Table of Contents
The Strategic Role of Data Identification in Modern Spreadsheets
In the contemporary landscape of digital administration, Google Sheets serves as a cornerstone for professionals seeking to manage complex information through a versatile spreadsheet interface. One of the most critical tasks in data analysis is the ability to distinguish between the initial entry of a data point and its subsequent repetitions. Identifying the first occurrence of a specific value is not merely a matter of organization; it is a fundamental step in ensuring the integrity of a database and streamlining workflows. By isolating the first instance, users can perform accurate counts of unique entities, apply specific formatting to new entries, or trigger automated workflows based on the introduction of novel information.
The manual labor involved in scouring thousands of rows to find a specific entry is not only inefficient but also prone to human error, which can compromise the validity of an entire project. Utilizing built-in functions to automate this search allows for a more rigorous and scientific approach to data management. Whether you are managing inventory, tracking attendance, or analyzing financial transactions, the ability to pinpoint the exact moment a value first appears provides a chronological anchor for your analysis. This process transforms raw data into structured, actionable intelligence by highlighting the origin point of every unique record within a column.
While many users are familiar with basic search functions, mastering the logic of range-based identification offers a higher level of control over the environment. This technical proficiency enables analysts to build more dynamic models that adapt as new data is appended to the document. By implementing precise formulas, Google Sheets users can automate the detection of new categories or items, effectively turning a static list into a living dataset that signals changes in real-time. This foundational skill is essential for anyone looking to leverage the full potential of cloud-based collaborative tools.
Decoding the Expanding Range Logic in Formula Construction
To identify the first occurrence of a value, one must understand the mechanics of an expanding range within a formula. Unlike a static range that covers a fixed set of cells, an expanding range grows as it is copied down a column, allowing the COUNTIF function to evaluate only the cells from the start of the list down to the current row. This is achieved by using absolute references for the starting cell and relative references for the ending cell. This specific syntax instructs the software to look backward from the current position to the top of the document, checking how many times the value has appeared up to that point.
The logic dictates that if the count of a value within this specific expanding window is exactly one, then the current row must be the first time that value has been encountered. If the count exceeds one, the value is clearly a duplicate of an entry located in a previous row. This mathematical approach is highly reliable because it relies on the inherent order of the row structure in the spreadsheet. By anchoring the start of the search range, the user ensures that every row is evaluated in the context of all data that preceded it, providing a consistent Boolean output of TRUE or FALSE.
Furthermore, this method is superior to simple filtering because it preserves the original order of the data while adding a descriptive layer of metadata to each row. This metadata can then be used as a primary key for further sorting or as a filter for generating summary reports. Understanding how the COUNTIF function interacts with cell referencing is a vital skill for any power user, as it forms the basis for more advanced conditional logic and data validation rules. This approach ensures that your algorithm remains robust even as the dataset grows in size and complexity.
Executing the Identification Process Using Boolean Logic
To implement this functionality in your own projects, you can use a specific logical formula that evaluates the uniqueness of each entry. By placing the formula in an adjacent column, you create a dedicated indicator that flags the initial appearance of every item. The core of this operation lies in comparing the results of a count against the integer one, which results in a clear binary outcome. This method is particularly effective because it requires no complex scripting or third-party extensions, relying entirely on the native capabilities of the platform.
You can use the following formula to find the first occurrence of a value in a column in Google Sheets:
=COUNTIF($A$2:$A2,$A2)=1
This particular formula returns a value of TRUE for the first occurrence of each unique value in column A and a value of FALSE for all other values. This result is a Boolean state, which is natively understood by Google Sheets for use in other logical tests. For instance, you could nest this formula within an IF statement to return custom text or use it as the basis for a conditional formatting rule that highlights only the first instance of each name in a list.
The elegance of this solution lies in its simplicity and its ability to scale across thousands of rows without significant performance degradation. As you drag the formula down, the range `$A$2:$A2` becomes `$A$2:$A3`, then `$A$2:$A4`, and so on. This means the formula is always checking the current value against its own history within the document. It is a perfect example of how relative and absolute references can be combined to create dynamic, context-aware calculations that would be impossible with static ranges alone.
Converting Logical States to Numerical Values for Advanced Computation
In many analytical scenarios, a numerical indicator is more useful than a standard Boolean result. Numerical values like 1 and 0 can be easily summed, averaged, or used in further mathematical equations. For example, if you want to count the total number of unique items in a list, you could simply sum a column that contains a 1 for every first occurrence and a 0 for every duplicate. This transformation is easily achieved by performing a basic mathematical operation on the logical result of your formula.
If you would like to return a 1 or 0 instead, you can use the following formula:
=(COUNTIF($A$2:$A2,$A2)=1)+0
By adding zero to the TRUE or FALSE result, you force the spreadsheet to treat the data type as a number. In this context, TRUE is treated as 1 and FALSE is treated as 0. This is a common technique in computer science known as type coercion, and it is incredibly useful for creating summary tables or pivot reports that require quantitative inputs rather than logical labels. This allow the user to quickly calculate the “Unique Count” of a dataset by looking at the total sum of the indicator column.
