Table of Contents
The R programming language provides a robust environment for statistical computing and graphics, offering users a wide array of functions to refine their data visualization efforts. One such essential tool is the jitter function, which is specifically designed to address the common challenge of overplotting in graphical representations. When datasets contain numerous observations with identical or very similar values, data points often overlap on a plot, creating a single visual cluster that obscures the actual density and distribution of the underlying data. By introducing a small amount of random noise to the coordinates of these points, the jitter function allows each individual observation to be perceived, thereby providing a more honest and clear representation of the dataset’s structure.
In the context of exploratory data analysis, the ability to discern patterns and outliers is paramount. When data points are perfectly aligned, especially in cases involving discrete variables, the viewer may be misled regarding the volume of data at a particular coordinate. The jitter function effectively “shakes” these points slightly from their original positions. This technique is not intended to change the fundamental meaning of the data but rather to enhance its visual clarity. By using this function, researchers and data scientists can adjust the amount of noise added, ensuring that the scatterplot remains both accurate and informative, particularly when dealing with high-dimensional or high-volume datasets where overlapping is an inevitable byproduct of the measurement scale.
Ultimately, the successful application of the jitter function in R can significantly aid in the interpretation of complex relationships between variables. Whether one is examining biological measurements, financial trends, or sports statistics, the clarity provided by jittering ensures that the visual narrative told by the data is complete. This tutorial will explore the practical applications of this function, demonstrating how to move from standard, potentially cluttered plots to refined visualizations that better communicate the reality of the distribution. Through the following sections, we will delve into specific code examples and scenarios where jittering becomes a critical step in the visualization pipeline.
Understanding the Core Mechanics of Jittering
At its fundamental level, the jitter function works by taking a numeric vector and adding a series of small, random values to each element. This process is governed by a uniform distribution, ensuring that the displacement is relatively balanced around the original value. In R, this is often necessary because digital datasets frequently contain rounded values or measurements taken on a fixed scale, which naturally leads to “ties” or identical values. Without jittering, these ties would occupy the exact same pixel on a screen or printer, effectively hiding the sample size from the observer.
The versatility of the jitter function lies in its simplicity and its ability to be integrated directly into plotting commands. When a user calls the function, R calculates a “factor” based on the range of the data and the number of unique values present. This ensures that the noise added is proportional to the scale of the variable, preventing the noise from being so large that it changes the perceived category of a discrete variable or so small that it fails to separate the overlapping data points. This automated scaling is one of the reasons why the function is so widely used in the R community.
Beyond the default settings, the function allows for manual overrides of the “amount” of noise applied. This is crucial for professional analysts who need to strike a balance between visual separation and data integrity. If the noise is too subtle, the overplotting remains unresolved; if it is too aggressive, the data may appear chaotic and lose its logical structure. Therefore, understanding how to calibrate the jitter function is a key skill for anyone looking to produce high-quality data visualizations that are suitable for publication or decision-making processes.
Establishing a Baseline with Continuous Scatterplots
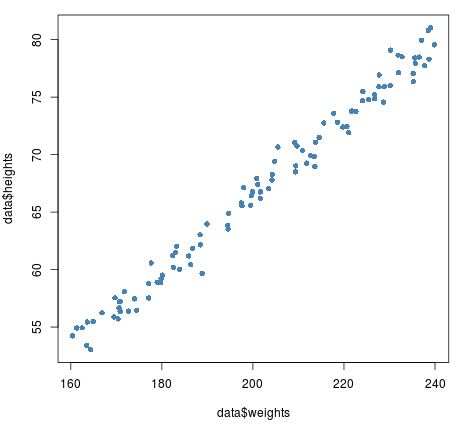
To appreciate the utility of jittering, one must first understand how scatterplots function under ideal conditions. Scatterplots are primarily used to visualize the relationship between two continuous variables. In such cases, because the variables can take on an infinite number of values within a range, the probability of two points having the exact same coordinates is statistically low. For instance, consider a dataset representing the physiological metrics of athletes, such as height and weight. These values are typically measured with enough precision that each athlete’s position on a grid is unique.
The following example demonstrates a standard scatterplot using the plot() function in R. We define vectors for weights and heights using random number generation to simulate a realistic population of 100 athletes. Since both variables are continuous and have high variance, the resulting plot naturally spaces the points out, allowing for a clear visual assessment of the correlation between the two metrics.
#define vectors of heights and weights weights <- runif(100, 160, 240) heights <- (weights/3) + rnorm(100) #create data frame of heights and weights data <- as.data.frame(cbind(weights, heights)) #view first six rows of data frame head(data) # weights heights #1 170.8859 57.20745 #2 183.2481 62.01162 #3 235.6884 77.93126 #4 231.9864 77.12520 #5 200.8562 67.93486 #6 169.6987 57.54977 #create scatterplot of heights vs weights plot(data$weights, data$heights, pch = 16, col = 'steelblue')

