Table of Contents
Data preprocessing is a crucial stage in any Machine Learning workflow. A common challenge encountered during this phase is handling variables that represent qualitative attributes rather than numerical measurements. These variables are known as Categorical Data, and they often describe categories, groups, or types (e.g., color, gender, or team name). Standard statistical models and algorithms typically require numerical input, making direct utilization of these categorical factors impossible without transformation.
This necessity leads us to the technique of One-Hot Encoding, a fundamental process used specifically to bridge the gap between categorical and numerical data formats. In essence, one-hot encoding converts complex nominal variables into a series of binary (0 or 1) features, ensuring that the relationships between categories are not misinterpreted by algorithms that rely on quantitative magnitude or scale. This transformation is pivotal for algorithms that calculate distance measures, such as K-Nearest Neighbors or Support Vector Machines.
When working within the R programming environment, performing this encoding requires specialized functions designed for efficient data manipulation. While base R offers methods like model.matrix(), professional data science workflows often rely on powerful packages like caret to streamline the preprocessing tasks. We will demonstrate a robust, step-by-step approach using the caret package, ensuring that your categorical variables are cleanly and correctly prepared for subsequent numerical analysis.
The core concept behind one-hot encoding involves generating a new binary column for every unique value present in the original categorical feature. For any given observation, only one of these new columns will hold the value 1 (indicating the presence of that specific category), while all other columns derived from that feature will hold 0. This binary representation ensures that each category is treated as an independent dimension, avoiding misleading ordinal relationships that might occur if categories were simply mapped to arbitrary integer values (e.g., assigning 1 to ‘Team A’ and 2 to ‘Team B’).
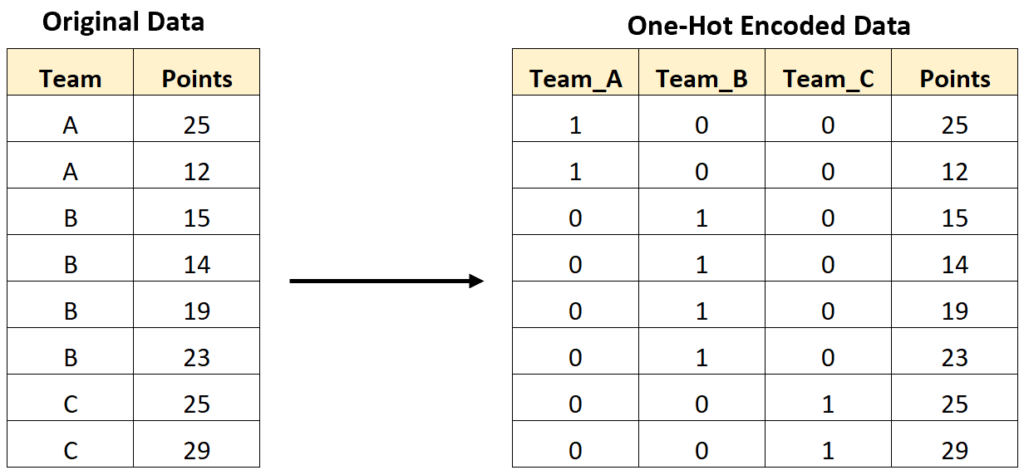
To illustrate this process, consider a scenario where we have a column listing team names: ‘A’, ‘B’, and ‘C’. After applying One-Hot Encoding, this single column transforms into three distinct binary columns: teamA, teamB, and teamC. If an original observation belonged to ‘Team B’, the output row would show teamA=0, teamB=1, and teamC=0. This structure maintains the integrity of the nominal data while providing the numerical input required by analytical models.
The following visualization clearly depicts how a categorical variable containing different team names is systematically converted into a numerical matrix consisting exclusively of 0s and 1s:

Understanding this visual representation is essential before diving into the implementation details. The subsequent steps will guide you through executing this exact transformation using real code within the R environment, leveraging tools specialized for data preprocessing.
Prerequisites and Setting Up the R Environment
Before initiating the encoding process, ensure that you have the necessary environment configured. Although One-Hot Encoding can be handled using base R functions, the caret package (Classification and Regression Training) provides powerful and integrated tools for data preprocessing, including the specific function we will use, dummyVars(). If you do not already have it installed, you must first execute the installation command in your R console.
The caret package is a meta-package that unifies many preprocessing and modeling techniques, making it an indispensable tool for R users involved in predictive analytics. By utilizing its dedicated functions, we can handle complex transformations like encoding, scaling, and imputation in a clean and efficient manner, ensuring reproducibility across different projects.
Once installed, the package must be loaded into the current R session using the library() function. This step is mandatory before attempting to call any functions provided by the package, such as dummyVars(). Failure to load the library will result in an error indicating that the function cannot be found.
Step 1: Preparing the Sample Dataset in R
Our first concrete step is to define and create the raw dataset that contains the categorical variable requiring transformation. For this demonstration, we will create a data frame named df, which consists of two columns: team (the categorical variable) and points (a numerical variable). This setup simulates typical mixed-type datasets encountered in real-world scenarios.
The team column contains three unique factor levels: ‘A’, ‘B’, and ‘C’. It is crucial that the structure of the data frame is correctly defined using the data.frame() function, ensuring that R recognizes the variable types appropriately. While R often defaults to treating character vectors as factors, explicitly reviewing the structure (using functions like str() or summary()) is always recommended to avoid unexpected behavior during encoding.
