Table of Contents
Understanding the Fundamentals of Nonresponse Bias in Research
In the rigorous field of statistics and survey methodology, nonresponse bias represents one of the most significant challenges to data integrity. This phenomenon occurs when there is a systematic difference between the individuals who respond to a survey and those who do not. It is not merely a matter of having a smaller sample size; rather, it is a form of sampling bias where the non-participants possess unique characteristics that are relevant to the study’s objectives. When these voices are missing from the final dataset, the resulting data analysis often leads to skewed conclusions that fail to reflect the reality of the broader population.
The core issue of nonresponse bias lies in the distortion of the research results. For instance, if a study aims to measure the average income of a neighborhood but only high-income earners have the leisure time to complete the survey, the results will naturally overestimate the area’s wealth. This distortion is particularly problematic because it is often “invisible.” Unlike other types of errors that can be quantified through mathematical formulas, nonresponse bias requires researchers to make educated assumptions about the people they failed to reach, making it a complex hurdle in the quest for empirical truth.
To ensure the validity and generalizability of findings, it is essential for researchers to recognize that a high response rate does not always guarantee the absence of bias. Conversely, a low response rate does not automatically mean the results are biased, provided that the non-respondents are missing at random. However, in most practical scenarios, non-participation is rarely random. It is usually driven by specific demographic factors, personal interests, or logistical barriers that must be identified and mitigated to maintain the scientific rigor of the project.
Common Catalysts for Participant Non-Response
Several factors contribute to the emergence of nonresponse bias, ranging from the technical design of the instrument to the psychological state of the potential respondent. One of the primary drivers is poor survey design. If a questionnaire is excessively long, confusingly worded, or lacks any form of incentive, individuals are much more likely to abandon the process halfway through or refuse to start altogether. This “respondent fatigue” often filters out busy professionals or individuals with limited patience, leaving a sample heavily weighted toward those with significant free time or a specific grievance they wish to air.
Another critical factor is the interest level or self-selection of the participants. People who feel strongly about a particular topic—whether positively or negatively—are significantly more likely to participate in a survey regarding that topic. For example, a survey regarding a new community rock climbing center will naturally attract enthusiasts of the sport. Those who have no interest in climbing will likely ignore the invitation, leading to a sample that suggests the community is far more enthusiastic about the project than it actually is. This creates a feedback loop where the data merely confirms the biases of the most vocal subgroups.
Technological and logistical barriers also play a significant role in modern research. If a survey is distributed exclusively through a high-end mobile app, it immediately excludes segments of the population who do not own smartphones or are not tech-savvy, such as the elderly or economically disadvantaged groups. Similarly, research requiring in-person attendance can be biased against individuals with demanding work schedules or transportation limitations. In these cases, the non-respondents are not absent by choice but by circumstance, yet their exclusion still results in a skewed and unrepresentative dataset.
The Erosion of Population Representativeness
The fundamental goal of sampling is to create a “miniature version” of a larger population. When nonresponse bias is present, this link between the sample and the population is severed. In an ideal representative sample, every subgroup is present in the same proportions as they exist in the real world. However, when certain groups systematically fail to respond, the sample becomes a distorted mirror. This makes it impossible to accurately extrapolate the findings to the general public, as the “average” respondent in the survey is no longer comparable to the “average” person in the population.
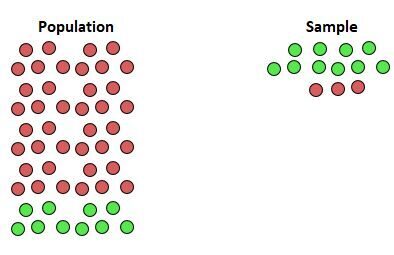
Consider a municipality considering a major infrastructure project. If they rely on a survey that primarily reached younger, tech-enabled residents, the resulting data might show overwhelming support for digital-first initiatives. If the city officials assume this sample represents the entire city, they may proceed with plans that alienate the older demographic who did not participate in the survey. The visual below illustrates this disparity: suppose the green circles represent people who are interested in using a new facility while the red circles represent those who are not.

As the illustration suggests, if the researchers only successfully collect data from the “green” individuals because they were more motivated to respond, the resulting conclusion—that 100% of the population supports the initiative—is a dangerous falsehood. The statistical inference drawn from such a sample is fundamentally flawed, leading to a waste of resources and a failure to meet the needs of the actual community. This highlights why ensuring representativeness is the cornerstone of ethical and effective research.
