Table of Contents
Understanding the Fundamentals of Root Mean Square Error (RMSE)
The Root Mean Square Error (RMSE) serves as a cornerstone metric in the fields of statistics and data science. It is primarily utilized to quantify the differences between values predicted by a model and the values actually observed from the phenomenon being modeled. By calculating the square root of the average of squared differences, RMSE provides a high-level overview of the accuracy of a predictive model, effectively acting as a measure of the standard deviation of the residuals or prediction errors.
In the context of regression analysis, RMSE is indispensable for assessing how well a mathematical model fits a specific dataset. When a researcher or analyst develops a model to forecast a response variable based on one or more predictor variables, the goal is to minimize the distance between the predicted points and the actual data points. RMSE aggregates these distances into a single measure of predictive power, expressed in the same units as the response variable, which makes it highly intuitive for stakeholders and analysts alike.
Furthermore, RMSE is particularly sensitive to outliers. Because the errors are squared before they are averaged, larger errors have a disproportionately large effect on the final RMSE value. This characteristic makes RMSE an excellent tool for applications where large errors are particularly undesirable, such as in financial forecasting, engineering safety margins, or meteorological predictions. Understanding this sensitivity is crucial for any professional working with Microsoft Excel to evaluate the performance of their quantitative models.
Beyond its mathematical utility, RMSE facilitates a comparative framework for model selection. When faced with multiple candidate models—such as linear versus non-linear regression analysis—the model that yields the lowest RMSE is generally considered to have the best fit, assuming it does not suffer from overfitting. This makes the ability to calculate and interpret RMSE a vital skill for anyone performing data-driven decision-making in a corporate or academic environment.
The Mathematical Foundation of the RMSE Formula
To master the calculation of RMSE within Microsoft Excel, one must first grasp the underlying mathematical structure that governs the metric. The formula for Root Mean Square Error is elegantly structured to account for the magnitude of errors while neutralizing the direction of those errors. The standard representation of the formula is as follows: RMSE = √[ Σ(Pi – Oi)^2 / n ]. This equation may appear daunting at first glance, but it can be broken down into discrete components that are easy to manage within a spreadsheet environment.
The components of the formula are defined as follows:
- Σ (Sigma): This summation symbol indicates that you must add together a series of values—in this case, the squared differences for every observation in your dataset.
- Pi (Predicted Value): This represents the forecasted or estimated value for the i-th observation, typically generated by your regression model or machine learning algorithm.
- Oi (Observed Value): This is the actual, real-world data point recorded for the i-th observation, also known as the “ground truth.”
- n (Sample Size): This refers to the total number of observations or data points within the dataset being analyzed.
The logic of squaring the differences (Pi – Oi) is fundamental to statistics. Without squaring, positive and negative errors would cancel each other out when summed, potentially leading to a misleading result of zero error for a highly inaccurate model. By squaring the residuals, all errors become positive, ensuring that every deviation contributes to the total error measure. Finally, taking the square root of the average squared error returns the metric to the original units of the data, allowing for direct comparison with the observed values.
It is also worth noting that in certain academic circles, RMSE is referred to as the Root Mean Square Deviation (RMSD). While the terminology may vary depending on the field of study, the calculation remains identical. Whether you are conducting a regression analysis in a laboratory or performing market trend analysis in a boardroom, the mathematical rigor provided by this formula remains a gold standard for error measurement.
Preparing Your Data Environment in Microsoft Excel
Before implementing any formulas, it is essential to organize your data within Microsoft Excel to ensure accuracy and ease of calculation. A well-structured spreadsheet prevents errors and allows for the seamless application of array formulas. Typically, you should arrange your data in a tabular format where each row represents a single observation and each column represents a specific variable. For RMSE, you will need at minimum two columns: one for your actual observed values and another for the values predicted by your model.
Clean data is the prerequisite for any meaningful data analysis. Ensure that there are no missing values (NaNs) or non-numeric characters within your data ranges, as functions like SUMSQ or AVERAGE may return errors or skewed results if they encounter unexpected data types. It is often helpful to use Excel Tables (Ctrl+T) to manage your data, as this allows for dynamic range referencing, which automatically updates your RMSE calculation whenever new data points are added to the list.
Furthermore, labeling your columns clearly—such as “Actual Values” in Column A and “Predicted Values” in Column B—improves the readability of your work for collaborators. In more complex scenarios, you might have multiple models producing different sets of predictions. In such cases, maintaining a consistent structure where Column A remains the constant observed data while subsequent columns (B, C, D, etc.) contain predictions from Model 1, Model 2, and Model 3, allows you to calculate and compare the Root Mean Square Error for each model side-by-side.