The following example shows how to use these formulas in practice. By observing the visual representation of the data, one can see how the formula differentiates between the first time a team is mentioned and subsequent entries. This clarity is essential when dealing with high-volume data entry where duplicate values are expected but need to be categorized separately for reporting purposes. Utilizing numerical flags also simplifies the process of exporting data to other software packages, as 1s and 0s are universally recognized as indicators of presence or absence.
Analyzing Sports Metrics Through Case-Specific Formula Application
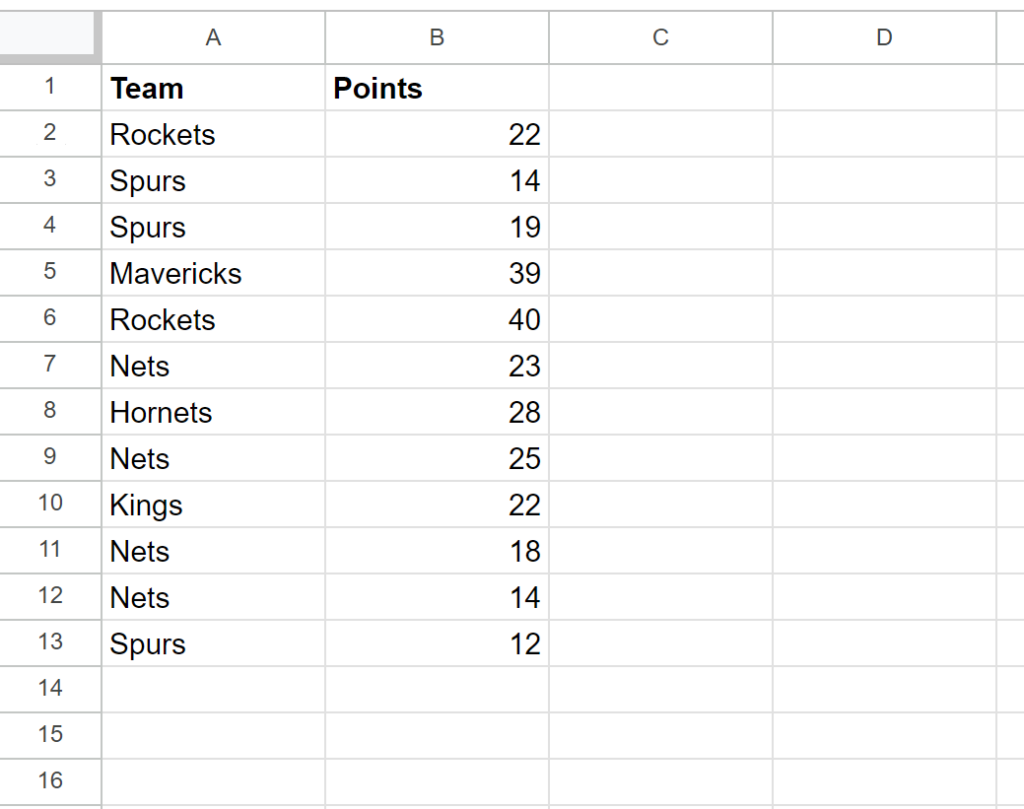
Suppose we have the following dataset that contains information about points scored by basketball players on various teams. In this scenario, we are interested in identifying the first time a specific team appears in the list, perhaps to credit the team’s first scoring event or to organize the data by team introduction. This type of analysis is common in sports statistics where chronological order and unique entity tracking are paramount for accurate record-keeping.

We can type the following formula into cell C2 to return either TRUE or FALSE to indicate whether or not the team name in cell A2 is the first occurrence of that team name in column A. This setup allows for immediate visual feedback as soon as the data is entered. The use of a dedicated column for this logic keeps the original data intact while providing a clear diagnostic tool for the analyst to verify the structure of the information provided by the user interface.
=COUNTIF($A$2:$A2,$A2)=1
We can then click and drag this formula down to each remaining cell in column C. As the range expands, the formula continues to provide an accurate assessment of each row relative to the rows above it. This ensures that even if the list is sorted differently later, the formula will recalculate based on its new position, maintaining the logic of “first appearance” based on the current physical order of the rows in the column.

The formula returns either TRUE or FALSE to indicate whether or not the corresponding team name in column A is the first occurrence of that team name. This systematic categorization is the first step toward more complex information retrieval tasks. By having a clear Boolean flag, the user can easily filter the entire spreadsheet to show only the “TRUE” rows, effectively creating a list of unique teams without needing to use a separate command or menu option.