Statistical Consequences: Variance and Parameter Estimation
Beyond the issue of representativeness, nonresponse bias has technical implications for parameter estimation and variance. In statistics, the standard deviation and variance describe how spread out the data points are. When a large portion of a intended sample fails to respond, the final sample size is often much smaller than originally planned. A smaller sample size generally leads to higher variance, which decreases the precision of the study’s estimates. This makes it significantly harder to identify a statistical significance, as the margin of error expands.
Furthermore, if the non-respondents are concentrated in a specific part of the distribution—for example, if all the “extreme” opinions are missing—the population mean calculated from the sample will be biased. This is not a random error that cancels out with more data; it is a systematic error that shifts the entire result in one direction. Researchers might find themselves reporting a “significant” finding that is actually just an artifact of who chose to answer the phone or open the email. This can be devastating in fields like clinical trials or economic forecasting, where precision is paramount.
To combat these statistical hurdles, advanced researchers often use weighting techniques or sensitivity analyses to estimate how much the results would change if the non-respondents had participated. By comparing the known demographics of the non-respondents (if available) to the respondents, they can attempt to “level the playing field.” However, these are corrective measures and are never as reliable as obtaining a high-quality, unbiased response from the start. The mathematical complexity added by nonresponse bias often obscures the primary research goals and introduces new layers of potential error.
Case Study: Survey Fatigue and Professional Expertise
To understand the practical impact of nonresponse bias, we can look at a scenario involving software engineering. Imagine a research team wanting to evaluate a new, complex development tool. They design a comprehensive survey that takes over an hour to complete, hoping to gather deep insights. However, the most experienced and senior computer scientists—those whose time is most valuable—are the least likely to spend an hour on an unpaid survey. Consequently, the majority of the completed surveys come from entry-level developers or students who have more flexible schedules.
The results of the survey might show that the software is “highly intuitive” and “perfectly designed.” Because the junior developers lack the experience to see the structural flaws or scalability issues of the tool, their feedback is overwhelmingly positive. If the company then launches the product based on this data, they will likely be blindsided when the broader professional community rejects the tool for its technical shortcomings. The “non-respondents” in this case were the very experts whose opinions mattered most, but their opportunity cost was too high to participate.
This example demonstrates how nonresponse bias can create a “false positive” in market research. The data collected was “clean” and “valid” in a vacuum, but because it systematically excluded the most critical demographic, it led to a disastrous business decision. It serves as a reminder that the quality of data is often dictated by the accessibility of the survey to the most relevant stakeholders, rather than the sheer volume of responses collected from less relevant groups.
The Influence of Social Desirability and Privacy Concerns
Another profound source of nonresponse bias is the sensitive nature of certain topics. When a survey asks questions about stigmatized behaviors, such as substance abuse, illegal activities, or even controversial political views, social desirability bias often triggers non-participation. Individuals who engage in these behaviors may choose not to respond at all to avoid judgment or potential repercussions, even if the survey claims to be confidential.
Consider a college conducting a study on alcohol consumption patterns. If the researchers set up a public booth where students are asked to fill out a non-anonymous questionnaire, the students who drink heavily are likely to walk past the booth to avoid self-incrimination or embarrassment. The resulting data will show a student body that is remarkably sober and responsible. In this instance, the non-respondents are specifically those who represent the “high-end” of the metric being measured, leading to an underestimation of the actual problem on campus.
To mitigate this, researchers must prioritize anonymity and use data collection methods that feel safe for the participant. Digital surveys that can be completed in private, or “randomized response” techniques, can help encourage participation from those who would otherwise be non-respondents. Without these safeguards, the data collected on sensitive social issues will almost always be biased toward the most “socially acceptable” behaviors, rendering the research ineffective for public health or policy interventions.
Lessons from History: The 1936 Presidential Election Debacle
Perhaps the most famous historical example of nonresponse bias occurred during the 1936 United States presidential election. The Literary Digest, a popular magazine at the time, conducted a massive poll by sending out 10 million questionnaires to predict the winner between Franklin D. Roosevelt and Alf Landon. Based on 2.3 million responses, the magazine confidently predicted that Landon would win in a landslide. In reality, Roosevelt won one of the most decisive victories in American history, carrying 46 of the 48 states.
