Table of Contents
Data integrity is paramount in statistical analysis, yet datasets often arrive incomplete, plagued by issues like sensor failure, recording errors, or non-responses. A common challenge encountered by analysts using R is dealing with these missing values (often denoted as NA). While simple deletion or mean imputation are quick fixes, they can skew results or severely reduce statistical power. A more sophisticated and often preferred technique, especially for time-series or sequential data, is interpolation.
Interpolation is a mathematical method used to construct new data points within the range of a discrete set of known data points. Essentially, it estimates the value of a function between two known data points by fitting a curve or line. In the context of data analysis in R, this technique allows us to intelligently fill gaps, maintaining the underlying trend and structure of the data rather than simply using a static replacement value.
While base R provides the approx() function for fundamental interpolation between x and y vectors, modern data science workflows often leverage powerful packages like dplyr for data manipulation and zoo for handling regular and irregular time-series data. The combination of these tools provides a robust and efficient way to handle imputation tasks, particularly using the specialized na.approx() function, which defaults to linear interpolation.
The Fundamental Approach to Interpolation in R
To successfully interpolate missing records in a column within an R data frame, we typically rely on the na.approx() function provided by the zoo package. This function identifies NA entries and replaces them by performing linear interpolation based on the values immediately surrounding the gap. For streamlined data manipulation, this function is usually integrated into a pipeline using the dplyr package, specifically employing the mutate() verb to update the target column in place.
The core syntax for executing this operation is straightforward and leverages the pipe operator (%>%) for clear, sequential steps. This approach ensures that the interpolation is applied consistently across the entire vector within the specified column, generating new estimates only where data is absent. This method preserves the structure and integrity of the overall data frame while efficiently resolving the issue of missing values.
You can use the following basic syntax to interpolate missing values in a data frame column in R, assuming both packages are installed and loaded:
library(dplyr) library(zoo) df <- df %>% mutate(column_name = na.approx(column_name))
This code snippet is highly efficient. First, it loads the required libraries. Second, it chains the operation using the pipe (%>%), feeding the data frame df into the mutate() function. Within mutate(), the specified column_name is overwritten (or mutated) with the results of applying the na.approx() function to that same column. The following detailed example illustrates how to use this syntax effectively in a practical scenario.
Example: Setting up the Data Frame with Missing Sales Records
To demonstrate the utility of interpolation, let us consider a typical scenario involving time-series data. Suppose we have a small data frame in R that tracks the total sales recorded by a retail store over 15 consecutive days. Due to a system error or manual oversight, sales figures are unavailable (represented by NA) for four consecutive days in the middle of the period. This gap needs to be filled responsibly to allow for accurate trend analysis or forecasting.
We begin by constructing this sample dataset. We define a vector for day (1 through 15) and a corresponding vector for sales, which includes the known figures and the missing indicators (NAs). It is crucial to examine the structure of the data before proceeding with any imputation method, ensuring the location and extent of the missingness are understood.
The data clearly shows a generally increasing trend, making linear interpolation an appropriate method for estimation, as it will assume the underlying growth rate remained constant during the period of missing observations. The code below creates and displays this initial data frame:
#create data frame df <- data.frame(day=1:15, sales=c(3, 6, 8, 10, 14, 17, 20, NA, NA, NA, NA, 35, 39, 44, 49)) #view data frame df day sales 1 1 3 2 2 6 3 3 8 4 4 10 5 5 14 6 6 17 7 7 20 8 8 NA 9 9 NA 10 10 NA 11 11 NA 12 12 35 13 13 39 14 14 44 15 15 49
The output clearly illustrates the four consecutive days—Day 8 through Day 11—where the sales numbers are marked as NA. These represent the gaps that our interpolation technique must bridge using the known values of 20 (Day 7) and 35 (Day 12).
Visualizing the Initial Missing Data Pattern
Before applying any imputation technique, visualizing the data is essential. A visual representation helps confirm the nature of the data (e.g., linear, seasonal, cyclical) and provides a baseline for evaluating the success of the interpolation later on. For this time-series sales data, a simple line chart effectively highlights where the data sequence is broken by the missing values.