Once your data is cleaned and organized, you are ready to apply the Excel functions. While Microsoft Excel does not feature a dedicated “RMSE” button in its standard function library, its versatile mathematical functions can be combined to achieve the same result with high precision. This manual approach is actually preferred by many analysts because it offers greater transparency into how the error is being derived from the raw data.
Implementing RMSE Calculation Using Array Formulas
In many practical scenarios, you will have two distinct columns of data: one representing the predicted values and the other representing the observed values. To calculate the Root Mean Square Error without creating intermediate columns for residuals, you can utilize an array formula. This method is efficient because it performs the subtraction, squaring, and averaging in a single step, saving space and reducing the complexity of your spreadsheet.
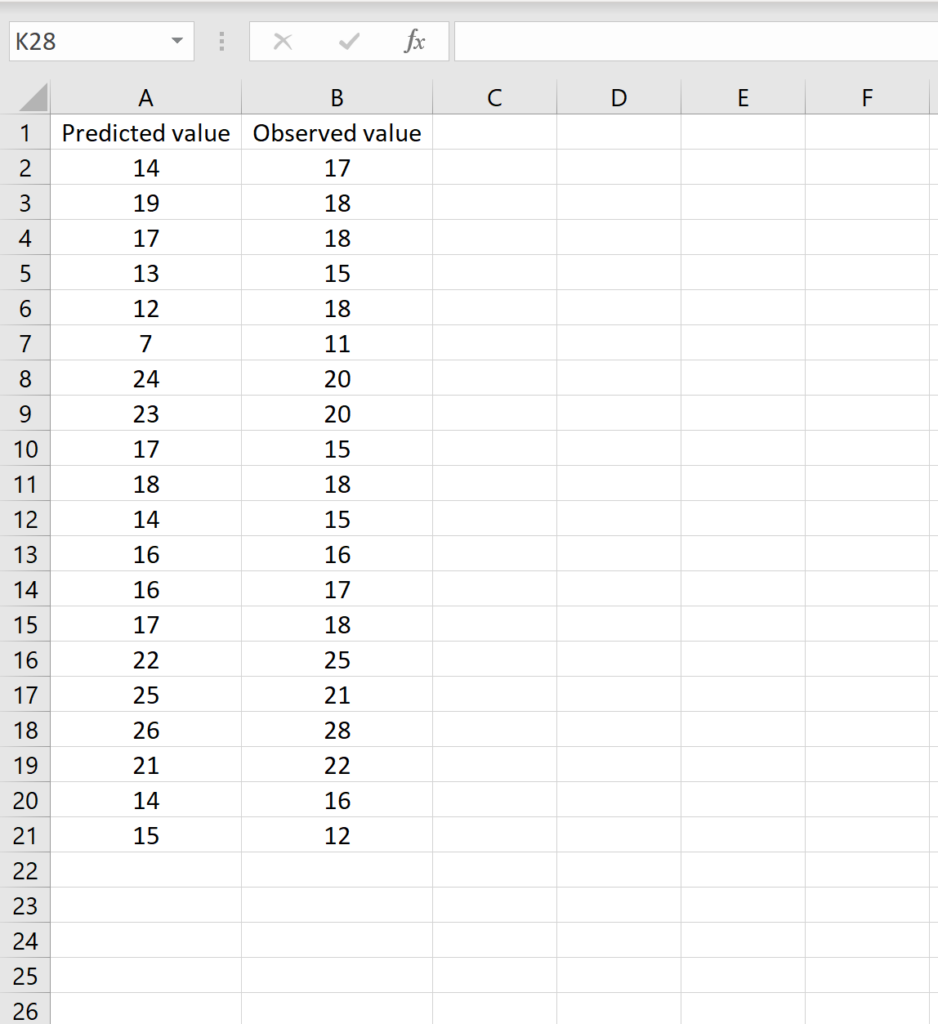
Consider the following data arrangement where Column A contains predicted values and Column B contains observed values:

To calculate the RMSE for this dataset, you can input the following formula into an empty cell: =SQRT(SUMSQ(A2:A21-B2:B21) / COUNTA(A2:A21)). If you are using an older version of Excel (pre-Office 365), you must press CTRL+SHIFT+ENTER after typing the formula. This tells Excel to treat the operation as an array calculation, allowing it to subtract each individual cell in the range before passing the results to the SUMSQ function. Modern versions of Excel with the dynamic array engine will handle this automatically with a simple ENTER.