In this visualization, the relationship is easily identifiable: as weight increases, height generally increases as well. The steelblue points are distinct, and the viewer can easily see where the data is most concentrated. However, this clarity is a luxury of continuous data. When we move toward datasets that involve categorical or discrete data, the visual integrity of the plot begins to break down, necessitating a different approach to data exploration.
The Challenge of Visualizing Discrete Variables
The limitations of standard scatterplots become evident when one of the variables is a discrete variable. Discrete variables consist of distinct, separate values, such as integers or categories. For example, in sports analytics, the number of games a player has started is a discrete value (e.g., 1, 2, or 3 games). If we plot this against a continuous variable like average points per game, we encounter a significant visual problem. Because many players will have started the exact same number of games, their data points will stack vertically on top of one another.
Consider a scenario where we analyze 300 basketball players. Many players will share the same integer value for “games started,” while their “points per game” will vary slightly. When we attempt to plot this using standard methods, we create vertical columns of points. This results in overplotting, where it is impossible to tell if a specific location on the plot represents a single player or fifty players. The following R code generates such a dataset and illustrates the resulting visual congestion.
#create data frame games_started <- sample(1:10, 300, TRUE) points_per_game <- 3*games_started + rnorm(300) data <- as.data.frame(cbind(games_started, points_per_game)) #view first six rows of data frame head(data) # games_started points_per_game #1 9 25.831554 #2 9 26.673983 #3 10 29.850948 #4 4 12.024353 #5 4 11.534192 #6 1 4.383127
While we can observe a positive linear relationship between the variables, the plot itself is misleading. The vertical strips of data hide the true density of the observations. This lack of transparency can lead to incorrect conclusions during the statistical analysis phase, as the viewer might assume an equal distribution of players across all game counts, when in reality, some categories might be much more heavily populated than others. This is where the jitter function becomes indispensable.
#create scatterplot of games started vs average points per game
plot(data$games_started, data$points_per_game, pch = 16, col = 'steelblue')
Applying Jitter to Improve Visual Clarity
To resolve the overplotting seen in the previous example, we can wrap the independent variable (games started) in the jitter function. By doing so, we instruct R to add a marginal amount of random noise to the x-axis values. The effect is immediate: the rigid vertical lines are “smudged” into clouds of points. This allows the viewer to see the individual data points that were previously hidden behind one another, providing a much more accurate sense of where the data actually lies.
The beauty of the jitter function in R is that it preserves the overall categorical integrity of the data while enhancing visibility. Even though the points are no longer perfectly aligned with the integers on the x-axis, their proximity to those integers remains clear. This allows for a better visual estimation of the variance within each group. In the code below, notice how the application of jittering transforms the previous “strip” plot into a much more readable and informative scatterplot.
#add jitter to games started plot(jitter(data$games_started), data$points_per_game, pch = 16, col = 'steelblue')

By using this technique, we have successfully mitigated the issue of overplotting. The resulting visualization is not only more aesthetically pleasing but also more scientifically rigorous, as it represents the sample size more accurately. This step is a hallmark of professional graphic representation in data science, ensuring that no information is lost due to the technical limitations of the plotting medium or the nature of the measurement scale.
Fine-Tuning Noise with the Amount Argument
While the default settings of the jitter function are often sufficient, R allows users to customize the intensity of the noise through an optional numeric argument, often referred to as the amount or factor. This parameter acts as a multiplier, increasing or decreasing the range of the random noise added to the data points. Adjusting this value is a balancing act; you want enough noise to separate the points, but not so much that the data becomes unrecognizable or misleading regarding its original category.
In the following example, we increase the jitter factor to 2. This spreads the points out even further along the x-axis, which can be particularly helpful when dealing with exceptionally large datasets where even a small amount of jittering might not be enough to resolve overplotting. By widening the “cloud” of points for each discrete value, we gain an even clearer view of the density of players within each game-start category.
#add jitter to games started plot(jitter(data$games_started, 2), data$points_per_game, pch = 16, col = 'steelblue')

However, it is vital to exercise caution when manually adjusting these parameters. If the noise level is set too high—for example, a factor of 20—the points from one category will begin to overlap with the points from adjacent categories. This creates a “smearing” effect that effectively destroys the distinction between the levels of the discrete variable. As shown in the image below, excessive jittering turns a structured plot into a disorganized mess, making it impossible to perform accurate data analysis or visualization.
plot(jitter(data$games_started, 20), data$points_per_game, pch = 16, col = 'steelblue')

