Table of Contents
The Elbow Method in Python is a crucial data analysis technique used to systematically determine the optimal number of clusters (K) for a given dataset. This methodology relies on calculating the Sum of Squared Errors (SSE)—also known as inertia—for a range of cluster counts. By plotting the SSE against the number of clusters, data scientists look for a specific inflection point.
The optimal cluster count corresponds to the value of K where the Sum of Squared Errors begins to decrease at a much slower rate, visually resembling the “elbow” of an arm. Implementing this technique is straightforward using robust Python libraries like Scikit-Learn, making it an essential tool for effective cluster analysis.
One of the most common and foundational clustering algorithms in data science is known as k-means clustering.
K-means clustering is an unsupervised learning technique in which we partition a set of ‘n’ observations into K distinct clusters. The ultimate objective is to achieve a state where the observations within each cluster are highly similar to one another, while observations placed in different clusters exhibit significant dissimilarity based on their features.
Crucially, when initiating k-means clustering, the first operational decision involves selecting an appropriate integer value for K—the desired number of clusters. If K is chosen poorly, the resulting segmentation may be ineffective or misleading. The most reliable method for making this determination is known as the elbow method.
The Elbow Method involves generating a scatter plot where the total within sum of squares (SSE) is plotted against the number of clusters (K). By analyzing the curve, we identify the clear bend or “elbow” point. The value on the x-axis corresponding to the “elbow” indicates the mathematically optimal number of clusters to use for our analysis. The following detailed example walks through implementing the Elbow Method step-by-step using Python.
Step 1: Import Necessary Modules
To begin our cluster analysis, we must first ensure that all required computational libraries are loaded into our Python environment. These modules facilitate data handling, numerical computation, visualization, and the execution of the clustering algorithm itself. We rely heavily on Pandas for efficient data manipulation, NumPy for foundational array operations, Matplotlib for plotting the essential SSE curve, and specialized components from Scikit-Learn for clustering and preprocessing.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScalerIt is important to note that we are importing the KMeans class, which is the core clustering function, and StandardScaler, which is vital for preparing our data. The latter transforms our feature set by scaling the data, a critical step that ensures all variables contribute equally to the distance calculations inherent in the k-means algorithm, regardless of their original magnitude.
Step 2: Create and Preprocess the Dataset
Next, we construct a synthetic dataset simulating statistics for 20 basketball players, tracking three key performance metrics: points, assists, and rebounds. This data is housed within a Pandas DataFrame. This structure is essential for applying efficient data cleaning and transformation methods in Python.
Before clustering can occur, we must address missing values (represented by `np.nan`). Because k-means clustering cannot handle incomplete data, we use the `dropna()` method to remove any rows containing missing entries. Subsequently, we apply the StandardScaler to normalize the remaining data. Scaling transforms the variables such that they possess a mean of 0 and a standard deviation of 1, effectively removing bias caused by differing measurement units or scales.
#create DataFrame
df = pd.DataFrame({'points': [18, np.nan, 19, 14, 14, 11, 20, 28, 30, 31,
35, 33, 29, 25, 25, 27, 29, 30, 19, 23],
'assists': [3, 3, 4, 5, 4, 7, 8, 7, 6, 9, 12, 14,
np.nan, 9, 4, 3, 4, 12, 15, 11],
'rebounds': [15, 14, 14, 10, 8, 14, 13, 9, 5, 4,
11, 6, 5, 5, 3, 8, 12, 7, 6, 5]})
#drop rows with NA values in any columns
df = df.dropna()
#create scaled DataFrame where each variable has mean of 0 and standard dev of 1
scaled_df = StandardScaler().fit_transform(df)
Step 3: Implement the Elbow Method to Find Optimal K
We aim to use k-means clustering to group players based on their performance metrics. Since the ideal number of clusters is unknown, we must apply the Elbow Method. This involves iterating through a range of possible cluster counts and recording the resulting cluster inertia.
