
Table of Contents
Hierarchical regression in Stata is a specialized statistical technique used extensively in fields like psychology and economics to analyze the cumulative effects of multiple predictor variables on a continuous or categorical dependent variable. Unlike standard multiple regression, this procedure involves the careful construction of regression models in a sequence of steps, or blocks. The analysis starts with a base model (Step 1) and systematically adds sets of additional independent variables in subsequent steps. This structured approach allows the researcher to gain critical insight into the unique contribution of each block of predictors to the overall model fit, beyond the variables already included. Furthermore, it provides a robust opportunity to assess the overall predictive accuracy and identify potential interactions or suppressions among the variables introduced sequentially.
Theoretical Foundation: Why Use Staged Modeling?
Hierarchical regression (sometimes referred to as sequential regression) is fundamentally a method for comparing nested linear regression models. The underlying purpose is hypothesis testing: determining whether adding a new set of predictors significantly improves the explanation of variance in the outcome variable, above and beyond the existing predictors. This methodology is particularly powerful when theory dictates the order in which variables should be entered into the analysis, allowing for precise evaluation of theoretical constructs and specific hypotheses regarding predictor importance.
The core principle involves first fitting a basic linear regression model, typically containing demographic or control variables. Subsequently, a second regression model is fit, incorporating one or more additional explanatory variables (the variables of primary interest). The improvement is quantified by comparing the coefficient of determination, commonly known as the R-squared, between the two models. If the change in the R-squared (often denoted as ΔR²) in the second model is statistically significantly higher than that of the previous model, it provides strong evidence that the newly added variables offer substantial unique explanatory power.
This iterative process is repeated, fitting additional regression models by adding further blocks of explanatory variables and statistically testing whether these newer models offer a substantial improvement over the prior, simpler models. This rigorous comparison relies on the statistical test of the change in R-squared (ΔR²), which follows an F-test distribution. Understanding the significance of the change in R-squared is paramount to drawing methodologically sound conclusions about variable importance.
Prerequisites and Loading the Example Dataset in Stata
To effectively illustrate the application of hierarchical regression, we will utilize a widely available, built-in dataset in Stata known as auto. This dataset contains comprehensive information on various attributes of 74 different automobiles, making it an ideal candidate for modeling price based on physical and mechanical specifications. To load this dataset and prepare our environment, execute the following command in the Stata Command box:
sysuse auto
Once the dataset is active, it is standard practice to quickly summarize the variables and observations available. This helps confirm the data structure, variable types, and missing values before starting the demanding modeling process. Use the following command to generate a descriptive summary:
summarize

The output of this command confirms the data structure, showing details about the number of observations (74 cars) and key descriptive statistics for the 12 available variables. We can proceed knowing we have a clean dataset containing variables such as price, mpg, weight, and gear ratio, which will be central to our analysis.
Defining the Research Models for Comparison
For this demonstration, we will define three sequential linear regression models where the dependent variable is the price of the vehicle. Our primary goal is to determine if the additional predictors introduced in Model 2 and Model 3 significantly enhance the prediction of car price over their predecessors, justifying their complexity. We will systematically test the influence of mpg (miles per gallon), weight (car weight), and gear ratio.
The three structured models are formulated as follows:
Model 1 (Base Model): price = intercept + mpg
Model 2 (Adding Weight): price = intercept + mpg + weight
Model 3 (Adding Gear Ratio): price = intercept + mpg + weight + gear ratio
The hierarchical regression approach will allow us to specifically isolate and test the incremental contribution of weight (by comparing Model 2 vs. Model 1) and subsequently, the incremental contribution of gear ratio (by comparing Model 3 vs. Model 2). This ensures that we are testing the unique explanatory power of each variable block beyond what has already been accounted for.
Installing the Essential `hireg` Package
To perform hierarchical regression efficiently and correctly in Stata, we must utilize a user-contributed external package known as hireg. Unlike built-in commands like regress, hireg is specifically designed to handle the sequential comparison of nested models, automatically calculating and displaying the critical statistical information, particularly the incremental F-test for the change in R-squared (ΔR²).
Since this package is not part of the standard installation, we must first locate and install it. To begin this process, enter the following command into the Stata Command box:
findit hireg
Executing the findit command will open a separate viewer window providing links to the package’s location, typically the Statistical Software Components (SSC) archive maintained by users.

In the resulting window, look for the link that specifies click here to install the package. Click this link to initiate the automated download, compilation, and installation of the hireg package onto your system.

