Table of Contents
Understanding the Foundation of the One Sample t-test in SPSS
The One Sample t-test is a cornerstone of inferential statistics, primarily utilized to determine whether the mean of a single sample differs significantly from a predetermined or known population mean. In the realm of academic and professional research, this test provides a rigorous framework for validating hypotheses when the population standard deviation is unknown. By utilizing IBM SPSS Statistics, researchers can efficiently process complex datasets to uncover whether observed differences in data are statistically significant or merely the result of random sampling variation.
To execute this analysis effectively, one must first understand that the One Sample t-test compares the sample mean against a “test value,” which represents the population mean under the null hypothesis. This test is particularly valuable in quality control, social sciences, and biological research, where a specific benchmark or historical average serves as the point of comparison. For instance, a researcher might use this test to determine if the average test score of a specific classroom deviates from the national average, or if the chemical composition of a soil sample matches a standard environmental threshold.
The One Sample t-test relies on the t-distribution, which was developed by William Sealy Gosset under the pseudonym “Student.” This distribution is similar to the normal distribution but has “heavier tails,” making it more appropriate for smaller sample sizes where the true variability of the population is estimated from the sample itself. Within IBM SPSS Statistics, the software automates the calculation of the t-statistic and provides the necessary metrics to accept or reject the null hypothesis with a high degree of mathematical precision.
Before diving into the procedural steps, it is essential to ensure that the data meets certain statistical assumptions. These include the independence of observations, the absence of significant outliers within the dataset, and the normality of the distribution of the dependent variable. If these assumptions are violated, the results of the One Sample t-test may become unreliable, potentially leading to Type I or Type II errors. Therefore, a thorough exploratory data analysis is always recommended as a preliminary step in the IBM SPSS Statistics workflow.
Establishing Research Hypotheses and Significance Levels
Every One Sample t-test begins with the formulation of two competing statements: the null hypothesis (H0) and the alternative hypothesis (H1). The null hypothesis typically posits that there is no significant difference between the sample mean and the population mean. In mathematical terms, this is expressed as μ = x, where μ is the population mean and x is the test value. This serves as the default position that the researcher attempts to challenge through empirical evidence and statistical calculation.
Conversely, the alternative hypothesis represents the researcher’s actual claim or the presence of an effect. It can be formulated as a non-directional (two-tailed) test, stating that the sample mean is simply not equal to the population mean (μ ≠ x). Alternatively, it can be a directional (one-tailed) test, suggesting the mean is either greater than or less than the test value. Defining these hypotheses clearly is a critical step before interacting with the IBM SPSS Statistics interface, as it dictates how the resulting p-value will be interpreted.
Parallel to the hypotheses, the researcher must select a significance level, denoted by the Greek letter alpha (α). The most common significance level used in scientific research is 0.05, which implies a 5% risk of concluding that a difference exists when there is actually no true difference. This threshold acts as the “cutoff” point for the p-value; if the p-value generated by the One Sample t-test is less than or equal to α, the null hypothesis is rejected in favor of the alternative hypothesis.
Furthermore, the One Sample t-test provides a confidence interval, which offers a range of values within which the true population mean difference is likely to fall. A 95% confidence interval is standard, providing a measure of the precision of the sample mean estimate. If the confidence interval does not include zero, it reinforces the conclusion that the difference between the sample mean and the test value is statistically significant, providing a more comprehensive view of the data than the p-value alone.
Theoretical Framework: The Botanist’s Case Study
To illustrate the practical application of the One Sample t-test in IBM SPSS Statistics, consider the scenario of a botanist investigating a specific species of plant. The researcher aims to determine if the mean height of this species is exactly 15 inches, based on historical botanical records. This scenario provides a perfect template for the One Sample t-test, as we are comparing a single sample of collected plants against a known population mean of 15 inches.