The KMeans function requires specifying n_clusters. To execute the Elbow Method, we iterate from K=1 to K=10, fitting the model to the scaled_df in each loop. For every fitted model, we retrieve the SSE (inertia) and store it in a list. This iterative process generates the necessary data points for our visualization.
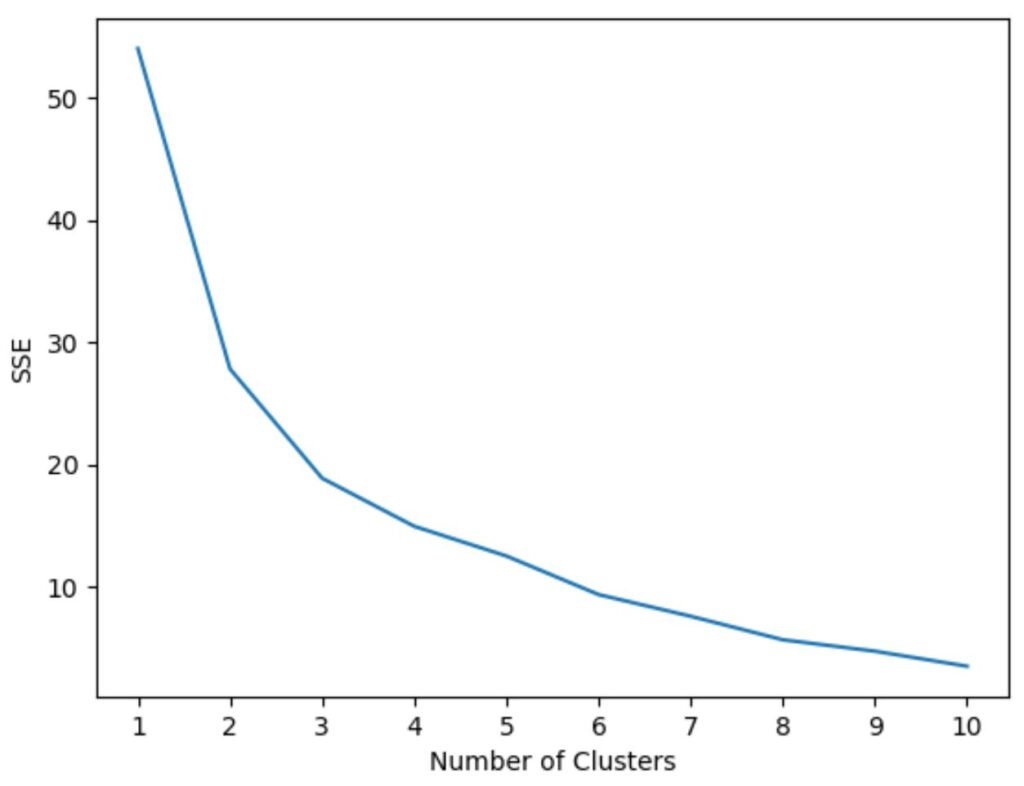
Finally, we plot the number of clusters (K) against the collected SSE values. This visualization is critical for identifying the “elbow”—the point where the marginal gain from adding an extra cluster (i.e., the reduction in SSE) ceases to be substantial. This inflection point objectively determines the optimal value for K.
#initialize kmeans parameters kmeans_kwargs = { "init": "random", "n_init": 10, "random_state": 1, } #create list to hold SSE values for each k sse = [] for k in range(1, 11): kmeans = KMeans(n_clusters=k, **kmeans_kwargs) kmeans.fit(scaled_df) sse.append(kmeans.inertia_) #visualize results plt.plot(range(1, 11), sse) plt.xticks(range(1, 11)) plt.xlabel("Number of Clusters") plt.ylabel("SSE") plt.show()

Upon reviewing the generated plot, a distinct inflection point or “bend” is clearly visible at k = 3 clusters. This empirical result provides a strong indication that three is the optimal number of groups for segmenting our basketball player data, and we will proceed with this value in the next step to fit our final clustering model.