Execute the following commands in R to create the dataset and inspect its initial structure. Note how the Categorical Data in the team column is organized before any transformation takes place:
#create data frame df <- data.frame(team=c('A', 'A', 'B', 'B', 'B', 'B', 'C', 'C'), points=c(25, 12, 15, 14, 19, 23, 25, 29)) #view data frame df team points 1 A 25 2 A 12 3 B 15 4 B 14 5 B 19 6 B 23 7 C 25 8 C 29
Step 2: Implementing One-Hot Encoding with the caret Package
With the dataset prepared, we now move to the primary encoding phase utilizing the specialized functions provided by the caret package. The function central to this operation is dummyVars(). This function is designed to create a “dummy variable generator” object, which holds the blueprint for how the encoding transformation should occur based on the input data frame. It does not perform the transformation immediately but prepares the framework for it.
The formula passed to dummyVars() is critical. We use the formula "~ .", which instructs R to include all variables in the data frame in the dummy variable creation process. By default, dummyVars() will intelligently identify which variables are factors or character types and apply the binary encoding transformation only to those columns, while leaving numerical columns (like points) untouched, but still included in the final output structure.
After defining the blueprint object (dummy), the actual transformation is executed using the standard R prediction function, predict(), applied to the dummy object and the original data frame (df). The result is converted back into a standard R data frame, final_df, which contains our newly encoded variables alongside the original numerical data.
library(caret) #define one-hot encoding function (creating the blueprint) dummy <- dummyVars(" ~ .", data=df) #perform one-hot encoding on data frame using the blueprint final_df <- data.frame(predict(dummy, newdata=df)) #view final data frame final_df teamA teamB teamC points 1 1 0 0 25 2 1 0 0 12 3 0 1 0 15 4 0 1 0 14 5 0 1 0 19 6 0 1 0 23 7 0 0 1 25 8 0 0 1 29
Analyzing the Results and Understanding the Output Matrix
Upon reviewing the final_df output, several key observations confirm the successful application of the One-Hot Encoding process. Most notably, the original single categorical column, team, has been replaced by three distinct binary columns: teamA, teamB, and teamC. This count directly correlates with the number of unique categories present in the initial variable (A, B, and C).
Crucially, the transformation ensures that for every observation (row), only one of the newly created team columns holds the value 1. For instance, the first two rows, which originally belonged to ‘Team A’, now have a 1 in the teamA column and 0s in teamB and teamC. This binary matrix, known as the design matrix, is the numerical representation required by most quantitative algorithms.
It is also important to note that the original team column itself was implicitly dropped from the data frame during the encoding process, as its information content is now fully encapsulated within the new binary columns. Furthermore, the numerical variable, points, remains intact and preserved in the final data frame, demonstrating how dummyVars() effectively handles mixed data types by applying transformation only where needed.
Advanced Considerations and Further Resources
While the method demonstrated using the caret package is highly effective and simple, practitioners should be aware of a theoretical concept often associated with one-hot encoding: the Dummy Variable Trap. In statistical modeling (especially linear regression), including all $K$ derived binary columns from a $K$-level categorical variable can lead to perfect collinearity, known as multicollinearity, because the $K$th column is perfectly predictable from the $K-1$ columns. This is because $Team C = 1 – (Team A + Team B)$.
Many machine learning algorithms (like decision trees or regularization methods) are robust to or handle this multicollinearity internally, but classical regression models often require dropping one of the $K$ columns (usually the first one, ‘Team A’, which becomes the reference category). The dummyVars() function in caret, by default, creates all $K$ dummy variables. If you intend to use this output directly in a linear regression model, you might need to manually drop one column or use specialized functions that automatically apply the ‘drop first’ rule.
The resulting dataset, final_df, is now fully prepared—containing only numerical data—and can be seamlessly fed into any required machine learning algorithm for training or prediction. For those interested in exploring the full capabilities and optional arguments, such as handling missing values or enforcing the ‘drop first’ rule, we recommend consulting the official documentation.
Note: You can find the complete online documentation for the dummyVars() function at its dedicated CRAN repository page.
The following tutorials offer additional information about working effectively with categorical variables and other preprocessing techniques crucial for robust data analysis in R:
Tutorial on Label Encoding vs. One-Hot Encoding for Predictive Models.
Guide to Handling High Cardinality Categorical Variables in R.
Using the
model.matrix()function for simpler design matrix creation in base R.
Cite this article
stats writer (2025). How to Easily Perform One-Hot Encoding in R. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-to-perform-one-hot-encoding-in-r/
stats writer. "How to Easily Perform One-Hot Encoding in R." PSYCHOLOGICAL SCALES, 3 Dec. 2025, https://scales.arabpsychology.com/stats/how-to-perform-one-hot-encoding-in-r/.
stats writer. "How to Easily Perform One-Hot Encoding in R." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/how-to-perform-one-hot-encoding-in-r/.
stats writer (2025) 'How to Easily Perform One-Hot Encoding in R', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-to-perform-one-hot-encoding-in-r/.
[1] stats writer, "How to Easily Perform One-Hot Encoding in R," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, December, 2025.
stats writer. How to Easily Perform One-Hot Encoding in R. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.