The installation should complete within a few seconds. Once Stata confirms the successful installation, we are prepared to execute the specialized hierarchical regression command using the defined model structure.
Executing the Hierarchical Analysis Command
The syntax of the hireg command is constructed to reflect the sequential nature of the analysis. It requires the dependent variable first, followed by the independent variables grouped in parentheses, where each group represents a step or block of variables added to the previous model.
To execute the three-step hierarchical regression defined in our structure (price predicted by mpg, then weight, then gear ratio), use the following precise command:
hireg price (mpg) (weight) (gear_ratio)
This single command instructs Stata to perform three distinct regression analyses and the necessary comparisons:
Step 1: Runs Model 1 using price as the response variable, predicted only by the variable mpg.
Step 2: Runs Model 2, adding the variable weight to the predictors from Step 1, and then statistically compares Model 2 to Model 1.
Step 3: Runs Model 3, adding the variable gear_ratio to the predictors from Step 2, and then statistically compares Model 3 to Model 2.
Interpreting Model 1 and Model 2 Results
The output generated by the hireg command systematically displays the results for each stage. We begin by analyzing the results of the base model, Model 1.
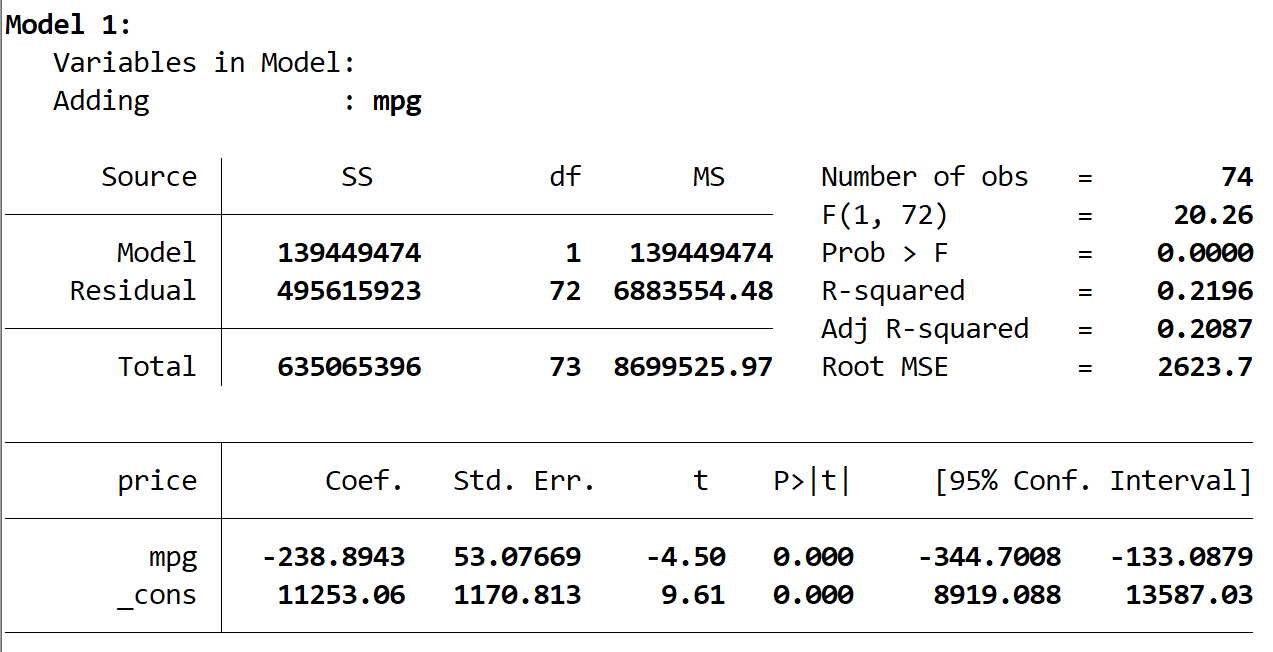
For Model 1, the overall coefficient of determination, the R-squared, is reported as 0.2196. This means that mpg alone accounts for 21.96% of the variance observed in car price. The model’s overall statistical significance is confirmed by the Prob > F value, which is 0.0000. Since this p-value is highly significant (well below α = 0.05), we confirm that Model 1 provides a predictive relationship.
