Table of Contents
Count Number of Occurrences in Power BI
Introduction: The Importance of Frequency Analysis in Business Intelligence
Counting the number of occurrences in Power BI refers to the fundamental process of determining the frequency of a specific data point or categorical value within a larger dataset. This analytical technique is absolutely crucial in the realm of Business Intelligence, as it allows analysts to quickly transform raw transaction records into meaningful insights regarding distribution, popularity, and concentration. By quantifying how often certain events, products, or customer segments appear, organizations can move beyond surface-level data consumption and begin to identify significant patterns or potentially problematic trends that require immediate attention.
In the robust environment of Power BI, achieving accurate occurrence counts requires leveraging the powerful capabilities of the Data Analysis Expressions (DAX) language. While simple functions like COUNT and COUNTROWS can provide aggregate measures for entire tables or filtered subsets, counting occurrences within a specific column, particularly when creating a new, persistent column that reflects row-level frequency, demands a more advanced implementation. This typically involves combining iterative functions with context transition mechanisms to accurately look up and count matching values throughout the entire table for every single row.
The core challenge lies in shifting the analytical focus from a simple aggregation (counting all rows) to a detailed, row-by-row calculation that assesses the frequency relative to the rest of the column. Mastering this technique using DAX is essential for creating dynamic, data-rich reports. This comprehensive guide will detail the specific formula required, explain the underlying logic of context manipulation (specifically using the EARLIER function), and walk through a practical example demonstrating how to implement an occurrence count as a new Calculated Column in your data model.
Understanding the DAX Syntax for Calculating Occurrences
To calculate the number of occurrences of each value within a column in Power BI, we must utilize a specific combination of DAX functions designed to operate across different evaluation contexts. The goal is to establish a distinct Row Context for the calculation, compare the current row’s value against all values in the column, filter the table based on that comparison, and then count the resulting rows.
The following syntax structure is the standard and most efficient method used in DAX for performing this type of self-referential row counting. This formula is typically employed when defining a new Calculated Column, ensuring that the frequency count is available directly alongside the original data point for immediate analysis or visualization filtering.
You can use the following syntax in DAX to calculate the number of occurrences of each value in a column in Power BI:
occurrences =
COUNTX(
FILTER( 'my_data', EARLIER('my_data'[Team]) = 'my_data'[Team] ),
'my_data'[Team]
)
This particular example demonstrates how to count the number of occurrences for each unique entry found in the Team column of the table designated as my_data. The result is a numerical value placed on every row, reflecting the total count of times the specific team name in that row appears within the entire dataset. Understanding how the three primary functions—COUNTX, FILTER, and EARLIER—interact is essential for successful implementation and troubleshooting.
Deep Dive: The Role of COUNTX, FILTER, and EARLIER
To fully appreciate the elegance and power of the occurrence formula, we must break down the purpose of each function involved, particularly how they manage the context of evaluation in DAX. The calculation is structured as an iterator, where COUNTX is the outer function responsible for counting the values returned by the inner expression.
The core logic resides within the FILTER function. This function takes the entire table (‘my_data’) as its first argument and iterates through it, applying a Boolean condition defined by the second argument. The key to the occurrence count is ensuring that the condition correctly identifies rows where the value matches the value of the row currently being calculated. Since a Calculated Column inherently creates a Row Context (meaning the formula is evaluated row by row), we need a way to reference the value from the current, external row context while iterating over the entire table in an internal context.
This is precisely where the EARLIER function becomes indispensable. EARLIER is designed to retrieve the value of a specified column in a preceding, outer Row Context. In the expression EARLIER('my_data'[Team]) = 'my_data'[Team], EARLIER freezes the team name from the row being calculated, while 'my_data'[Team] references the team name of the row currently being evaluated internally by the FILTER function. The result is a virtual table containing only those rows that match the team name of the current row, which COUNTX then counts to provide the final frequency number.