Ensuring Data Integrity Through Systematic Row Validation
The practical application of these formulas allows for a granular level of data validation. When you apply the logic across a dataset, you can immediately spot patterns in how data is being recorded. For example, if a team name is misspelled, it will be treated as a first occurrence because the COUNTIF function is sensitive to character-for-character matches. This makes the “First Occurrence” formula an excellent tool for identifying typos or inconsistencies in data cleansing operations.
For example:
- The value of Rockets in row 2 receives a value of TRUE since it is the first occurrence of that team name in column A.
- The value of Spurs in row 3 receives a value of TRUE since it is the first occurrence of that team name in column A.
- The value of Spurs in row 4 receives a value of FALSE since it is not the first occurrence of that team name in column A.
And so on. This logical flow continues through the entire document, providing a persistent audit trail. It is important to note that the formula is case-insensitive in Google Sheets, meaning “Spurs” and “spurs” would be treated as the same value. However, leading or trailing spaces can disrupt the match, so users should ensure their data is “trimmed” before applying these identifying formulas to guarantee the most accurate reliability in their results.
=(COUNTIF($A$2:$A2,$A2)=1)+0
You can then click and drag this formula down to each remaining cell in column C. This transition from logical text to numerical values often makes the spreadsheet look cleaner and more professional, especially when preparing reports for stakeholders who prefer numerical dashboards. The 1s and 0s act as toggles that can be used to drive other more complex formulas, such as SUMIF or AVERAGEIF, where the first occurrence serves as a weight or a filter criterion.

Now the formula returns either 1 or 0 to indicate whether or not the corresponding team name in column A is the first occurrence of that team name. This streamlined approach to big data management ensures that users can handle vast amounts of information without losing sight of the individual components that make up the whole. By identifying unique entries at the source, the analyst simplifies every subsequent step of the reporting process.
Scalability Considerations for Extensive Cloud-Based Datasets
When working with exceptionally large datasets in Google Sheets, it is important to consider the computational impact of using the COUNTIF function over thousands of rows. Because each row’s formula must look back at all previous rows, the number of calculations increases exponentially as the list grows. For most standard business applications, this is not an issue, but for sheets approaching the maximum cell limit, users might notice a slight delay in recalculation times. To mitigate this, some advanced users prefer using ARRAYFORMULA or scripts to handle the identification in a single pass.
However, for the vast majority of users, the expanding range method remains the most accessible and easiest to troubleshoot. It provides immediate visual confirmation of the logic, which is vital when sharing sheets with collaborators who may need to understand how the data is being processed. In a collaborative environment, transparency is key, and simple formulas are much easier to explain and maintain than complex custom scripts. This makes the COUNTIF method a best practice for general data management in a team setting.
Finally, always remember that the order of your data matters when using this specific technique. If you re-sort your spreadsheet, the “first occurrence” flag will move to whichever row now occupies the top position for that specific value. If you need to lock the identification to a specific point in time, you may want to copy the formula results and use “Paste Special > Values only” to freeze the indicators. This ensures that your data integrity is maintained even if the visual layout of the spreadsheet changes during the analysis phase.
Expanding Your Knowledge of Google Sheets Functions
The following tutorials explain how to perform other common tasks in Google Sheets, helping you build a comprehensive toolkit for any data-driven challenge you may face in the future:
- How to remove duplicates and keep only the first instance using the UNIQUE function.
- Using the MATCH function to find the exact row number of a specific search term.
- Applying advanced FILTER techniques to isolate specific subsets of data.
- Creating dynamic dashboards by combining multiple logical formulas.
- Understanding the differences between VLOOKUP and index-match for retrieving data.
By mastering these various functions, you will become more proficient in quantitative research and business intelligence. Each new function you learn acts as a building block, allowing you to create more sophisticated and automated systems within your spreadsheets. Whether you are a novice or an experienced analyst, continuing to explore the capabilities of Google Sheets will significantly improve your productivity and the quality of your insights.
Cite this article
stats writer (2026). How to Find the First Occurrence of a Value in Google Sheets. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-can-i-use-google-sheets-to-find-the-first-occurrence-of-a-specific-value-in-a-column/
stats writer. "How to Find the First Occurrence of a Value in Google Sheets." PSYCHOLOGICAL SCALES, 11 Feb. 2026, https://scales.arabpsychology.com/stats/how-can-i-use-google-sheets-to-find-the-first-occurrence-of-a-specific-value-in-a-column/.
stats writer. "How to Find the First Occurrence of a Value in Google Sheets." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/how-can-i-use-google-sheets-to-find-the-first-occurrence-of-a-specific-value-in-a-column/.
stats writer (2026) 'How to Find the First Occurrence of a Value in Google Sheets', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-can-i-use-google-sheets-to-find-the-first-occurrence-of-a-specific-value-in-a-column/.
[1] stats writer, "How to Find the First Occurrence of a Value in Google Sheets," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, February, 2026.
stats writer. How to Find the First Occurrence of a Value in Google Sheets. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.