Table of Contents
The concept of class limits is fundamental to the creation and interpretation of a frequency distribution. These limits serve as the precise upper and lower cutoff points, defining the smallest and largest data values permitted within any given class interval. By clearly delineating these ranges, we ensure robust and accurate handling of large datasets, which is crucial for subsequent data analysis and visualization. Understanding how to correctly identify and use these limits is a prerequisite for generating statistically sound summaries of raw data.
In the context of statistical organization, class limits define the range of acceptable scores or measurements for each category within the distribution. They establish the smallest and largest actual observations that can belong to a class interval, ensuring that the classification process is both exhaustive and mutually exclusive.
Every defined class in a frequency distribution table is characterized by two essential parameters:
- Lower class limit: This is unequivocally the smallest numerical data value that can be successfully categorized into that specific class interval.
- Upper class limit: This represents the largest numerical data value that is permitted to belong to the corresponding class interval.
The following detailed sections and examples illustrate the systematic methods required to accurately identify these critical numerical markers for various frequency distributions.
Understanding the Structure of Frequency Distributions
A frequency distribution is a systematic tabulation of data, showing the number of observations (the frequency) for each of several non-overlapping categories or classes. The primary goal of establishing this structure is to take raw, unorganized data and present it in a digestible format that reveals patterns, trends, and central tendencies. Creating effective classes requires careful determination of both the number of classes needed and the size or width of those classes, all of which hinge on the correct identification of the initial class limits.
When constructing a frequency distribution, the selection of class limits is particularly critical in contexts involving discrete data—where observations can only take on specific, separate values (like whole numbers, counts, or categorical ranks). For instance, if we are counting the number of children per family or the number of wins for a sports team, the data will inherently be discrete. In such cases, the limits chosen must naturally align with these countable units, ensuring there is no ambiguity about which class an observation falls into.
It is important to recognize that the limits themselves are actual data values observed in the set, or potential values that could be observed. The methodology for finding them usually involves identifying the minimum and maximum values in the entire dataset, determining the desired class width, and then systematically constructing intervals where the lower limit of the first class is often either the minimum data point or a convenient value slightly below it.
The Key Difference: Class Limits Versus Class Boundaries
While the terms are often confused by beginners, understanding the statistical difference between class limits and class boundaries is paramount for accurate data analysis, especially when preparing data for graphical displays like histograms. Class limits, as established, are the data values themselves (e.g., 10 and 19). They dictate the start and end of the observations in the table.
Conversely, class boundaries are the points used to separate classes without gaps, especially vital when dealing with continuous data or when converting discrete data for graphical representation. They are calculated by finding the midpoint between the upper limit of one class and the lower limit of the subsequent class. For example, if Class A ends at 19 and Class B starts at 20, the class boundary between them would be 19.5. This boundary ensures that the classes are mathematically contiguous, preventing any perceived gaps or overlaps in the data continuum.
This distinction is crucial because class limits are used for tabulation and listing in the frequency table, reflecting the data as collected, whereas class boundaries are primarily used for graphical purposes (like labeling axes on a histogram) and for calculations involving measures of dispersion or central tendency that require continuous intervals. While our focus here remains on finding the limits themselves, recognizing their relationship to boundaries enhances the overall comprehension of frequency distribution construction.
Finding Class Limits in Discrete Data Sets
When working with discrete data, identifying the class limits is a straightforward process based directly on the values presented in the class interval column of the frequency distribution. Since discrete classes are usually established such that they do not overlap (e.g., 1-10, 11-20, 21-30), the limits are simply the smallest and largest integers defining the interval.
To determine the lower class limit for any given class, one must simply look at the left-hand side of the interval notation. This value specifies the minimum acceptable score. Similarly, the upper class limit is the number on the right-hand side of the interval notation, which defines the maximum acceptable score for that class. It is essential to verify that the gap between the upper limit of one class and the lower limit of the next class is exactly equal to the unit of measurement used in the data set (e.g., 1 if using whole numbers).
This methodology ensures clarity and prevents classification errors. For example, if a data set represents counts of items, the class limits must be integers. If a class is defined as 50–59, the lower class limit is exactly 50, and the upper class limit is exactly 59. Any observation of 49 or less belongs to the previous class, and any observation of 60 or more belongs to the subsequent class. This adherence to discrete values is what distinguishes limits from the continuous nature of boundaries.
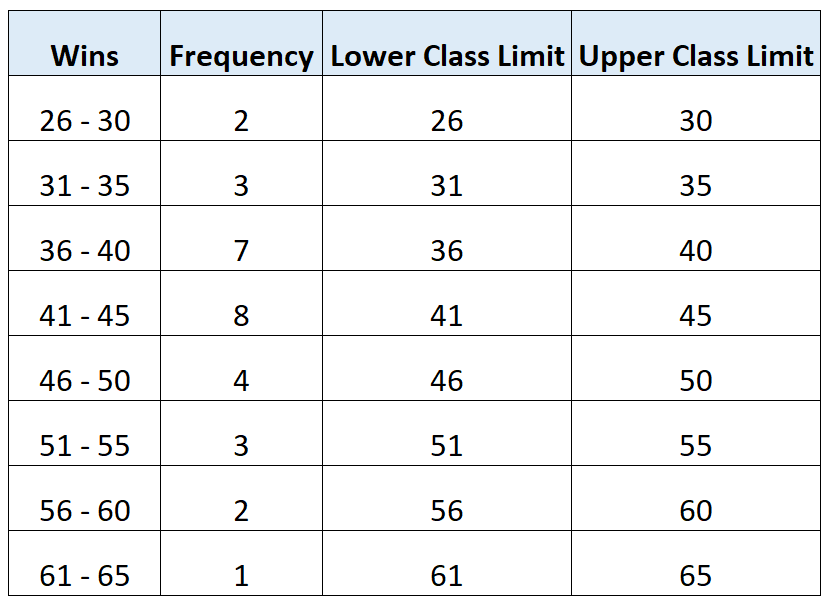
Example 1: Analyzing Discrete Data (Basketball Wins)
To illustrate the definition of class limits using a real-world example, consider a frequency distribution summarizing the total number of wins achieved by various basketball teams throughout a specific season. Since the number of wins must be an integer (a discrete value), the class limits are easily identifiable within the structure of the table itself.
Suppose we are presented with the following frequency distribution table, where the first column lists the class intervals:

