Table of Contents
The Pandas get_dummies function is a fundamental tool used in data preprocessing, designed specifically to handle categorical variables. Its primary purpose is to convert nominal categorical data into a numerical format suitable for statistical modeling and machine learning algorithms. This process, often referred to as one-hot encoding, transforms text labels or categories into dummy variables, represented by binary indicator values (0 or 1).
When implementing models that rely on mathematical calculations, such as linear regression or neural networks, categorical data must be numerically encoded. The pd.get_dummies function streamlines this essential transformation. By accepting a Pandas DataFrame and specified columns, it efficiently generates new columns—one for each unique category found in the input—populating these new fields with 1s (indicating presence) or 0s (indicating absence).
Understanding and correctly applying this function is crucial for any data scientist working with real-world datasets, as it prevents the misinterpretation of categorical labels as ordinal numerical values, thereby ensuring the integrity and performance of predictive models. This detailed guide will walk through the mechanism, syntax, and practical applications of pd.get_dummies.
Understanding the Challenge of Categorical Variables
In the realm of statistics and data science, the datasets we encounter frequently contain variables that are non-numeric. These are known as categorical variables, and they represent qualities, groups, or classifications rather than measurable quantities. These variables inherently pose a challenge because most mathematical models, particularly those used in advanced prediction and inference, require numerical inputs.
Categorical variables typically take on names or distinct labels that have no intrinsic numerical ordering or scale. For instance, assigning ‘Red’ a value of 1 and ‘Blue’ a value of 2 incorrectly implies that ‘Blue’ is somehow twice or higher than ‘Red’—a nonsensical relationship in this context. Examples of such variables often found in data analysis include:
- Marital Status: (“Married”, “Single”, “Divorced”)
- Smoking Status: (“Smoker”, “Non-smoker”)
- Eye Color: (“Blue”, “Green”, “Hazel”)
- Level of Education: (e.g., “High School”, “Bachelor’s Degree”, “Master’s Degree”)
To successfully fit machine learning algorithms (such as Linear Regression Models, Support Vector Machines, or Decision Trees) and statistical models, we must accurately translate these qualitative labels into a quantitative format. The preferred method for nominal (non-ordered) categorical data is to convert them into dummy variables. These are binary numerical variables (0 or 1) designed solely to represent the presence or absence of a specific category level.
The Necessity of One-Hot Encoding
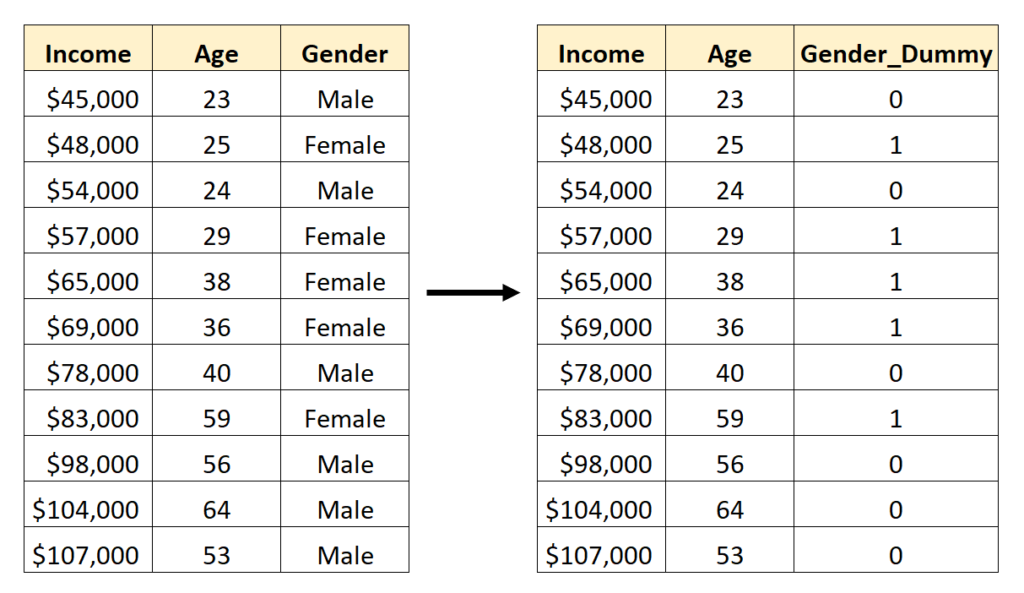
Consider a simple illustration involving the categorical variable Gender, which contains two possible levels: “Male” and “Female”. If we intend to incorporate this variable as a predictor in a regression model, assigning arbitrary numeric codes (like 1 for Male, 2 for Female) would mislead the model into assuming an ordinal relationship exists between the categories. For binary variables like Gender, the solution is straightforward: conversion to a single dummy variable.