By plotting the existing sales figures against the day number, we expect to see a gap in the line corresponding to the four NA entries. This gap visually confirms the necessity for interpolation to maintain the smooth progression of the sales trend across the 15-day period.
#create line chart to visualize sales plot(df$sales, type='o', pch=16, col='steelblue', xlab='Day', ylab='Sales')
The resulting plot clearly shows the trajectory of sales leading up to Day 7 and resuming at Day 12, leaving a pronounced break in the middle. The plot confirms the visual discontinuity caused by the absence of data points, which interpolation aims to smoothly resolve.

Implementing Linear Interpolation using na.approx()
To fill these gaps, we utilize the powerful functionality provided by the zoo package, specifically the na.approx() function. This function performs linear interpolation, which calculates the imputed values by assuming a linear relationship between the known bounding points. In our case, it will calculate a constant increase in sales between the 20 units sold on Day 7 and the 35 units sold on Day 12, distributing this change evenly over the four intervening days.
We combine this with the mutate() function from the dplyr package to execute the operation efficiently within the data pipeline. This approach is highly favored in modern R programming as it maintains code readability and avoids creating unnecessary intermediate variables. The function na.approx() is designed to handle vectors containing NAs, replacing them with interpolated estimates while leaving non-missing values unchanged.
The necessary code involves loading both the dplyr and zoo libraries, piping the data frame into the mutation step, and applying the interpolation specifically to the sales column.
library(dplyr) library(zoo) #interpolate missing values in 'sales' column df <- df %>% mutate(sales = na.approx(sales)) #view updated data frame df day sales 1 1 3 2 2 6 3 3 8 4 4 10 5 5 14 6 6 17 7 7 20 8 8 23 9 9 26 10 10 29 11 11 32 12 12 35 13 13 39 14 14 44 15 15 49
Upon reviewing the updated data frame, observe how the sales figures for Day 8, 9, 10, and 11 have been replaced with 23, 26, 29, and 32, respectively. Since the gap spans 5 days (from Day 7 to Day 12) with a total sales increase of 15 (35 – 20), na.approx() calculated an estimated increase of 3 units per day (15 / 5 intervals), creating a smooth, linear transition across the missing period.
Evaluating the Interpolated Data
With the missing values successfully imputed, the next step is to visualize the updated data set. This final visualization is crucial for confirming that the interpolation has produced sensible estimates that align well with the overall trend of the known data points. If the chosen method was appropriate, the line chart should now display a seamless, continuous line, eliminating the gap seen previously.
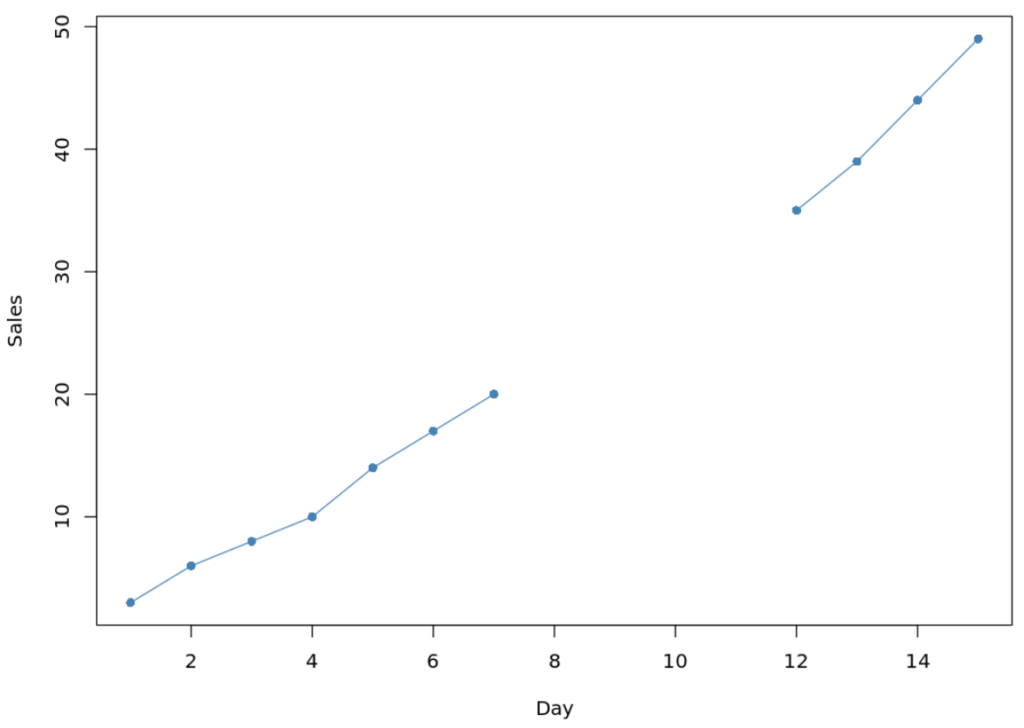
We use the exact same plotting code as before, but applied to the new data frame df, which now contains the interpolated sales figures.
