Table of Contents
Understanding the Foundations of the Friedman Test
The Friedman Test represents a vital tool in the arsenal of researchers who deal with related samples and non-normal data distributions. Developed by the renowned economist Milton Friedman, this non-parametric statistics method serves as the logical alternative to the Repeated Measures ANOVA when the rigorous assumptions of parametric testing cannot be satisfied. Specifically, it is designed to detect differences in treatments across multiple test attempts, making it ideal for longitudinal studies or experiments where the same subjects are exposed to various conditions. By focusing on the ranking of data rather than the raw values themselves, the test provides a robust mechanism for analysis that is resistant to the influence of outliers and extreme variance.
One of the primary reasons a statistician might opt for the Friedman Test over its parametric counterparts is the absence of a normal distribution within the dataset. In many real-world scenarios, particularly in psychology and medicine, data often exhibit skewness or kurtosis that violates the requirements for an ANOVA. Furthermore, the Friedman Test does not require the assumption of sphericity or homogeneity of variance, which frequently complicates the analysis of related groups. Consequently, it offers a more flexible approach for ordinal data or continuous data that fails to meet the stringent criteria of interval-level measurement.
In practice, the test operates by ranking the scores for each subject across the different conditions being compared. For instance, if a subject is tested under four different drug conditions, their quickest reaction time would receive a rank of 1, the second quickest a rank of 2, and so on. These ranks are then summed for each condition across all subjects to determine if the distribution of ranks differs significantly from what would be expected under the null hypothesis. This focus on relative position rather than absolute magnitude ensures that the test remains powerful even when the underlying data scales are inconsistent or non-linear.
Determining Suitability and Research Hypotheses
Before initiating the Friedman Test within SPSS, it is crucial to establish whether your research design justifies its application. The test is specifically tailored for related samples, meaning that each participant must contribute a data point to every single condition or time point being analyzed. This dependency is a hallmark of “within-subjects” designs, where the goal is to observe how the same individual changes or reacts under different stimuli. If your groups are independent—meaning different people are in each group—you should instead look toward the Kruskal-Wallis test.
The null hypothesis for a Friedman Test typically posits that there is no difference in the distributions of the various groups, implying that the medians of the related populations are identical. Conversely, the alternative hypothesis suggests that at least one group differs significantly from the others. It is important to note that, like the ANOVA, the Friedman Test is an omnibus test. This means it can tell you that a difference exists somewhere among your groups, but it cannot pinpoint exactly which pairs of groups are different. Such determination requires subsequent post-hoc analysis.
Research questions suitable for this analysis often involve repeated measures over time or comparisons across multiple treatments. For example, a researcher might want to evaluate the efficacy of three different teaching methods on the same group of students or assess the pain levels of patients at four different intervals following a surgical procedure. By employing the Friedman Test, the researcher can account for the inherent variability between individual subjects, as each subject effectively serves as their own control. This sensitivity to individual differences is a major advantage of the related-samples design.