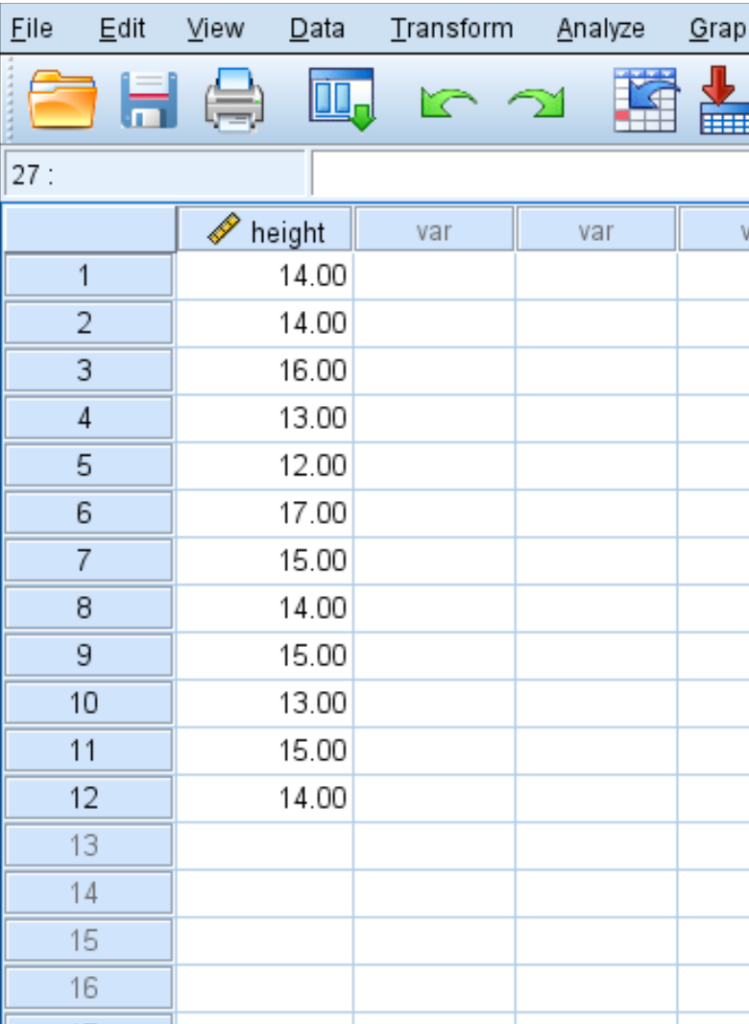
In this example, the botanist selects a random sample of 12 plants. Randomization is a vital component of statistical inference, as it ensures that the sample is representative of the broader population and minimizes selection bias. The heights of these 12 plants are recorded in inches, creating the raw data that will be imported into IBM SPSS Statistics for analysis. This data constitutes the dependent variable for our study, and its mean will be the primary metric under scrutiny.

The specific statistical hypotheses for this case study are defined as follows. The null hypothesis (H0) states that the true population mean (μ) is equal to 15 inches. This suggests that any observed deviation in the 12 sampled plants is merely due to chance. The alternative hypothesis (H1) states that the true population mean (μ) is not equal to 15 inches, indicating a significant biological or environmental deviation from the expected norm. The botanist sets the significance level at α = 0.05 to maintain standard scientific rigor.
By using the One Sample t-test, the botanist can quantify the evidence against the null hypothesis. If the 12 plants collected are significantly shorter or taller than 15 inches on average, the t-statistic will reflect this distance. This empirical approach moves the investigation beyond mere observation into the realm of statistical significance, allowing the botanist to make a confident statement about the entire species based on the sample data.
Step 1: Initiating the Analysis in SPSS
The first practical phase involves navigating the IBM SPSS Statistics user interface to locate the appropriate analytical tool. Once the software is open and the data (the heights of the 12 plants) has been entered into the “Data View” tab, the user should focus on the top navigation bar. The “Analyze” menu is the central hub for all statistical analysis within the software, housing various tests ranging from descriptive statistics to complex regression models.
