Table of Contents
The ability to restructure data efficiently is paramount in statistical analysis and reporting. The PROC TRANSPOSE is a powerful SAS procedure specifically designed to convert a dataset between two crucial organizational structures: the wide format and the long format. This process is commonly referred to as pivoting or reshaping data.
The primary utility of PROC TRANSPOSE lies in its flexibility. It allows users to take variables currently represented as rows and pivot them into columns, or vice-versa, depending on the analytical needs. For instance, if you have multiple columns representing repeated measures (wide format), you can condense these into two columns—one identifying the measure type and one holding the measure value (long format). Conversely, a long format dataset where all measurements are stacked vertically can be spread horizontally into a wide format, often necessary for certain regression models or visual reporting layouts.
Furthermore, while its main function is structural reshaping, this procedure can sometimes implicitly aid in converting variable types, though this is secondary to its pivoting role. Mastering PROC TRANSPOSE is fundamental for any SAS programmer who handles complex data structures requiring normalization or denaturation before final statistical processing.
The Importance of Data Format: Wide vs. Long
Before diving into the mechanics of the procedure, it is essential to understand the difference between the two primary data formats used in statistical software. The long format, also known as the narrow or stacked format, is typically preferred for most modern statistical modeling techniques, especially those involving repeated measures or panel data. In a long format dataset, each observation (measurement) gets its own row. If a subject has three measurements, that subject appears in three separate rows, with an identifier variable specifying which measurement the row represents.
In contrast, the wide format utilizes a single row for each subject or entity. All measurements pertaining to that entity are spread across multiple columns. For example, if we measure “Height” on three different dates, the wide format would have columns labeled “Height_Date1,” “Height_Date2,” and “Height_Date3,” all alongside the subject’s identifier in a single row. While intuitive for manual viewing, this format is often inefficient for iterative analysis or visualization tools that expect a single column for the measurement type.
The ability of PROC TRANSPOSE to switch seamlessly between these formats ensures data compatibility with various analytical tools and reporting requirements, providing the necessary flexibility to prepare data for its intended use, whether that is inputting into a specific machine learning model or generating a customized summary report.
Understanding the Basic Syntax of PROC TRANSPOSE
The syntax for PROC TRANSPOSE is remarkably clean and relies on just a few key statements to define the pivoting logic. These statements tell SAS which variables should remain as identifiers, which should become the new column headings, and which contain the actual data values to be pivoted.
The basic structure follows the standard SAS procedure convention, requiring the declaration of input (`DATA=`) and output (`OUT=`) datasets, followed by the essential commands (`BY`, `ID`, and `VAR`) that dictate the transformation logic. While the `PROC TRANSPOSE` statement itself is simple, understanding the function of the accessory statements is crucial for successful data reshaping.
This function uses the following basic syntax structure:
proc transpose data=long_data out=wide_data;
by var1;
id var2;
var var3;
run;
Let’s break down the role of each crucial statement within this syntax:
- BY statement: This statement specifies the variable(s) that define the groups for transposition. These variables retain their vertical structure and typically become the key identifier columns in the transposed output dataset. When converting from long to wide, the BY variable remains along the rows.
- ID statement: This variable contains the labels that will form the new column headings in the transposed output. When converting from long to wide, the values within the ID variable are spread across the columns.
- VAR statement: This statement identifies the variable(s) whose values will populate the cells of the new, transposed data structure. These are the values associated with the new column headings created by the ID variable.
Detailed Roles of the BY, ID, and VAR Statements
Understanding the interplay between the BY statement and the ID statement is the key to successfully executing PROC TRANSPOSE. The BY variables establish the unit of observation that will define the rows in the output. SAS processes the input data sequentially, grouping observations based on the BY variables, and then applying the transposition logic within each group.
The ID statement, conversely, dictates the horizontal transformation. The unique values found in the ID variable are extracted and used as the new column names. If the ID variable is not specified, SAS automatically generates default column names (e.g., COL1, COL2, etc.), which is generally less informative than using descriptive identifiers.
Finally, the VAR statement tells the procedure where to pull the actual numerical or character data that fills the intersection of the new rows (BY variables) and the new columns (ID variables). If multiple variables are specified in the VAR statement, SAS generates multiple sets of columns in the output, usually prefixed with the original variable name and suffixed by the ID variable value. If the VAR statement is omitted entirely, SAS attempts to transpose all numeric variables in the input data, excluding those defined in the BY statement, which can lead to unexpected output if the input dataset is complex.
Practical Example: Transforming Data from Long to Wide Format
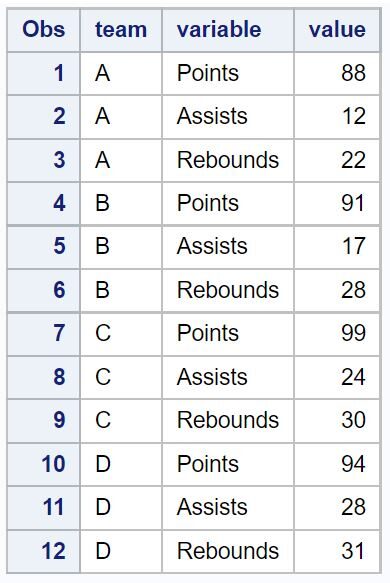
To demonstrate the practical application of PROC TRANSPOSE, we will work with a typical scenario where team statistics are organized in a long format. In this initial structure, each statistical measure (Points, Assists, Rebounds) for a team occupies a distinct row, which results in repetition of the team identifier.