Practical Implementation: Example Walkthrough
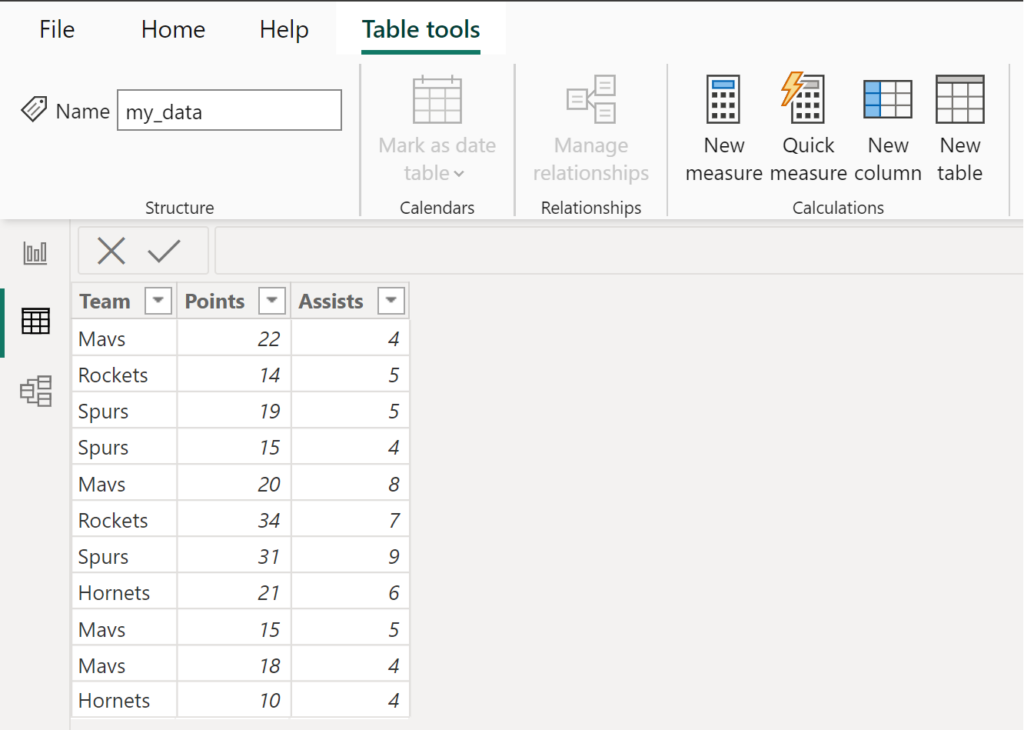
To illustrate the application of this powerful DAX formula, let us consider a practical scenario involving sales data where we need to quickly identify the concentration of activities per team. We begin with a simple dataset loaded into Power BI, which we have named my_data. This table includes basic identifying information and a categorical column, Team, whose frequency we wish to analyze.
Suppose we have the following table in Power BI named my_data:

Our objective is clear: we intend to add a supplementary column to this existing table that automatically calculates and displays the count of occurrences for the value present in the Team column on that specific row. This new Calculated Column will provide immediate context for data quality checks or subsequent calculations, such as percentage contribution per team.
The process of adding the Calculated Column starts within the Data view or Model view in Power BI Desktop. To initiate the calculation, the user must navigate to the table tools context menu and select the option to define a new column. This action opens the formula bar, enabling the entry of the complex DAX expression detailed previously.
Step-by-Step: Creating the Calculated Column
The process begins by explicitly defining the space for the new calculation. To add the necessary column that contains the count of occurrences of each value in the Team column, you must first access the table modification tools.
To do so, click the New column icon, typically found in the Table Tools tab when the table is selected in the Data View:

Once the formula bar appears, it is necessary to input the precise DAX logic that utilizes the nested context evaluation mechanism. This step requires careful typing of the formula to ensure correct referencing of the table name (‘my_data’) and the target column name (‘Team’).