Moving to Model 2, we evaluate the impact of including the variable weight alongside mpg:
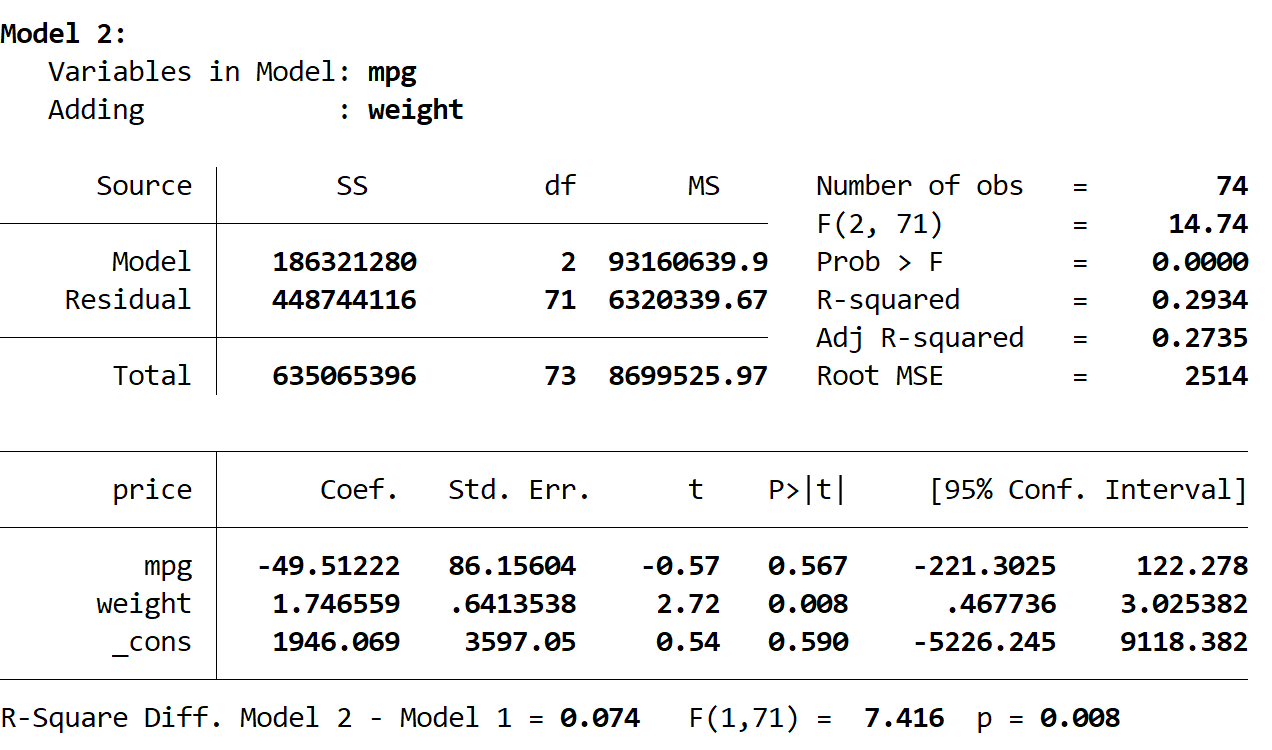
The overall R-squared for Model 2 increases to 0.2934. This numerical improvement suggests that adding weight explains an additional portion of the variance. To confirm whether this added explanatory power is statistically robust, we must examine the incremental F-test results comparing Model 2 to Model 1, which are conveniently presented at the end of the Model 2 output:
The R-squared difference (ΔR²) between the two models is 0.074, indicating a 7.4% increase in explained variance.
The corresponding F-statistic for the difference is 7.416.
The associated p-value of the F-statistic is 0.008.
Given that the p-value (0.008) is substantially less than the standard 0.05 significance level, we confidently conclude that the inclusion of weight in Model 2 resulted in a statistically significant improvement in the predictive power compared to Model 1.
Interpreting the Final Model Comparison and Conclusion
The final step involves Model 3, where gear_ratio is introduced as the last predictor, testing its unique contribution beyond mpg and weight.