Step 1: Data Preparation and Organization in SPSS
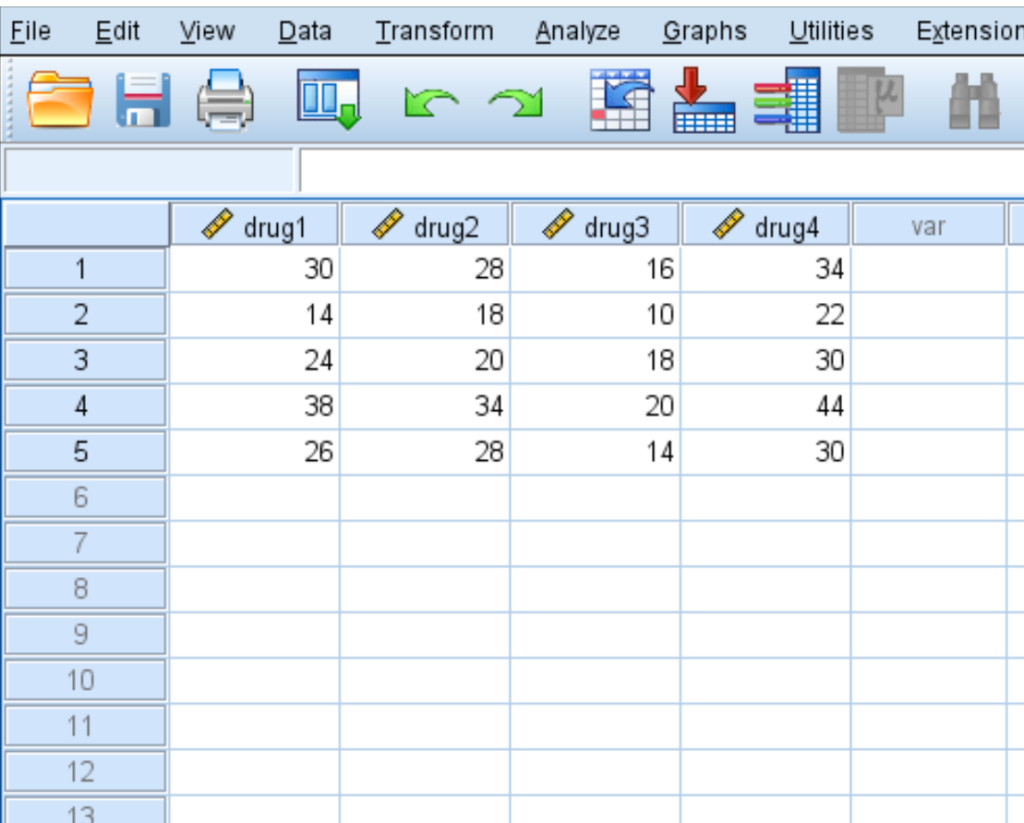
The first practical step in performing the analysis is the accurate entry of data into the SPSS Data View. Unlike some other software packages that prefer “long format” data, SPSS requires “wide format” for the Friedman Test. This means that each row in your spreadsheet must represent a single subject (a patient, a student, or a trial), and each column must represent one of the related conditions or time points. If you have five patients being tested on four different drugs, your dataset should consist of five rows and four columns of data.
Accuracy during this phase is paramount, as any misalignment of data points will invalidate the statistical significance of your results. Ensure that each column is clearly labeled with a descriptive variable name, such as “Drug_A,” “Drug_B,” etc., to avoid confusion during the selection process. You should also define the measure level for these variables in the Variable View; although the Friedman Test is non-parametric and often used for ordinal data, SPSS will process scale data by converting it to ranks internally.
To visualize this process, consider the following data entry example showing the response time (in seconds) of five patients across four different medication trials:

Once your data is successfully imported or manually entered, it is often wise to perform a brief exploratory data analysis. While the Friedman Test does not require normality, checking for missing values or extreme data entry errors is a best practice. SPSS provides several descriptive tools under the “Descriptive Statistics” menu that can help you understand the spread and central tendency of your groups before you proceed to the formal hypothesis testing phase.
Step 2: Navigating the SPSS Nonparametric Menu
With your data correctly formatted, the next phase involves navigating the SPSS menu system to locate the appropriate test. The software categorizes its non-parametric procedures under a specific branch of the Analyze menu. To begin, click on Analyze in the top menu bar, which houses the majority of the software’s statistical capabilities. From there, move your cursor down to Nonparametric Tests. This will open a sub-menu containing several options for modern and legacy procedures.
While SPSS has introduced “Model Viewer” versions of these tests in recent releases, many researchers and statisticians prefer the Legacy Dialogs for their simplicity and direct output. Therefore, hover over Legacy Dialogs and select K Related Samples. It is a common mistake to select “K Independent Samples”; however, because the Friedman Test is designed for the same subjects across multiple conditions, the “Related” option is the correct statistical choice.
The following image illustrates the precise menu path required to access the Friedman Test configuration window:

Selecting K Related Samples will trigger a new dialog box titled “Tests for Several Related Samples.” This interface is where you will define which variables from your dataset will be included in the ranking process and ultimately compared against one another. This step acts as the bridge between your raw data and the mathematical execution of the test.
Step 3: Configuring the Test Variables and Options
Inside the “Tests for Several Related Samples” dialog box, you will see a list of all variables in your dataset on the left-hand side. You must select the variables representing your different conditions—in our example, the four drug response times—and move them into the Test Variables box on the right. You can do this by highlighting the variables and clicking the arrow button. It is essential that you include all groups you wish to compare simultaneously to allow the Friedman Test to calculate the appropriate Chi-Square statistic.