Then type in the following formula into the formula bar:
occurrences =
COUNTX(
FILTER( 'my_data', EARLIER('my_data'[Team]) = 'my_data'[Team] ),
'my_data'[Team]
)Upon committing this formula, Power BI will iterate through every single row of the my_data table. For each row, the EARLIER function captures the current team name, and the FILTER function applies this captured value as a filter across the entire table. Finally, COUNTX returns the number of rows that satisfy the criteria.
Analyzing the Resulting Data Structure
Successful execution of the DAX formula results in a new column named occurrences being appended to the my_data table. This column is dynamically calculated and updated whenever the underlying data source is refreshed, maintaining the integrity of the frequency count across the entire dataset.
This will create a new column named occurrences that contains the count of occurrences of each value in the Team column:

By inspecting the output, we can immediately verify the accuracy of the calculation and see how the frequency distribution looks. Notice that the value in the occurrences column remains constant for all rows sharing the same value in the Team column, accurately reflecting their aggregate frequency across the entire table, regardless of the individual row’s position.
For example, we can observe the following frequency distributions calculated by the DAX formula:
- The team name Mavs occurs 4 times, meaning every row associated with ‘Mavs’ now displays the count ‘4’.
- The team name Rockets occurs 2 times, providing the count ‘2’ consistently across all ‘Rockets’ rows.
- The team name Spurs occurs 3 times, resulting in the number ‘3’ for each instance of ‘Spurs’.
This mechanism effectively denormalizes the frequency count, making it accessible for row-level operations or for quick visual analysis without needing to resort to custom measures or complex visualizations just to display simple frequency.
Alternative DAX Approaches: Grouping and Summarization
While the Calculated Column method using EARLIER is excellent for appending the frequency directly to the transactional data, it is not the only way to analyze occurrences in Power BI. For scenarios where the analyst requires a summarized table of frequencies rather than a row-level column, DAX provides functions like SUMMARIZE or SUMMARIZECOLUMNS.
If the goal is purely to generate a unique list of teams and their respective total counts for display in a report table or chart, the following approach creating a new table might be preferred:
TeamFrequencyTable =
SUMMARIZE(
'my_data',
'my_data'[Team],
"Total Occurrences", COUNT('my_data'[Team])
)
This formula generates a new, smaller table that lists each unique team and their corresponding count. This method is often more memory-efficient when the primary requirement is aggregation reporting rather than row-by-row context. However, it does not allow the count to be used directly in context with other row-level attributes of the original data model, which is why the Row Context and EARLIER method remains the standard for creating persistent Calculated Column frequencies.
Further Learning and Conclusion
Mastering context transition and iterative functions like COUNTX, FILTER, and EARLIER is fundamental for any serious DAX user. The technique detailed here for counting occurrences is a foundational pattern that can be adapted for more complex scenarios, such as counting unique values within a group or performing conditional frequency analysis. Continuous learning in these areas will unlock the full potential of data modeling within Power BI.
The following tutorials explain how to perform other common tasks in Power BI:
Cite this article
stats writer (2026). How to Count Occurrences in Power BI: A Step-by-Step Guide. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-can-i-count-the-number-of-occurrences-in-power-bi-2/
stats writer. "How to Count Occurrences in Power BI: A Step-by-Step Guide." PSYCHOLOGICAL SCALES, 29 Jan. 2026, https://scales.arabpsychology.com/stats/how-can-i-count-the-number-of-occurrences-in-power-bi-2/.
stats writer. "How to Count Occurrences in Power BI: A Step-by-Step Guide." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-can-i-count-the-number-of-occurrences-in-power-bi-2/.
stats writer (2026) 'How to Count Occurrences in Power BI: A Step-by-Step Guide', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-can-i-count-the-number-of-occurrences-in-power-bi-2/.
[1] stats writer, "How to Count Occurrences in Power BI: A Step-by-Step Guide," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, January, 2026.
stats writer. How to Count Occurrences in Power BI: A Step-by-Step Guide. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.