The resulting value provides an immediate assessment of the model’s performance. In the examples provided in the images, you can see how the formula interacts with the selected ranges to produce the final error metric. This approach is highly recommended for large datasets where adding extra columns for every step of a calculation would make the workbook cumbersome and difficult to navigate. By keeping the calculation contained within a single formula, you maintain a cleaner workspace for your data analysis.

Alternative Calculation Method with Pre-Calculated Residuals
There are instances where your dataset may already include a column for the residuals (the differences between predicted and observed values). This often occurs when data is exported from specialized statistical software or when an analyst prefers to see the individual error for each data point. In this scenario, the calculation of the Root Mean Square Error becomes even more straightforward, as the subtraction step has already been completed.
Let’s examine a scenario where Column A holds the predicted values, Column B holds the observed values, and Column D contains the calculated difference (Pi – Oi):

In this case, you only need to reference the column containing the differences. The formula simplifies to: =SQRT(SUMSQ(D2:D21) / COUNTA(D2:D21)). By focusing on the pre-calculated differences in Column D, the SUMSQ function squares each value and sums them up, which is then divided by the count of observations to find the mean square error. Finally, the square root is applied to determine the RMSE.

As demonstrated in the following image, the result—2.6646—is identical to the result obtained using the array formula method. This consistency confirms that both methods are mathematically equivalent and can be used interchangeably depending on how your data is structured. Choosing this method is advantageous if you need to perform additional diagnostic checks on the residuals, such as checking for homoscedasticity or identifying specific outliers that are skewing your model’s accuracy.

Breaking Down the Excel Functions: SQRT, SUMSQ, and COUNTA
To truly understand the RMSE formula in Microsoft Excel, it is beneficial to examine the three primary functions that make it work: SQRT, SUMSQ, and COUNTA. Each of these functions plays a specific role in replicating the mathematical steps of the Root Mean Square Error equation. Mastering these individual components allows you to troubleshoot formulas and adapt them to more complex data structures or specific analytical requirements.
The SUMSQ() function is perhaps the most critical part of the operation. It takes a range of numbers, squares each number, and then returns the sum of those squares. This effectively handles the “(Pi – Oi)^2” and “Σ” parts of the RMSE formula simultaneously. By using SUMSQ, you avoid the need for a helper column filled with squared values, which keeps your spreadsheet efficient. It is a highly optimized function designed to handle large arrays of data quickly, making it ideal for statistics tasks.
Next, the COUNTA() function is used to determine the sample size (n). Unlike the standard COUNT function, which only counts cells containing numbers, COUNTA counts all cells in a range that are not empty. This is useful if your data includes labels or if you want to ensure that every row in your dataset is being accounted for. In the RMSE formula, dividing the sum of squares by the result of COUNTA provides the “Mean Square Error” (MSE), which represents the average squared variance of the predictions.
Finally, the SQRT() function is applied to the entire result. As the name suggests, it calculates the square root of a given number. This final step is essential because it converts the “Mean Square Error” back into the original units of the data. Without this step, the error metric would be in “squared units,” which are often difficult to interpret in a real-world context. Together, these three functions transform Microsoft Excel into a powerful engine for evaluating model precision.
Practical Interpretation and Evaluation of RMSE Results
Calculating the Root Mean Square Error is only the first half of the task; the second half is interpreting what that number means for your specific project. Because RMSE is scale-dependent, there is no universal “good” RMSE value. A value of 10 might be exceptionally low in a model predicting national GDP, but it would be unacceptably high in a model predicting a person’s body temperature. Therefore, RMSE must always be interpreted relative to the range and mean of the observed values in your dataset.
Generally, a smaller RMSE indicates a better fit. If the RMSE is 0, it means the model’s predictions are perfect—every predicted value matches the observed value exactly. As the RMSE increases, the model’s accuracy decreases. When comparing two different models—for example, a linear regression and a decision tree—the model with the lower RMSE is typically preferred because it produces smaller errors on average. This makes RMSE a vital tool for model selection and hyperparameter tuning in machine learning.
However, analysts must be cautious of overfitting. A model might achieve an incredibly low RMSE on its training data by “memorizing” the noise rather than learning the underlying pattern. To truly evaluate a model’s performance, it is standard practice to calculate the RMSE on a separate “test” or “validation” dataset that the model has never seen before. If the RMSE on the test set is significantly higher than on the training set, the model is likely overfit and will perform poorly in real-world applications.