Using Jitter to Reveal Hidden Data Density
One of the most powerful aspects of jittering is its ability to reveal differences in data density across different categories. In many real-world datasets, the number of observations is not evenly distributed. Some groups may contain hundreds of points, while others contain only a few. In a standard scatterplot, these groups might look identical because the points are stacked on top of each other. Jittering exposes these “hidden” volumes by spreading the points out, where larger clouds of points indicate higher frequency.
To illustrate this, let’s create a dataset where the number of players who started 2 games is significantly higher than those in other categories. We will combine a data frame of 100 players distributed across 5 categories with an additional 200 players who specifically started 2 games. Without jittering, the column for “2 games” will look similar to the others, perhaps only appearing slightly “thicker” or darker, which is a poor visual indicator of a 200% increase in sample size.
games_started <- sample(1:5, 100, TRUE)
points_per_game <- 3*games_started + rnorm(100)
data <- as.data.frame(cbind(games_started, points_per_game))
games_twos <- rep(2, 200)
points_twos <- 3*games_twos + rnorm(200)
data_twos <- as.data.frame(cbind(games_twos, points_twos))
names(data_twos) <- c('games_started', 'points_per_game')
all_data <- rbind(data, data_twos)When we visualize this combined dataset using a standard plot, the disparity in group sizes is largely obscured. It is difficult for the human eye to quantify exactly how many more players are in the “2 games” group compared to the others. This is a classic case where overplotting prevents the viewer from understanding the true composition of the population under study.
plot(all_data$games_started, all_data$points_per_game, pch = 16, col = 'steelblue')

Optimizing Scatterplots for Sample Size Visualization
By applying the jitter function to our density-heavy dataset, the difference between the groups becomes strikingly apparent. The “2 games” category expands into a much larger, denser cluster of points, while the other categories remain sparse. This visual feedback is essential for statistical inference, as it highlights where the most reliable data (in terms of sample size) is located within the study. This technique is often used in academic research to provide a more transparent view of experimental results.
If the default jitter is still not enough to convey the sheer volume of data, we can increase the factor slightly to 1.5. This further spreads the 200 additional points, making the concentration even more obvious. Using jittering in this way allows a scatterplot to function almost like a violin plot or a histogram, combining the benefits of showing individual raw data points with the ability to see the overall shape and density of the distribution.
plot(jitter(all_data$games_started), all_data$points_per_game,
pch = 16, col = 'steelblue')
As we see in the final code block, the visual representation is now an accurate reflection of the data’s complexity. The observer can immediately identify that the majority of the data is centered around the two-game mark, and they can also see the outliers and the spread of points per game within that specific group. This level of detail is simply impossible to achieve with standard plotting techniques alone.
plot(jitter(all_data$games_started, 1.5), all_data$points_per_game, pch = 16, col = 'steelblue')

Important Distinction: Jittering for Visualization Only
While the jitter function is a powerful ally in the realm of data visualization, it is critical to understand its limitations and proper usage. Jittering is a cosmetic transformation; it fundamentally alters the values of the data for the purpose of display. Because it introduces random noise, it should never be used as a preprocessing step for actual statistical analysis. If you were to run a linear regression or calculate a mean on jittered data, your results would be slightly different every time you ran the code due to the randomness involved.
In a professional workflow, the “jittered” values should exist only within the scope of the plotting function. Your primary data frame must remain untouched to preserve the integrity of the original observations. Using jittered data in calculations would violate the principles of reproducibility and accuracy, as you would be analyzing noise rather than signal. Therefore, always remember: jitter is for the eyes, not for the algorithms.
To summarize, the jitter function in R is an essential tool for creating high-quality, transparent scatterplots. It solves the problem of overplotting, reveals hidden data density, and allows for a more nuanced interpretation of relationships between variables. By following the best practices outlined in this tutorial, you can ensure that your visualizations are both beautiful and scientifically sound. Some key takeaways include:
- Use jitter() to separate overlapping points in scatterplots.
- Apply jittering primarily when dealing with discrete variables or rounded continuous data.
- Control the amount of noise using the numeric factor argument to maintain data context.
- Avoid over-jittering to prevent data distortion and category merging.
- Never use jittered data for regression analysis or other statistical modeling.
By mastering this simple yet effective function, you will significantly improve your ability to communicate complex data stories through the power of R.
Cite this article
stats writer (2026). How to Create Clearer Scatterplots in R Using the Jitter Function. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-can-the-jitter-function-in-r-be-used-to-create-scatterplots/
stats writer. "How to Create Clearer Scatterplots in R Using the Jitter Function." PSYCHOLOGICAL SCALES, 3 Mar. 2026, https://scales.arabpsychology.com/stats/how-can-the-jitter-function-in-r-be-used-to-create-scatterplots/.
stats writer. "How to Create Clearer Scatterplots in R Using the Jitter Function." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-can-the-jitter-function-in-r-be-used-to-create-scatterplots/.
stats writer (2026) 'How to Create Clearer Scatterplots in R Using the Jitter Function', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-can-the-jitter-function-in-r-be-used-to-create-scatterplots/.
[1] stats writer, "How to Create Clearer Scatterplots in R Using the Jitter Function," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Create Clearer Scatterplots in R Using the Jitter Function. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.