Our objective is to convert this data into a wide format where each team occupies only one row, and the statistics are spread across separate, labeled columns. This format is often easier for quick comparisons across teams or for input into certain legacy SAS procedures.
Suppose we begin with the following input dataset named long_data:
/*create dataset in long format*/
data long_data;
input team $ variable $ value;
datalines;
A Points 88
A Assists 12
A Rebounds 22
B Points 91
B Assists 17
B Rebounds 28
C Points 99
C Assists 24
C Rebounds 30
D Points 94
D Assists 28
D Rebounds 31
;
run;
/*view dataset*/
proc print data=long_data;
The output of the initial long-format data clearly shows multiple rows per team, characterized by the variable and value columns stacking the results:
![]()
Executing the Transposition
To achieve the desired wide format, we must carefully map the variables from the long dataset to the corresponding control statements in PROC TRANSPOSE. Since we want one row per team, team must be specified in the BY statement. The labels we wish to see as new columns are Points, Assists, and Rebounds, which are contained in the variable column; thus, variable goes into the ID statement. Finally, the actual numerical measurements are in the value column, making it the target for the VAR statement.
We use the following code to implement the transformation, saving the result to a new dataset called wide_data:
/*create new dataset in wide format*/
proc transpose data=long_data out=wide_data;
by team;
id variable;
var value;
run;
/*view wide data*/
proc print data=wide_data;Executing this code yields the restructured data where the statistical measures are now presented as individual columns, aligning perfectly with the team identifiers defined in the BY statement. This result confirms that the core transformation from the long format to the wide format has been completed successfully.
![]()
Managing Default Variables: The _NAME_ Column
When PROC TRANSPOSE generates an output dataset, it introduces a default variable named _NAME_. This variable is automatically created to track which original VAR variable was used to supply the values for the new columns. Since we used only a single variable (`value`) in our VAR statement, this _NAME_ variable contains that original variable name, serving as metadata documenting the source of the pivoted values.
While informative, the _NAME_ variable is often redundant, especially when transposing only a single VAR variable, as is the case in our example. Including unnecessary variables increases dataset size and may complicate subsequent analysis or reporting steps. Fortunately, SAS provides straightforward methods to exclude this default column from the final output.
To produce a cleaner output dataset that contains only the essential transposed data, it is best practice to drop the _NAME_ variable directly within the `OUT=` option using the standard **DROP statement**. This keeps the output streamlined and focused solely on the transformed team statistics.
Refining the Output with the DROP Statement
To eliminate the automatically generated _NAME_ variable, the `DROP` option is appended directly to the output dataset specification within the `PROC TRANSPOSE` statement, enclosed in parentheses. This powerful syntax allows for variable manipulation at the point of creation, streamlining the data flow.
The refined syntax using the DROP option looks like this:
/*create new dataset in wide format, dropping _NAME_*/
proc transpose data=long_data out=wide_data(drop=_name_);
by team;
id variable;
var value;
run;
/*view wide data*/
proc print data=wide_data;
Upon executing this modified procedure, the resulting dataset is identical to the previous wide format transformation but critically lacks the extraneous _NAME_ column, resulting in a cleaner and more production-ready table.
![]()
Notice that the final output now contains only the identifying variable (team) and the new columns derived from the ID values (Points, Assists, Rebounds), validating the effective use of the `DROP` statement in the output options.
Conclusion and Further Considerations
PROC TRANSPOSE is an indispensable tool in the SAS programming environment, offering a robust and concise mechanism for pivoting data between long and wide formats. Its power lies in its simplicity, requiring only three key statements—BY, ID, and VAR—to manage complex data reshaping tasks.
While this tutorial focused on the common long-to-wide transformation, the procedure is equally capable of converting wide data back into the long format. When performing wide-to-long transposition, the variables specified in the VAR statement become the new rows, and the ID statement is often omitted or used differently to generate an identifier for the measurement types being stacked.
For users needing more advanced data manipulation, particularly when dealing with summary statistics during transposition, SAS offers other powerful procedures like PROC MEANS or PROC TABULATE, which can be combined with transposition techniques. However, for sheer structural pivoting, PROC TRANSPOSE remains the most direct and efficient choice, ensuring data is formatted correctly for subsequent analysis, modeling, and reporting steps in any comprehensive statistical workflow.
Cite this article
stats writer (2025). How to Easily Transpose Data with PROC TRANSPOSE in SAS. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-to-use-proc-transpose-in-sas-with-examples/
stats writer. "How to Easily Transpose Data with PROC TRANSPOSE in SAS." PSYCHOLOGICAL SCALES, 1 Dec. 2025, https://scales.arabpsychology.com/stats/how-to-use-proc-transpose-in-sas-with-examples/.
stats writer. "How to Easily Transpose Data with PROC TRANSPOSE in SAS." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/how-to-use-proc-transpose-in-sas-with-examples/.
stats writer (2025) 'How to Easily Transpose Data with PROC TRANSPOSE in SAS', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-to-use-proc-transpose-in-sas-with-examples/.
[1] stats writer, "How to Easily Transpose Data with PROC TRANSPOSE in SAS," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, December, 2025.
stats writer. How to Easily Transpose Data with PROC TRANSPOSE in SAS. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.