The failure was twofold, but nonresponse bias was a primary culprit. First, the mailing list was drawn from telephone directories and automobile registrations, which in 1936 leaned heavily toward wealthier citizens who were more likely to be Republicans. Second, and more importantly, the 7.7 million people who did not respond were fundamentally different from the 2.3 million who did. Those who were struggling during the Great Depression and supported Roosevelt’s New Deal policies were less likely to participate in a magazine poll, while Landon’s supporters were highly motivated to voice their opposition to the incumbent.
This catastrophic error led to the eventual demise of the Literary Digest and served as a foundational lesson for the modern opinion polling industry. It proved that a massive sample size (2.3 million is enormous even by today’s standards) cannot save a study from the effects of nonresponse bias. If the respondents are not a representative slice of the electorate, the volume of data only serves to provide a false sense of security in an incorrect conclusion. It highlighted the need for probability sampling and active follow-up with non-respondents.
Proactive Strategies for Reducing Bias in Survey Design
While it is nearly impossible to eliminate nonresponse bias entirely, several strategic steps can be taken to minimize its impact. The first and most effective method is to optimize survey length and complexity. Researchers should ruthlessly edit their questions to ensure that the survey is as brief as possible. By respecting the participant’s time, the likelihood of completion increases across all demographic groups, not just those with excessive free time. A streamlined, mobile-friendly design is no longer optional in an era of short attention spans.
Implementing incentive programs is another proven method to boost response rates. Whether it is a direct monetary payment, a gift card, or entry into a lottery, incentives provide a tangible reason for “neutral” individuals to participate. This helps pull in the people who are not inherently interested in the topic, thereby balancing out the sample that would otherwise be dominated by enthusiasts or critics. Additionally, providing clear assurances of privacy and confidentiality can encourage responses from those concerned about the sensitive nature of the questions.
Finally, researchers should utilize multi-channel distribution. Instead of relying solely on an app or landline phone calls, a mixed-mode approach—combining mail, email, phone, and even in-person interviews—ensures a broader reach. Following up with non-respondents through “reminders” can also significantly increase participation. By being proactive and thoughtful in the distribution phase, researchers can capture a much more accurate cross-section of the population, ensuring that their final report is a true reflection of the community’s voice.
Conclusion: Ensuring the Validity of Empirical Findings
In conclusion, nonresponse bias is a pervasive and dangerous threat to the scientific method. It acts as a silent distorter of truth, capable of rendering even the largest datasets useless if not properly managed. By understanding the causes—ranging from poor design to social desirability—researchers can better prepare their studies to capture a truly representative sample. The goal of any study should not just be to collect data, but to collect data that is meaningful and reflective of the entire population under study.
As we have seen through historical failures and modern examples, the key to overcoming this bias lies in empathy for the respondent and technical rigour. Whether it is by offering incentives, ensuring anonymity, or using diverse distribution methods, the objective remains the same: to bridge the gap between those who speak and those who remain silent. Only by addressing the “missing voices” can we hope to achieve findings that are both valid and actionable in the real world.
For those interested in exploring related concepts in research methodology, it is often helpful to examine other forms of systematic error that can impact data quality. Understanding these nuances is essential for anyone involved in data-driven decision-making or academic research.
Related Articles
Cite this article
stats writer (2026). How to Identify and Avoid Nonresponse Bias in Your Research. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/what-is-nonresponse-bias-and-can-you-provide-examples-of-it/
stats writer. "How to Identify and Avoid Nonresponse Bias in Your Research." PSYCHOLOGICAL SCALES, 3 Mar. 2026, https://scales.arabpsychology.com/stats/what-is-nonresponse-bias-and-can-you-provide-examples-of-it/.
stats writer. "How to Identify and Avoid Nonresponse Bias in Your Research." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/what-is-nonresponse-bias-and-can-you-provide-examples-of-it/.
stats writer (2026) 'How to Identify and Avoid Nonresponse Bias in Your Research', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/what-is-nonresponse-bias-and-can-you-provide-examples-of-it/.
[1] stats writer, "How to Identify and Avoid Nonresponse Bias in Your Research," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, March, 2026.
stats writer. How to Identify and Avoid Nonresponse Bias in Your Research. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.