Table of Contents
Excel: Extract First Word from Cell
In the modern landscape of data management, the ability to efficiently manipulate text strings within Microsoft Excel is a fundamental skill for professionals across various industries. Whether you are managing extensive mailing lists, cleaning datasets for statistical analysis, or organizing administrative records, the requirement to isolate specific components of a string is a common challenge. Extracting the first word from a cell is particularly useful when you need to separate first names from full names, isolate product categories from descriptions, or categorize entries based on their initial identifiers. Historically, this task required complex combinations of legacy functions, but modern iterations of the software have introduced more streamlined approaches.
To achieve this goal with precision and ease, users can leverage a sophisticated formula that combines the power of logical checking with targeted text extraction. By utilizing the latest tools available in Microsoft 365 and updated versions of the spreadsheet application, you can ensure that your data processing is both accurate and resilient to errors. The following guide provides a comprehensive overview of how to implement this solution effectively in your daily workflow.
The Evolution of Text Manipulation in Digital Spreadsheets
The history of data wrangling in spreadsheet environments has seen a significant shift from manual entry to automated processing. In earlier versions of spreadsheet software, users often relied on a combination of the LEFT and FIND functions to isolate substrings. This process involved locating the position of the first space character and then instructing the application to return all characters preceding that index. While functional, this method was often cumbersome and prone to failure if the cell contained only a single word without any trailing spaces, leading to frustrating errors that required additional troubleshooting.
As software development progressed, the need for more intuitive and robust functions became apparent. This led to the introduction of dedicated text-parsing tools designed to handle complex delimiter logic natively. Modern functions allow users to define exactly what character separates their data points, making it much easier to perform lexical analysis on the fly. By understanding these underlying mechanics, you can better appreciate how modern solutions simplify the extraction process while maintaining high levels of data integrity.
Today, professional data analysis demands tools that are not only powerful but also adaptable to various data formats. The transition toward functions that prioritize readability and directness has empowered users to build more maintainable spreadsheets. Instead of nesting multiple functions within one another, contemporary formulas are designed to be self-explanatory, which is essential for collaborative environments where multiple stakeholders may interact with the same document. This evolution represents a broader trend in computing toward accessibility and efficiency.
The Primary Formula for Word Extraction
To extract the initial word from a specific cell, the following syntax is recommended for its reliability and clarity. This approach utilizes a modern function specifically designed to handle text before a designated separator, wrapped in a safeguard to manage potential exceptions in the dataset.
=IFERROR(TEXTBEFORE(A2, " "), A2)
This specific implementation is designed to target cell A2, though it can be easily adjusted to reference any other cell in your worksheet. The formula operates by identifying the first instance of a whitespace character and isolating every character that appears before it. This makes it the ideal choice for strings where words are separated by standard spaces, which is the most common format in professional documentation and data entry.
One of the standout features of this approach is its ability to handle “edge cases”—situations where the standard rules might normally result in an error. By integrating an IFERROR wrapper, the formula remains functional even when a cell contains only a single word. In such instances, since no space is present to act as a trigger, the formula intelligently defaults to returning the entire content of the cell, ensuring that no data is lost during the extraction process.