In this encoding scheme, we designate one level as the baseline (represented by 0) and the other as the indicator (represented by 1). This is often achieved by dropping one of the categories to avoid multicollinearity, a phenomenon known as the Dummy Variable Trap. For instance, we might choose “Male” to represent 0 and “Female” to represent 1 in a newly created column, or vice versa. This binary transformation ensures that the model correctly interprets the variable as a discrete group identifier.
The visual representation below demonstrates this simple binary transformation for the Gender variable, effectively preparing the qualitative data for quantitative analysis:

When dealing with variables having multiple categories (e.g., ‘Color’ with ‘Red’, ‘Green’, ‘Blue’), the pd.get_dummies function generates three separate binary columns (Color_Red, Color_Green, Color_Blue). A row where the original color was ‘Red’ would have a 1 in Color_Red and 0s in the others. However, to maintain statistical independence and avoid perfect correlation among predictors, one of these generated columns is often dropped. Pandas handles this critical step efficiently using the drop_first parameter.
Official Syntax and Core Parameters of pandas.get_dummies
The process of creating dummy variables for one or more columns within a Pandas DataFrame is centralized within the pandas.get_dummies function. This function is robust and highly optimized for large-scale data manipulation. It abstracts away the complex manual creation of binary columns, requiring only a few key arguments to achieve the desired transformation.
The basic signature of the function, outlining the most commonly used parameters, is as follows:
pandas.get_dummies(data, prefix=None, columns=None, drop_first=False)
A thorough understanding of these arguments is essential for effective data preparation:
- data: This required argument specifies the input. It is typically the entire name of the DataFrame containing the categorical variables you wish to encode.
- prefix: An optional string or list of strings used to append to the front of the newly created dummy variable columns. This enhances readability and clarity, helping analysts distinguish the encoded variables from original features (e.g., using ‘Gen’ as a prefix results in columns like ‘Gen_M’, ‘Gen_F’).
- columns: An optional list specifying the names of the column(s) within the input data that should be converted into dummy variables. If this parameter is omitted,
pd.get_dummieswill automatically attempt to convert all object or categorical dtype columns. - drop_first: A boolean (True/False) that dictates whether to drop the first category generated for each encoded variable. Setting this to
Trueis highly recommended in modeling scenarios to avoid the issue of perfect multicollinearity, where one category’s presence can be perfectly predicted by the absence of all others.
The subsequent examples illustrate the practical application of the pd.get_dummies function, first for a single column and then for multiple features simultaneously.
Example 1: Encoding a Single Categorical Feature
To demonstrate the simplest use case, let’s consider a small Pandas DataFrame containing basic demographic data: income, age, and gender. The ‘gender’ column is a text-based categorical variable that needs numerical transformation before being used in predictive modeling.
First, we create and inspect the sample data structure:
import pandas as pd #create DataFrame df = pd.DataFrame({'income': [45, 48, 54, 57, 65, 69, 78], 'age': [23, 25, 24, 29, 38, 36, 40], 'gender': ['M', 'F', 'M', 'F', 'F', 'F', 'M']}) #view DataFrame df income age gender 0 45 23 M 1 48 25 F 2 54 24 M 3 57 29 F 4 65 38 F 5 69 36 F 6 78 40 M
We apply the pd.get_dummies() function, specifically targeting the ‘gender’ column using the columns parameter. Crucially, we set drop_first=True. This action performs the required one-hot encoding while eliminating the column corresponding to the first category encountered (‘F’ in this case, as determined alphabetically or by order of appearance, resulting in the dropped column ‘gender_F’).
#convert gender to dummy variable, dropping the first category to avoid multicollinearity pd.get_dummies(df, columns=['gender'], drop_first=True) income age gender_M 0 45 23 1 1 48 25 0 2 54 24 1 3 57 29 0 4 65 38 0 5 69 36 0 6 78 40 1
The resultant DataFrame successfully replaces the original ‘gender’ column with the new dummy variable, ‘gender_M’. Due to setting drop_first=True, the ‘gender_F’ column was omitted. We can interpret the resulting binary values as follows:
- A value of 0 in the ‘gender_M’ column represents the baseline category, which corresponds to “Female”.
- A value of 1 in the ‘gender_M’ column indicates the presence of the encoded category, which corresponds to “Male”.