#create line chart to visualize sales plot(df$sales, type='o', pch=16, col='steelblue', xlab='Day', ylab='Sales')
The updated graph confirms that the na.approx() function effectively bridged the gap. The interpolated values form a straight line segment connecting the previous known point (Day 7) and the subsequent known point (Day 12), perfectly fitting the overall linear interpolation assumption.

The visual continuity provided by the interpolated data ensures that subsequent time-series analysis, forecasting models, or descriptive statistics are based on a complete and logically sound dataset. The values chosen by the na.approx() function demonstrably fit the trend in the data quite well, providing high confidence in the imputation results for this particular context.
Advanced Considerations: Beyond Linear Interpolation
Linear interpolation, as provided by default via na.approx(), is often sufficient when data exhibits a relatively constant rate of change. However, in more complex datasets, especially those with non-linear or highly fluctuating patterns, alternative interpolation methods might be necessary to capture the true underlying dynamics. The zoo package, and R in general, offers several alternatives.
Spline Interpolation: For smoother results that mimic natural curves, cubic spline interpolation (often available via
splinefun()in base R or related functions in other packages) is useful. Splines fit piecewise polynomials to the data, ensuring continuity not only in the function value but also in its derivatives, resulting in a much smoother transition compared to linear methods.Non-Linear Methods: If the data is known to follow a specific non-linear model (e.g., exponential growth or logarithmic decay), advanced statistical modeling techniques like Kalman filtering or specialized curve fitting may be more appropriate than simple geometric interpolation.
Nearest Neighbor Imputation: While not strictly interpolation, the
na.locf()function (Last Observation Carried Forward) is useful when the data tends to remain constant for periods, or when the assumption of constant change (as in linear interpolation) is inappropriate.
The choice of method should always be guided by the subject matter knowledge and the characteristics of the data being analyzed. For the illustrative sales data, where a steady growth rate was evident, linear interpolation proved to be the most efficient and accurate solution for handling the missing values.
Summary and Further Learning
Interpolating missing values is a fundamental skill for any data analyst working in R. By leveraging the combined strengths of the dplyr package for efficient data manipulation and the specialized functions of the zoo package, specifically na.approx(), we can ensure our datasets are complete and suitable for robust analysis. This technique minimizes bias compared to simpler imputation methods, particularly when dealing with sequential or time-dependent data.
Remember that interpolation is an estimation, not a recovery of the true underlying data. Therefore, while it provides a superior way to handle data gaps compared to deletion or mean imputation, analysts must always document the imputation methods used and assess their impact on final results.
The following tutorials provide additional information on how to handle missing values in R, covering a broader spectrum of techniques, including advanced methods for complex data structures:
Cite this article
stats writer (2025). How to Easily Interpolate Missing Data in R. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-to-interpolate-missing-values-in-r/
stats writer. "How to Easily Interpolate Missing Data in R." PSYCHOLOGICAL SCALES, 2 Dec. 2025, https://scales.arabpsychology.com/stats/how-to-interpolate-missing-values-in-r/.
stats writer. "How to Easily Interpolate Missing Data in R." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/how-to-interpolate-missing-values-in-r/.
stats writer (2025) 'How to Easily Interpolate Missing Data in R', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-to-interpolate-missing-values-in-r/.
[1] stats writer, "How to Easily Interpolate Missing Data in R," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, December, 2025.
stats writer. How to Easily Interpolate Missing Data in R. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.