Within the “Analyze” menu, hover over the “Compare Means” option. This sub-menu is designed for tests that evaluate differences between averages, including the Independent Samples t-test, the Paired Samples t-test, and our target: the One-Sample T Test. Selecting this option will trigger the opening of a dedicated dialogue box where the parameters for the analysis will be defined. It is important to ensure that the correct dataset is active before proceeding to this step.

The transition from data entry to the “Compare Means” menu is a critical juncture in the IBM SPSS Statistics workflow. This reflects the shift from data management to statistical inference. For users unfamiliar with the interface, the “Analyze” menu might seem daunting, but the logical categorization of tests by their mathematical function—such as “Compare Means”—makes it accessible for researchers at all levels of expertise. The consistency of this menu across different versions of the software ensures that skills learned in one version are transferable to others.
Step 2: Configuring Test Variables and the Test Value
After selecting the One-Sample T Test option, a dialogue box appears, requiring the user to specify which variable is being tested and what value it is being compared against. In our botanical example, the variable “height” must be moved from the source list on the left to the “Test Variable(s)” box on the right. This can be accomplished by clicking the arrow button between the two boxes. IBM SPSS Statistics allows for multiple variables to be tested simultaneously, but for this specific One Sample t-test, we focus solely on plant height.

Crucially, the “Test Value” field at the bottom of the dialogue box must be updated. This field represents the population mean defined in your null hypothesis. For the botanist, this value is 15. Entering “15” into this box tells IBM SPSS Statistics to calculate the difference between the sample mean and this specific benchmark. Leaving this value as the default (usually 0) would result in a test determining if the mean height is significantly different from zero, which is not the objective of this study.

Before finalizing the configuration by clicking “OK,” users may also explore the “Options” button within the dialogue box. This allows for the adjustment of the confidence interval percentage (e.g., changing it from 95% to 99%) and the handling of missing values. For most standard research, the default settings are appropriate. Once “OK” is clicked, the software processes the data using the t-test algorithm and generates an output window containing the descriptive statistics and the inferential results.
Step 3: Analyzing Descriptive Statistics and Sample Characteristics
The output of the One Sample t-test in IBM SPSS Statistics is presented in two primary tables. The first table, titled “One-Sample Statistics,” provides essential descriptive statistics for the variable under analysis. This table serves as the foundation for the t-test and allows the researcher to understand the basic properties of the sample before interpreting the significance of the results. It typically includes the sample size (N), the mean, the standard deviation, and the standard error of the mean.

In our example, the “One-Sample Statistics” table reveals the following metrics:
- N: This represents the total number of observations in the sample. For the botanist, N = 12. A larger sample size generally leads to more precise estimates and increased statistical power.
- Mean: This is the arithmetic mean height of the 12 plants in the sample. Based on the data, the sample mean is calculated to be 14.3333 inches.
- Std. Deviation: The standard deviation measures the amount of variation or dispersion in the plant heights. A low standard deviation indicates that the heights are close to the mean, while a high value suggests a wider range of heights.
- Std. Error Mean: The standard error of the mean is an estimate of how much the sample mean is likely to vary from the true population mean. It is calculated by dividing the standard deviation by the square root of the sample size (s/√n).
By reviewing these descriptive statistics, the researcher can immediately see that the sample mean of 14.3333 inches is lower than the hypothesized population mean of 15 inches. However, descriptive statistics alone cannot determine if this difference is statistically significant. To make that determination, one must look at the second table in the IBM SPSS Statistics output, which contains the actual results of the One Sample t-test.
Interpreting Inferential Results and the Test Statistic
The second table in the output, titled “One-Sample Test,” provides the core data needed to evaluate the hypotheses. The most critical value in this table is the t-statistic (t), which represents the ratio of the observed difference between the sample mean and the test value to the standard error of the mean. In the botanist’s case, the t-value is -1.685. The negative sign simply indicates that the sample mean was lower than the hypothesized test value.