For each row in this table, the task is to extract the smallest and largest values that define the class. The identification process is purely mechanical, reading the values separated by the hyphen or dash that indicates the range. For example, in the class 0-9, the lowest possible number of wins is 0, and the highest is 9.
When extracting the lower class limit, we systematically focus on the initial value of each range. This yields a column dedicated entirely to the minimum score for each class interval, confirming the smallest data point that can be allocated to that category:

Conversely, isolating the upper class limit requires focusing on the final value of each range. This second step completes the definition of the class interval by determining the maximum allowable score before the observation must be moved to the next category:
Example 2: General Application of Limit Identification
To reinforce the methodology, let us consider a second generic frequency distribution. Although the context of the data set is not specified, the principle for identifying the class limits remains identical, as the data is presented in discrete, non-overlapping intervals. This consistency demonstrates the standardized approach used in descriptive statistics regardless of the subject matter.
Consider the following distribution table:

In every class, the value on the left is the minimum score included in that category, and the value on the right is the maximum score included. This simple rule is the cornerstone of defining class limits. For example, in the first class, 70 is the smallest value, and 76 is the largest.
Applying the rule systematically, we define the lower class limit for each class by extracting the starting value of the range. These values form a column representing the lowest possible data point for each interval:

Subsequently, the upper class limit is found by extracting the ending value of the range for each class. This ensures that the entire range of data is covered by the distribution and that each class is accurately bounded by its maximum observation value:

Deriving Class Width and Midpoints from Class Limits
Once the class limits are accurately established, they become instrumental in calculating other vital statistical measures associated with the frequency distribution, most notably the class width and the class midpoint. These derived values are crucial for performing calculations and drawing graphical representations of the data.
The class width is defined as the difference between the lower limit of one class and the lower limit of the next successive class, or, alternatively, the difference between the upper limits of successive classes. Importantly, for discrete data, the class width is not simply the upper limit minus the lower limit. For example, in a class interval of 10–19, the width is 10 units (19 minus 10 plus 1). Using the limits provides a quick and robust way to verify the consistent structure of the frequency distribution.
The class midpoint, also known as the class mark, represents the center of the class interval. It is calculated by taking the average of the lower class limit and the upper class limit: (Lower Limit + Upper Limit) / 2. Midpoints are exceptionally important because they are often used to represent all the data values within that class when calculating summary statistics, such as the mean or standard deviation of grouped data. Utilizing the correct limits ensures the midpoint accurately reflects the center of the observations for that interval.
The Importance of Precision in Class Limit Determination
The meticulous process of identifying and verifying class limits is not merely an academic exercise; it is fundamental to ensuring the integrity and usability of statistical summaries. Errors in setting these limits can lead to significant misrepresentations of the data, potentially causing observations to be incorrectly grouped, thereby distorting the calculated frequencies, the shape of the distribution, and subsequent statistical inferences.
One primary reason for precision is the requirement that classes must be mutually exclusive—meaning no single data point can fall into two different classes—and exhaustive—meaning every data point must fall into one class. When limits are set incorrectly, particularly if they overlap or leave gaps (e.g., 10-20 and 20-30), the principle of mutual exclusivity is violated, making the data analysis invalid. The clear definition provided by the lower and upper class limits prevents these structural flaws in the organization of the data.
Furthermore, accurate limits are essential for comparing different data sets or distributions. If two different studies use inconsistent methods for defining their class intervals, any direct comparison of their frequencies or cumulative frequencies becomes unreliable. By adhering to standardized practices for limit identification, analysts ensure that their descriptive statistics are objective, reproducible, and comparable across different research contexts, which is the ultimate goal of effective statistical methodology.
Cite this article
stats writer (2025). How to Easily Calculate Class Limits: A Step-by-Step Guide. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-to-find-class-limits-with-examples/
stats writer. "How to Easily Calculate Class Limits: A Step-by-Step Guide." PSYCHOLOGICAL SCALES, 4 Dec. 2025, https://scales.arabpsychology.com/stats/how-to-find-class-limits-with-examples/.
stats writer. "How to Easily Calculate Class Limits: A Step-by-Step Guide." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/how-to-find-class-limits-with-examples/.
stats writer (2025) 'How to Easily Calculate Class Limits: A Step-by-Step Guide', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-to-find-class-limits-with-examples/.
[1] stats writer, "How to Easily Calculate Class Limits: A Step-by-Step Guide," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, December, 2025.
stats writer. How to Easily Calculate Class Limits: A Step-by-Step Guide. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.