Practical Implementation: A Step-by-Step Example
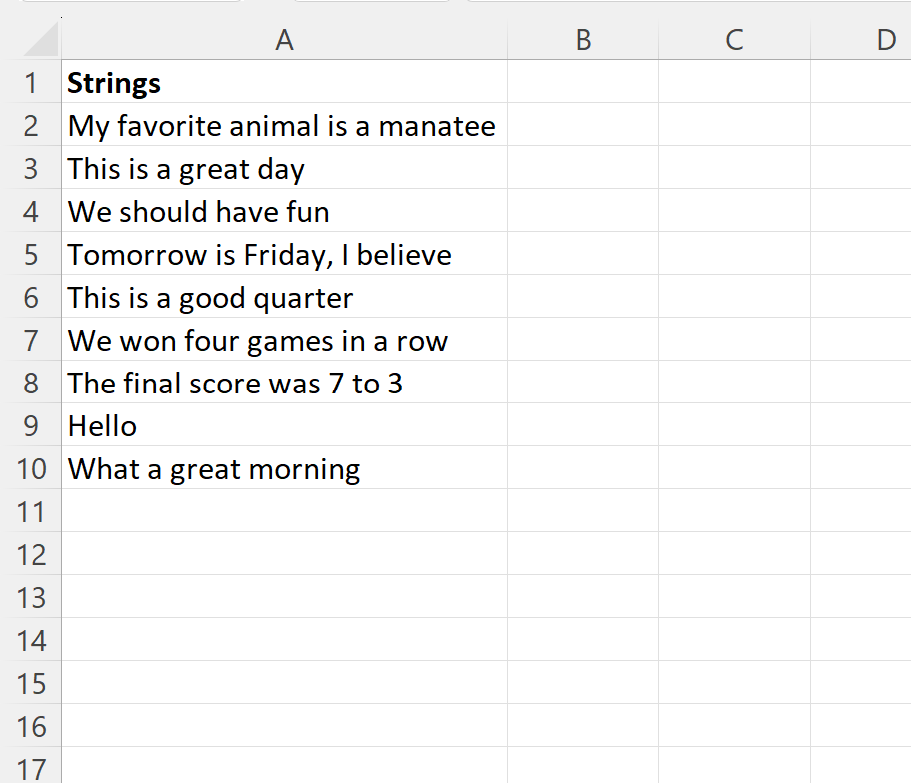
To better understand how this logic translates into a real-world scenario, let us examine a practical example involving a column of varied text strings. Imagine a spreadsheet where Column A contains full sentences or phrases, and your objective is to populate Column B with only the very first word of each entry. This is a common requirement in information retrieval tasks where the primary keyword is of the highest importance.

In the image above, we observe a series of diverse strings. To begin the extraction process, you would select the first cell in your target column—in this case, cell B2. By entering the designated formula into the formula bar, you initiate the calculation for that specific row. The software immediately processes the string in A2, scans for the first delimiter, and displays the resulting word.
=IFERROR(TEXTBEFORE(A2, " "), A2)
After successfully applying the formula to the first row, you can utilize the “fill handle” feature—a small square at the bottom-right corner of the selected cell—to drag the logic down through the rest of the column. This action applies relative referencing, meaning the formula automatically updates its target cell for each subsequent row (e.g., A3, A4, A5), allowing for a rapid and automated transformation of the entire dataset.

As demonstrated in the updated screenshot, Column B now reflects a perfectly isolated list of the first words from Column A. This transformation is clean, consistent, and requires no manual typing, which significantly reduces the risk of human error during data cleansing. Each result is a direct reflection of the logic applied, providing a reliable foundation for further analysis or reporting.
Consider the specific results of this operation to see the logic in action:
- The formula successfully isolates My from the sentence My favorite animal is a manatee.
- It accurately identifies This as the primary token in This is a great day.
- It captures We from the phrase We should have fun.
The consistency of these results across different sentence structures highlights the versatility of the TEXTBEFORE function. Regardless of the length of the sentence or the nature of the words following the first space, the formula maintains its focus on the initial segment of the string, delivering a standardized output that is easy to categorize or sort.
Deep Dive into the TEXTBEFORE Function Syntax
To fully master this technique, it is essential to understand the individual parameters that govern the behavior of the function. The TEXTBEFORE utility is part of a new suite of text manipulation tools that offer far greater control than traditional methods. By adjusting these arguments, users can customize the function to suit highly specific data patterns and organizational requirements.
The complete syntax for this function is as follows:
TEXTBEFORE(text, delimiter, [instance_num], [match_mode], [match_end], [if_not_found])
Each component of this syntax serves a distinct purpose in the extraction logic:
- text: This represents the source material or the specific cell reference (e.g., A2) that contains the string you wish to analyze.
- delimiter: This is the specific character that marks the boundary for extraction. In our example, a space (” “) is used, but this could also be a comma, a hyphen, or any other character.
- instance_num (optional): This allows you to specify which occurrence of the delimiter should trigger the extraction. By default, this is set to 1, which is perfect for isolating the very first word.
- match_mode (optional): This parameter determines whether the search for the delimiter is case-sensitive. A value of 0 is case-sensitive, while 1 is case-insensitive.
- match_end (optional): This advanced setting allows the function to treat the end of the text string as a delimiter, which can be useful in specific parsing scenarios.
