True) treats each column (‘Product A’ sales, ‘Product B’ sales) as a separate variable and automatically assigns each one to its own subplot. This systematic approach guarantees clean separation and allows for focused analysis of each series. Note that before pivoting, we must use reset_index() to convert the ‘day’ column from the index (if it was set in Method 1) back into a regular column, ensuring it can be correctly assigned as the index argument in the pivot_table function.
Method 2: Group By & Plot Lines in Individual Subplots
This example demonstrates reshaping the data using the pivot_table function and subsequently generating dedicated subplots for each product’s sales trend:
pd.pivot_table(df.reset_index(), index='day', columns='product', values='sales' ).plot(subplots=True)

As clearly visualized above, the first plot provides a detailed view of the sales progression for Product A, while the second plot exclusively illustrates the sales trajectory for Product B. This separation allows for close inspection of the individual growth rate and linearity of each product’s performance, preventing any visual interference that may occur when series share a single axis.
Advanced Customization: Controlling Subplot Layout
While the default subplots=True argument places the generated plots one above the other in a vertical stack, analysts frequently require more control over the grid structure, especially when dealing with a moderate number of groups (e.g., 4 to 9 groups). Pandas, leveraging Matplotlib capabilities, allows explicit definition of the layout using the layout parameter within the plot() function. This parameter accepts a tuple specifying the desired number of rows and columns for the grid.
Customizing the layout is crucial for optimizing the use of screen real estate and improving the visual flow of the presentation. For instance, if we have only two groups (as in our example) but prefer a side-by-side comparison rather than a vertical one, setting layout=(1, 2) instructs the plot function to arrange the subplots in a single row with two columns. If we had six products, setting layout=(2, 3) would arrange them in two rows and three columns, providing a compact and easily scannable matrix.
It is important to remember that the layout parameter is only effective when subplots is set to True. This advanced customization capability transforms the standard plot output into a sophisticated reporting tool, enabling the creation of dashboards that simultaneously display numerous segmented trends in an organized manner. This level of control is essential for professional data visualization and reporting.
Advanced Customization: Specifying Subplot Layout
For example, we could specify the subplots to be arranged in a grid with one row and two columns for better horizontal viewing:
pd.pivot_table(df.reset_index(), index='day', columns='product', values='sales' ).plot(subplots=True, layout=(1,2))

Best Practices for Grouped Data Visualization
When implementing Pandas Groupby and Pandas Plot in production environments, adhering to several best practices ensures that the resulting data visualization is accurate, informative, and scalable. First and foremost, always ensure that the index of the DataFrame is correctly set to the variable that represents the continuous or sequential flow (like ‘day’ or ‘timestamp’). A misconfigured index will lead to plots where lines are broken or connectivity is nonsensical, undermining the entire analysis.
Secondly, be deliberate in choosing between single plots and subplots. While single plots are excellent for comparing relative magnitudes, they fail when groups exhibit dramatically different scales—a product selling millions versus a product selling dozens—as the lower-scaled data will appear flat. Subplots, conversely, handle scale differences well but require manual comparison across separate charts. Analysts should select the method that best highlights the specific relationships or trends they are trying to communicate.
Finally, utilize the extensive customization options offered by Matplotlib, which Pandas seamlessly integrates. Adding clear titles, labeling axes, customizing colors for better contrast, and annotating significant data points transform basic plots into persuasive analytical artifacts. For complex datasets, pre-filtering or simplifying the number of groups before visualization is crucial; plotting fifty distinct lines on one chart is almost always counterproductive. By adhering to these principles, the combined power of Pandas aggregation and visualization becomes a reliable pillar of data storytelling.
The following tutorials explain how to create other common visualizations in pandas:
Cite this article
stats writer (2025). How to Group and Plot Data Easily with Pandas. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/pandas-how-to-use-groupby-and-plot/
stats writer. "How to Group and Plot Data Easily with Pandas." PSYCHOLOGICAL SCALES, 2 Dec. 2025, https://scales.arabpsychology.com/stats/pandas-how-to-use-groupby-and-plot/.
stats writer. "How to Group and Plot Data Easily with Pandas." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/pandas-how-to-use-groupby-and-plot/.
stats writer (2025) 'How to Group and Plot Data Easily with Pandas', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/pandas-how-to-use-groupby-and-plot/.
[1] stats writer, "How to Group and Plot Data Easily with Pandas," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, December, 2025.
stats writer. How to Group and Plot Data Easily with Pandas. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.