Below the variable selection area, you will find the “Test Type” section. Ensure that the checkbox next to Friedman is selected. While other tests like Kendall’s W or Cochran’s Q are available in this same window, they serve different statistical purposes (such as measuring inter-rater agreement or analyzing binary data). For comparing means or medians of continuous/ordinal data across three or more related groups, the Friedman Test remains the standard choice.
Refer to the image below for the proper configuration of the dialog box:

Before clicking OK, you may choose to click on the Statistics button to request descriptive statistics or quartiles. These can be helpful when writing your final report, as they provide the context needed to describe the direction of the differences found. Once your settings are verified, clicking OK will instruct SPSS to run the calculations and generate the output window containing your results.
Step 4: Interpreting the Statistical Output
The output generated by SPSS for a Friedman Test is typically concise, focusing on two primary tables: the “Ranks” table and the “Test Statistics” table. The Ranks table provides the mean rank for each condition. In a study on reaction times, a lower mean rank would indicate a faster reaction time across the sample. These ranks are the fundamental data points used by the test to determine if the differences observed between the groups are greater than what would be expected by chance alone.
The “Test Statistics” table is where you will find the definitive answer to your research question. Key values include the Chi-Square (represented as χ²), the degrees of freedom (df), and the Asymp. Sig. (which is the p-value). The degrees of freedom for this test are always calculated as the number of groups minus one (k – 1). In our example with four drugs, the df is 3.
The results of the example analysis are shown below:

When interpreting these results, the p-value is the most critical metric. In the provided example, the Asymp. Sig. is .004. By comparing this to a standard alpha level (typically 0.05), we can determine the significance of the findings. Because .004 is less than .05, we reject the null hypothesis. This leads to the conclusion that there is a statistically significant difference in response times depending on the type of drug administered to the patients.
Step 5: Post-Hoc Analysis and Reporting Results
After finding a significant result with the Friedman Test, the logical next step is to conduct post-hoc analysis. Because the omnibus test only indicates that a difference exists somewhere among the groups, you need to perform pairwise comparisons to see exactly which drugs differ from each other. In a non-parametric context, this is usually done using the Wilcoxon signed-rank test on each possible pair of groups. However, you must apply a Bonferroni correction to the alpha level to account for the increased risk of a Type I error during multiple comparisons.
When reporting your results in a formal academic or professional setting, it is important to include the test statistic, the degrees of freedom, and the exact p-value. A comprehensive report should also describe the context of the study and the direction of the findings based on the mean ranks or medians. This provides the reader with a clear understanding of not just the statistical significance, but also the practical implications of the research.
Here is a professional example of how to report the findings from the drug response time study:
A Friedman Test was conducted on five individuals to examine the effect that four different drugs had on response time. Each individual used each drug once. Results showed that the type of drug used led to statistically significant differences in response time (χ² = 13.56, df = 3, p = 0.004).
By following this structured approach—from data entry and menu navigation to rigorous interpretation and reporting—you ensure that your Friedman Test analysis in SPSS is both accurate and scientifically sound. This method empowers researchers to draw meaningful conclusions from complex, related-group data even when traditional parametric assumptions are not met.
Cite this article
stats writer (2026). How to Perform a Friedman Test in SPSS: A Step-by-Step Guide. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-do-you-perform-the-friedman-test-in-spss/
stats writer. "How to Perform a Friedman Test in SPSS: A Step-by-Step Guide." PSYCHOLOGICAL SCALES, 15 Mar. 2026, https://scales.arabpsychology.com/stats/how-do-you-perform-the-friedman-test-in-spss/.
stats writer. "How to Perform a Friedman Test in SPSS: A Step-by-Step Guide." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-do-you-perform-the-friedman-test-in-spss/.
stats writer (2026) 'How to Perform a Friedman Test in SPSS: A Step-by-Step Guide', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-do-you-perform-the-friedman-test-in-spss/.
[1] stats writer, "How to Perform a Friedman Test in SPSS: A Step-by-Step Guide," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Perform a Friedman Test in SPSS: A Step-by-Step Guide. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.