- if_not_found (optional): This defines what the function should return if the specified delimiter is nowhere to be found in the text.
By dissecting the formula =IFERROR(TEXTBEFORE(A2, ” “), A2), we can see that it primarily utilizes the first two arguments to locate the first space in cell A2 and return everything before it. The beauty of this function lies in its simplicity for basic tasks, while still offering the depth required for complex string searching operations. Understanding these parameters allows you to troubleshoot issues and adapt the formula as your data needs evolve.
The Critical Role of Error Handling with IFERROR
In any algorithm designed for data processing, robustness is key. A common issue when extracting text based on a delimiter is the presence of cells that do not contain that delimiter. If you use TEXTBEFORE on a cell that contains only a single word (and therefore no spaces), the function will naturally return a #N/A error because it cannot find the specified “trigger” character. This can break downstream calculations and give the impression of a flawed spreadsheet.
This is where the error handling capabilities of the IFERROR function become indispensable. By wrapping our primary function inside IFERROR, we create a fallback mechanism. The logic essentially says: “Attempt to find the first word using the space as a guide; however, if that process fails, simply provide the original content of the cell instead.” This ensures that single-word entries are preserved rather than replaced by an unsightly error message.
Furthermore, using IFERROR contributes to cleaner data visualization and reporting. When presenting findings to stakeholders, a spreadsheet filled with error codes is unprofessional and difficult to interpret. By ensuring that every cell in your output column contains valid, readable text, you maintain a high standard of professional quality and ensure that your automated workflows remain seamless from start to finish.
Strategic Benefits for Business Intelligence
Extracting the first word from a cell is more than just a formatting trick; it is a vital part of Business Intelligence and data organization. By isolating specific tokens, analysts can perform more granular sorting and filtering. For example, if a column contains “Product – Serial Number,” extracting the first word allows for immediate grouping by product type, facilitating faster inventory checks and sales analysis.
Additionally, this technique is a cornerstone of Master Data Management. Clean data is the prerequisite for any successful migration to a new system or the implementation of a CRM. By standardizing the way text is parsed and stored, organizations can avoid the pitfalls of duplicated or inconsistent records. Automating this through formulas rather than manual editing ensures that the rules are applied consistently across thousands of rows of data.
Finally, the time savings associated with these automated formulas cannot be overstated. In a competitive business environment, the ability to transform raw data into actionable insights quickly is a significant advantage. Mastering functions like TEXTBEFORE allows you to spend less time on manual data entry and more time on high-level analysis and strategic decision-making. It is a small but powerful tool in the arsenal of any modern data professional.
Documentation and Further Learning
For those interested in exploring the full capabilities of these features, the official documentation provided by Microsoft offers deep insights into the logic and performance of text functions. Staying updated with the latest software releases ensures that you are always using the most efficient methods available for your tasks.
Note: You can find the complete documentation for the TEXTBEFORE function in the official Excel help center. This resource is invaluable for understanding the nuances of how the software handles different character sets and memory management during complex calculations.
Additional Resources for Spreadsheet Mastery
The following tutorials and guides explain how to perform other common tasks and master advanced techniques within the application:
- Exploring logical functions for conditional data formatting.
- Mastering the art of VLOOKUP and XLOOKUP for data merging.
- Advanced techniques for pivot table creation and data summarization.
- Using Power Query for complex data transformation workflows.
Cite this article
stats writer (2026). How to Extract the First Word from an Excel Cell. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-can-i-extract-the-first-word-from-a-cell-in-excel-2/
stats writer. "How to Extract the First Word from an Excel Cell." PSYCHOLOGICAL SCALES, 21 Feb. 2026, https://scales.arabpsychology.com/stats/how-can-i-extract-the-first-word-from-a-cell-in-excel-2/.
stats writer. "How to Extract the First Word from an Excel Cell." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-can-i-extract-the-first-word-from-a-cell-in-excel-2/.
stats writer (2026) 'How to Extract the First Word from an Excel Cell', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-can-i-extract-the-first-word-from-a-cell-in-excel-2/.
[1] stats writer, "How to Extract the First Word from an Excel Cell," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, February, 2026.
stats writer. How to Extract the First Word from an Excel Cell. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.