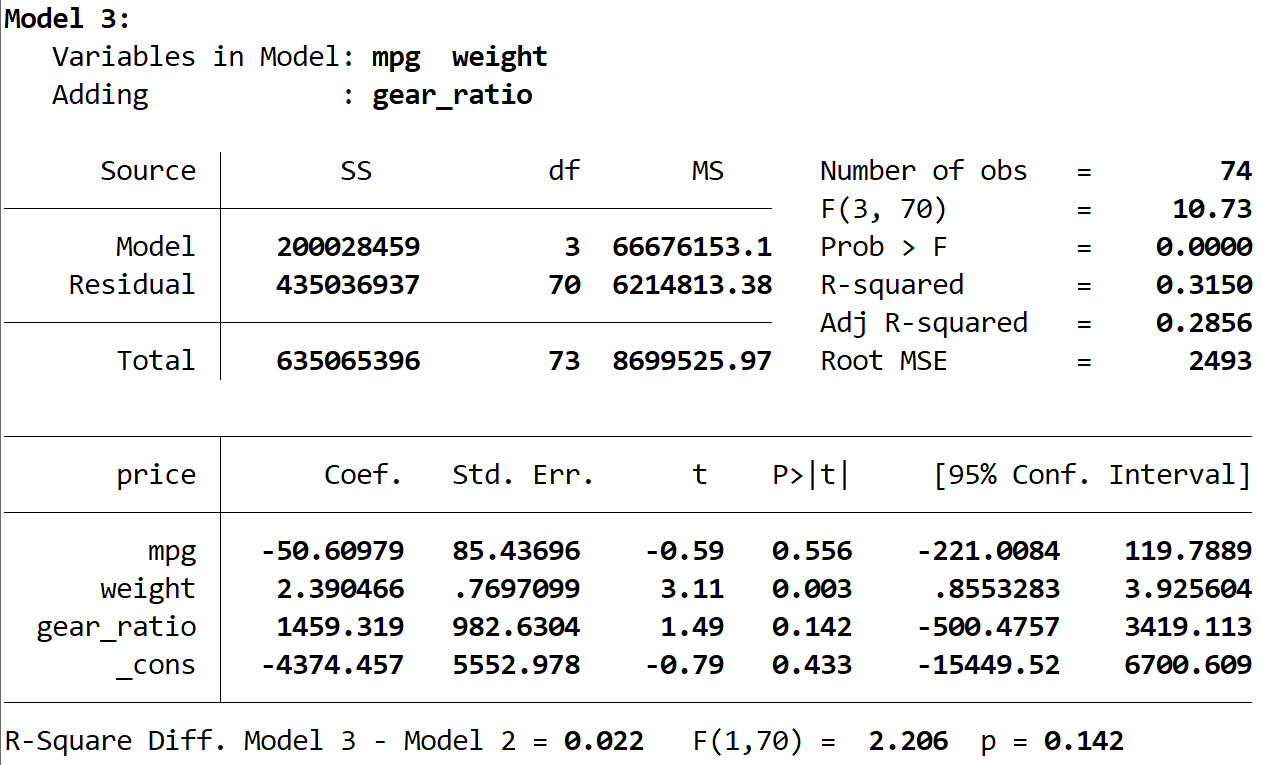
The overall R-squared for Model 3 marginally increases again to 0.3150. Although this is the highest R-squared value numerically, we must strictly rely on the incremental F-test to determine if the variable gear_ratio offers unique, statistically significant predictive utility. The results comparing Model 3 to Model 2 are:
The R-squared difference (ΔR²) between Model 3 and Model 2 is 0.022.
The calculated F-statistic for the difference is 2.206.
The corresponding p-value of the F-statistic is 0.142.
Crucially, because the resulting p-value (0.142) is greater than the alpha level of 0.05, we must conclude that there is insufficient statistical evidence to assert that Model 3 offers a significant improvement in variance explanation over the prior Model 2. The variable gear_ratio does not uniquely contribute significantly to predicting car price once both fuel efficiency and weight are already accounted for.
The Stata output concludes with a highly useful summary table that synthesizes the critical results across all sequential steps:

In summary, our Stata hierarchical regression analysis confirms that Model 2 provided a demonstrably significant statistical improvement over Model 1 (p = 0.008), validating the inclusion of car weight. Conversely, the addition of gear ratio in Model 3 did not justify the increased model complexity (p = 0.142). Therefore, Model 2 is the most parsimonious and effective model among the tested sequence for predicting car price.
Cite this article
stats writer (2025). How to Run and Interpret Hierarchical Regression in Stata. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-to-perform-hierarchical-regression-in-stata/
stats writer. "How to Run and Interpret Hierarchical Regression in Stata." PSYCHOLOGICAL SCALES, 28 Dec. 2025, https://scales.arabpsychology.com/stats/how-to-perform-hierarchical-regression-in-stata/.
stats writer. "How to Run and Interpret Hierarchical Regression in Stata." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/how-to-perform-hierarchical-regression-in-stata/.
stats writer (2025) 'How to Run and Interpret Hierarchical Regression in Stata', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-to-perform-hierarchical-regression-in-stata/.
[1] stats writer, "How to Run and Interpret Hierarchical Regression in Stata," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, December, 2025.
stats writer. How to Run and Interpret Hierarchical Regression in Stata. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.