Step 4: Perform K-Means Clustering with Optimal K
With the optimal number of clusters (K=3) determined via the Elbow Method, we now execute the final k-means clustering algorithm on our scaled dataset. We instantiate the KMeans object, ensuring the n_clusters parameter is correctly set to 3. The parameters chosen for the final run should mirror those used during the Elbow calculation to ensure consistency.
After fitting the model to the scaled_df, the resulting cluster assignments for every observation are generated and stored in the labels_ attribute of the KMeans object. This array provides an integer index (0, 1, or 2) indicating the cluster membership for each of the 18 cleaned player entries.
#instantiate the k-means class, using optimal number of clusters
kmeans = KMeans(init="random", n_clusters=3, n_init=10, random_state=1)
#fit k-means algorithm to data
kmeans.fit(scaled_df)
#view cluster assignments for each observation
kmeans.labels_
array([1, 1, 1, 1, 1, 1, 2, 2, 0, 0, 0, 0, 2, 2, 2, 0, 0, 0])
Step 5: Interpreting and Reviewing Cluster Assignments
To make the results actionable and easily interpretable, we must associate the numerical cluster labels back to our original dataset containing the raw performance metrics. This is achieved by creating a new column named ‘cluster’ within our original Pandas DataFrame and populating it with the values from the `kmeans.labels_` array.
The resulting updated DataFrame clearly shows which cluster (0, 1, or 2) each player was assigned to. By examining the values for the points, assists, and rebounds columns within each cluster group, analysts can now profile the typical characteristics of players within each segment, revealing meaningful patterns in the data that were not apparent before clustering.
#append cluster assingments to original DataFrame
df['cluster'] = kmeans.labels_
#view updated DataFrame
print(df)
points assists rebounds cluster
0 18.0 3.0 15 1
2 19.0 4.0 14 1
3 14.0 5.0 10 1
4 14.0 4.0 8 1
5 11.0 7.0 14 1
6 20.0 8.0 13 1
7 28.0 7.0 9 2
8 30.0 6.0 5 2
9 31.0 9.0 4 0
10 35.0 12.0 11 0
11 33.0 14.0 6 0
13 25.0 9.0 5 0
14 25.0 4.0 3 2
15 27.0 3.0 8 2
16 29.0 4.0 12 2
17 30.0 12.0 7 0
18 19.0 15.0 6 0
19 23.0 11.0 5 0
The resulting cluster column confirms that players grouped together share roughly similar values across the measured statistical categories. This successful segmentation validates the utility of using the Elbow Method to achieve robust and meaningful clusters. For further technical details, you can find the complete documentation for the KMeans function on the official Scikit-Learn website.
Further Resources on Python Data Analysis
Mastering the Elbow Method is just one step in leveraging Python for advanced data segmentation. We encourage you to explore other essential tutorials that explain how to perform additional common tasks in data science:
- How to calculate descriptive statistics in Pandas for detailed exploratory analysis.
- Implementing hierarchical clustering algorithms for different types of segmentation problems.
- Techniques for advanced data visualization using Matplotlib and other charting libraries.
Cite this article
stats writer (2025). How to Easily Find Optimal Clusters with the Elbow Method in Python. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-can-i-use-the-elbow-method-in-python-to-find-optimal-clusters/
stats writer. "How to Easily Find Optimal Clusters with the Elbow Method in Python." PSYCHOLOGICAL SCALES, 21 Nov. 2025, https://scales.arabpsychology.com/stats/how-can-i-use-the-elbow-method-in-python-to-find-optimal-clusters/.
stats writer. "How to Easily Find Optimal Clusters with the Elbow Method in Python." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/how-can-i-use-the-elbow-method-in-python-to-find-optimal-clusters/.
stats writer (2025) 'How to Easily Find Optimal Clusters with the Elbow Method in Python', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-can-i-use-the-elbow-method-in-python-to-find-optimal-clusters/.
[1] stats writer, "How to Easily Find Optimal Clusters with the Elbow Method in Python," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, November, 2025.
stats writer. How to Easily Find Optimal Clusters with the Elbow Method in Python. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.