Alongside the t-statistic, the table displays the degrees of freedom (df). For a One Sample t-test, the degrees of freedom are calculated as the sample size minus one (n – 1). With 12 plants in the sample, the df is 11. This value is used by IBM SPSS Statistics to determine the shape of the t-distribution and, subsequently, the p-value. The degrees of freedom are a fundamental concept in statistical inference, reflecting the number of independent pieces of information available to estimate the population parameters.
The “Sig. (2-tailed)” column provides the p-value, which is the most widely used metric for determining statistical significance. In this analysis, the p-value is 0.120. This value represents the probability of obtaining a t-statistic as extreme as -1.685, assuming that the null hypothesis is true. Because 0.120 is greater than the significance level (α = 0.05), we conclude that the observed difference is not statistically significant.
Finally, the table provides the Mean Difference and the 95% Confidence Interval of the Difference. The Mean Difference is simply the sample mean minus the test value (14.3333 – 15 = -0.6667). The confidence interval provides a range for this difference. If the interval includes zero—as it does in this case—it signifies that there is a plausible chance that the true difference is zero, which aligns with our decision to fail to reject the null hypothesis.
Concluding the Analysis and Reporting Findings
The final step in the process of performing a One Sample t-test in IBM SPSS Statistics is the synthesis and reporting of the results. For the botanist, the statistical evidence was insufficient to reject the null hypothesis. This means that, although the sample mean of 14.3333 inches was numerically different from 15 inches, the difference did not reach the threshold of statistical significance. Consequently, the botanist cannot claim that this species of plant has a mean height different from 15 inches based on this specific sample.
When reporting these findings in a formal paper or report, it is standard practice to include the t-statistic, the degrees of freedom, and the p-value. A typical summary might read: “A One Sample t-test was conducted to compare the mean height of a plant species to a hypothesized population mean of 15 inches. The results indicated that the sample mean (M = 14.33, SD = 1.37) was not significantly different from the population mean, t(11) = -1.685, p = .120.” Such reporting ensures that the statistical analysis is transparent and reproducible.
It is also important to discuss the implications of the findings. Failing to reject the null hypothesis does not necessarily prove that the population mean is exactly 15 inches; rather, it indicates that the current data does not provide enough evidence to suggest otherwise. Factors such as a small sample size (N=12) can lead to low statistical power, potentially resulting in a Type II error (failing to detect a real difference). Researchers should consider these limitations when interpreting their results in IBM SPSS Statistics.
In conclusion, the One Sample t-test is a powerful yet accessible tool for hypothesis testing. By following the structured workflow within IBM SPSS Statistics—from data preparation and hypothesis formulation to navigating menus and interpreting output—researchers can derive meaningful insights from their data. Whether in botany, medicine, or the social sciences, mastering this test is a vital skill for anyone engaged in quantitative research and data analysis.
Cite this article
stats writer (2026). How to Perform a One-Sample t-Test in SPSS and Determine Statistical Significance. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-do-you-perform-a-one-sample-t-test-in-spss/
stats writer. "How to Perform a One-Sample t-Test in SPSS and Determine Statistical Significance." PSYCHOLOGICAL SCALES, 14 Mar. 2026, https://scales.arabpsychology.com/stats/how-do-you-perform-a-one-sample-t-test-in-spss/.
stats writer. "How to Perform a One-Sample t-Test in SPSS and Determine Statistical Significance." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-do-you-perform-a-one-sample-t-test-in-spss/.
stats writer (2026) 'How to Perform a One-Sample t-Test in SPSS and Determine Statistical Significance', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-do-you-perform-a-one-sample-t-test-in-spss/.
[1] stats writer, "How to Perform a One-Sample t-Test in SPSS and Determine Statistical Significance," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Perform a One-Sample t-Test in SPSS and Determine Statistical Significance. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.