Another aspect of interpretation is comparing the RMSE to the Mean Absolute Error (MAE). While RMSE squares the errors, MAE simply takes the average of the absolute differences. If the RMSE is significantly higher than the MAE, it indicates that there are large outliers in the dataset that are heavily penalizing the model. This insight can guide you to investigate those specific data points to see if they are measurement errors or legitimate extreme cases that the model needs to better account for.
Comparing RMSE with Other Error Metrics in Data Analysis
While Root Mean Square Error is a dominant metric, it is often used alongside other measures of error to provide a more comprehensive view of model performance. The most common alternative is the Mean Absolute Error (MAE). Unlike RMSE, which squares the errors, MAE treats all errors linearly. This means that MAE is less sensitive to outliers. In data analysis, using both metrics together can reveal whether a model’s total error is driven by many small inaccuracies or a few massive failures.
Another related metric is the Coefficient of Determination, commonly known as R-squared. While RMSE tells you the absolute error in the units of the response variable, R-squared provides a relative measure of how much of the variance in the response variable is explained by the model. R-squared ranges from 0 to 1, providing a percentage-based view of fit. High R-squared values usually correlate with low RMSE values, but they provide different perspectives on the regression analysis results.
In machine learning, analysts might also look at the Mean Absolute Percentage Error (MAPE). This metric expresses the error as a percentage of the observed values, which can be particularly useful when dealing with datasets where the magnitude of the values varies significantly. However, MAPE has limitations, such as being undefined when an observed value is zero. Because of its mathematical stability and relationship to the normal distribution, RMSE remains the preferred choice for most Gaussian-based statistical modeling.
Choosing between these metrics depends on the specific goals of your analysis. If you are in a field where large errors are catastrophic—such as structural engineering—RMSE is the superior choice because of its heavy penalty on large residuals. If you want a more “typical” error that isn’t skewed by a few extreme data points, MAE might be more appropriate. In professional statistics, it is best practice to report multiple metrics to give a full picture of the model’s reliability and error profile.
Advanced Tips for Model Optimization and Error Reduction
Once you have established a baseline Root Mean Square Error using Microsoft Excel, the next logical step is to explore ways to reduce this error and optimize your model. One of the most effective ways to lower RMSE is through feature engineering—the process of selecting, modifying, or creating new predictor variables that have a stronger correlation with the response variable. Often, adding an interaction term or a polynomial transformation can help the model capture complex patterns that a simple linear model might miss.
Another strategy involves data cleaning and outlier management. Since RMSE is highly sensitive to extreme values, a single incorrect data point can significantly inflate your error metric. By using Excel’s filtering and visualization tools (such as scatter plots), you can identify observations that lie far from the regression line. If these outliers are the result of data entry errors or equipment malfunctions, removing them will lead to a more accurate and representative RMSE.
Furthermore, consider the impact of multicollinearity, which occurs when predictor variables are highly correlated with each other. This can make the model unstable and increase the error. Using Excel’s Correlation matrix tool can help you identify redundant variables. By streamlining your model to include only the most impactful and independent variables, you can often achieve a lower RMSE on unseen data, improving the generalizability of your findings.
Finally, remember that Microsoft Excel is a gateway to more advanced statistical techniques. If you find that your RMSE remains high despite your best efforts, it may be time to move beyond simple regression and explore more complex algorithms like random forests or gradient boosting, which can be implemented via Excel Add-ins or by exporting your data to Python or R. Regardless of the tool you use, the fundamental principles of RMSE calculation and interpretation will remain the same throughout your career in data analysis.
Cite this article
stats writer (2026). How to Calculate RMSE in Excel: A Step-by-Step Guide. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-can-i-calculate-the-root-mean-square-error-rmse-in-excel/
stats writer. "How to Calculate RMSE in Excel: A Step-by-Step Guide." PSYCHOLOGICAL SCALES, 6 Mar. 2026, https://scales.arabpsychology.com/stats/how-can-i-calculate-the-root-mean-square-error-rmse-in-excel/.
stats writer. "How to Calculate RMSE in Excel: A Step-by-Step Guide." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-can-i-calculate-the-root-mean-square-error-rmse-in-excel/.
stats writer (2026) 'How to Calculate RMSE in Excel: A Step-by-Step Guide', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-can-i-calculate-the-root-mean-square-error-rmse-in-excel/.
[1] stats writer, "How to Calculate RMSE in Excel: A Step-by-Step Guide," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Calculate RMSE in Excel: A Step-by-Step Guide. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.