Example 2: Encoding Multiple Features Simultaneously
The true efficiency of the pd.get_dummies function is realized when encoding multiple categorical variables at once. In this scenario, we introduce a second categorical feature, ‘college’, which indicates whether an individual has a college degree (‘Y’ for Yes, ‘N’ for No).
We begin by generating the extended DataFrame that includes both ‘gender’ and ‘college’ columns:
import pandas as pd #create DataFrame df = pd.DataFrame({'income': [45, 48, 54, 57, 65, 69, 78], 'age': [23, 25, 24, 29, 38, 36, 40], 'gender': ['M', 'F', 'M', 'F', 'F', 'F', 'M'], 'college': ['Y', 'N', 'N', 'N', 'Y', 'Y', 'Y']}) #view DataFrame df income age gender college 0 45 23 M Y 1 48 25 F N 2 54 24 M N 3 57 29 F N 4 65 38 F Y 5 69 36 F Y 6 78 40 M Y
To encode both columns, we pass a list containing both column names to the columns parameter. We retain drop_first=True to ensure that one category from each new set of dummy variables is dropped, maintaining a statistically sound feature set for any downstream machine learning algorithms.
#convert gender and college to dummy variables pd.get_dummies(df, columns=['gender', 'college'], drop_first=True) income age gender_M college_Y 0 45 23 1 1 1 48 25 0 0 2 54 24 1 0 3 57 29 0 0 4 65 38 0 1 5 69 36 0 1 6 78 40 1 1
The output demonstrates the successful parallel transformation. We now have ‘gender_M’ and ‘college_Y’ as numerical predictors. We interpret these new columns based on the dropped baseline categories:
For the ‘gender’ encoding:
- A value of 0 in ‘gender_M’ represents the baseline “Female” category.
- A value of 1 in ‘gender_M’ represents the indicator “Male” category.
For the ‘college’ encoding:
- A value of 0 in ‘college_Y’ represents the baseline “No” college category.
- A value of 1 in ‘college_Y’ represents the indicator “Yes” college category.
Understanding and Avoiding Multicollinearity
The decision to set drop_first=True is not merely a convenience; it addresses a crucial statistical problem known as the Dummy Variable Trap, which leads to perfect multicollinearity. Multicollinearity occurs when one predictor variable in a regression model can be perfectly predicted by a linear combination of other predictors. When dealing with categorical variables encoded using the one-hot method, retaining all generated binary columns inevitably creates perfect multicollinearity.
For example, if we have categories A, B, and C, and we create three dummy variables (A_dummy, B_dummy, C_dummy), the value of C_dummy is perfectly determined if A_dummy and B_dummy are both 0. If A_dummy=0 and B_dummy=0, then C_dummy must equal 1. This linear dependency violates the fundamental assumptions of many linear models, such as ordinary least squares (OLS) regression, resulting in unstable coefficient estimates and inflated standard errors.
By setting drop_first=True, we ensure that for a variable with K categories, only K-1 dummy variables are generated. The category that is dropped effectively serves as the baseline, and its coefficient in the resulting model is implicitly captured by the intercept term. All other categories’ coefficients are then interpreted relative to this baseline category, solving the issue of the Dummy Variable Trap without losing any information about the original categorical structure.
While this is the standard practice for nominal variables in statistical modeling, note that some specific machine learning algorithms, particularly tree-based models, are less sensitive to multicollinearity. However, when working with linear models or interpreting coefficients, the use of drop_first=True with pd.get_dummies remains the canonical approach for generating clean and interpretable features.
Cite this article
stats writer (2025). How to Easily Convert Categorical Data to Dummy Variables with Pandas get_dummies. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-to-use-pandas-get-dummies-pd-get_dummies/
stats writer. "How to Easily Convert Categorical Data to Dummy Variables with Pandas get_dummies." PSYCHOLOGICAL SCALES, 5 Dec. 2025, https://scales.arabpsychology.com/stats/how-to-use-pandas-get-dummies-pd-get_dummies/.
stats writer. "How to Easily Convert Categorical Data to Dummy Variables with Pandas get_dummies." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/how-to-use-pandas-get-dummies-pd-get_dummies/.
stats writer (2025) 'How to Easily Convert Categorical Data to Dummy Variables with Pandas get_dummies', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-to-use-pandas-get-dummies-pd-get_dummies/.
[1] stats writer, "How to Easily Convert Categorical Data to Dummy Variables with Pandas get_dummies," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, December, 2025.
stats writer. How to Easily Convert Categorical Data to Dummy Variables with Pandas get_dummies. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.