Table of Contents
Analyzing the underlying structure of a dataset is a fundamental task in R programming and statistical analysis. A crucial aspect of this exploration involves visualizing the data distribution of individual column values. Plotting distributions allows analysts to quickly assess characteristics such as central tendency, variability, skewness, and the presence of outliers, providing immediate insights that summary statistics alone cannot convey.
Generating these visualizations in R is straightforward, primarily relying on the built-in plotting functions. The process necessitates defining the source data frame and specifying the column of interest, followed by invoking the appropriate command. The core strength of R’s graphics system lies in its flexibility, enabling extensive customization through various parameters—including plot type, color schemes, axis labels, and titles—ensuring that the final output is both statistically informative and aesthetically clear. Furthermore, augmenting these visual techniques with functions like summary() allows for a comprehensive understanding of the dataset’s underlying statistical properties.
Core Methods for Visualizing Column Distributions in R
When working within the R environment, analysts typically rely on two primary graphical methods for visualizing the distribution of a continuous variable. These methods—the Density Plot and the Histogram—offer complementary views of the data’s shape and frequency characteristics. Choosing between them often depends on the specific analytical goal and the desired level of visual smoothness or granularity. Both methods utilize the standard R plotting capabilities, making their implementation intuitive and highly efficient, even for large datasets.
The first widely adopted technique is the Density Plot. This method uses Kernel Density Estimation (KDE) to produce a smooth, continuous curve that estimates the probability density function of the variable. It is particularly effective for presenting the overall shape of the distribution, highlighting modes and potential multimodal characteristics without the binning artifacts sometimes associated with histograms. The smoothness of the curve facilitates easier visual comparison between different distributions or against theoretical distributions.
Conversely, the second crucial technique is the Histogram. A histogram is a classical statistical tool that partitions the range of the data into non-overlapping bins (or breaks) and counts how many observations fall into each bin. These counts are then represented by bars, where the height of the bar corresponds to the frequency or density of values within that bin. Histograms are excellent for showing the actual frequency of values and are straightforward to interpret, though their appearance can be sensitive to the number of bins chosen, a parameter that requires careful consideration.
You can use the following syntax patterns to generate these distribution plots in R:
Method 1: Plot Distribution of Values Using Density Plot
plot(density(df$my_column))
Method 2: Plot Distribution of Values Using Histogram
hist(df$my_column)
Setting Up the Sample Data Frame
To illustrate the practical application of both the density plot and the histogram, we must first establish a representative dataset. In R, data is commonly structured within a data frame, which is a list of vectors of equal length. For our demonstration, we will create a simple data frame named df containing two variables: team (a categorical variable) and points (a quantitative variable representing scores). It is the distribution of the points column that we intend to visualize.
The creation process involves using the data.frame() function, combining vectors generated by the rep() function for the categorical variable and a predefined vector for the quantitative scores. This structure mimics real-world observational data, providing a solid foundation for our subsequent graphical analysis. Defining the data structure explicitly ensures reproducibility and clarity in the examples that follow.
The following R code chunk details the generation of this sample data frame, followed by the output showing the structure of the twenty observations:
#create data frame df = data.frame(team=rep(c('A', 'B'), each=10), points=c(3, 3, 4, 5, 4, 7, 7, 7, 10, 11, 8, 7, 8, 9, 12, 12, 12, 14, 15, 17)) #view data frame df team points 1 A 3 2 A 3 3 A 4 4 A 5 5 A 4 6 A 7 7 A 7 8 A 7 9 A 10 10 A 11 11 B 8 12 B 7 13 B 8 14 B 9 15 B 12 16 B 12 17 B 12 18 B 14 19 B 15 20 B 17
Example 1: Plotting Distribution Using the Density Plot
The density plot offers an elegant method for visualizing the underlying data distribution without the visual noise introduced by binning. It is constructed by estimating the probability density function (PDF) of the continuous variable, resulting in a smooth curve where the area under the curve sums to one. This visualization is particularly useful for identifying the shape and characteristics of the distribution, making it easy to spot whether the data is unimodal, bimodal, skewed, or normally distributed.
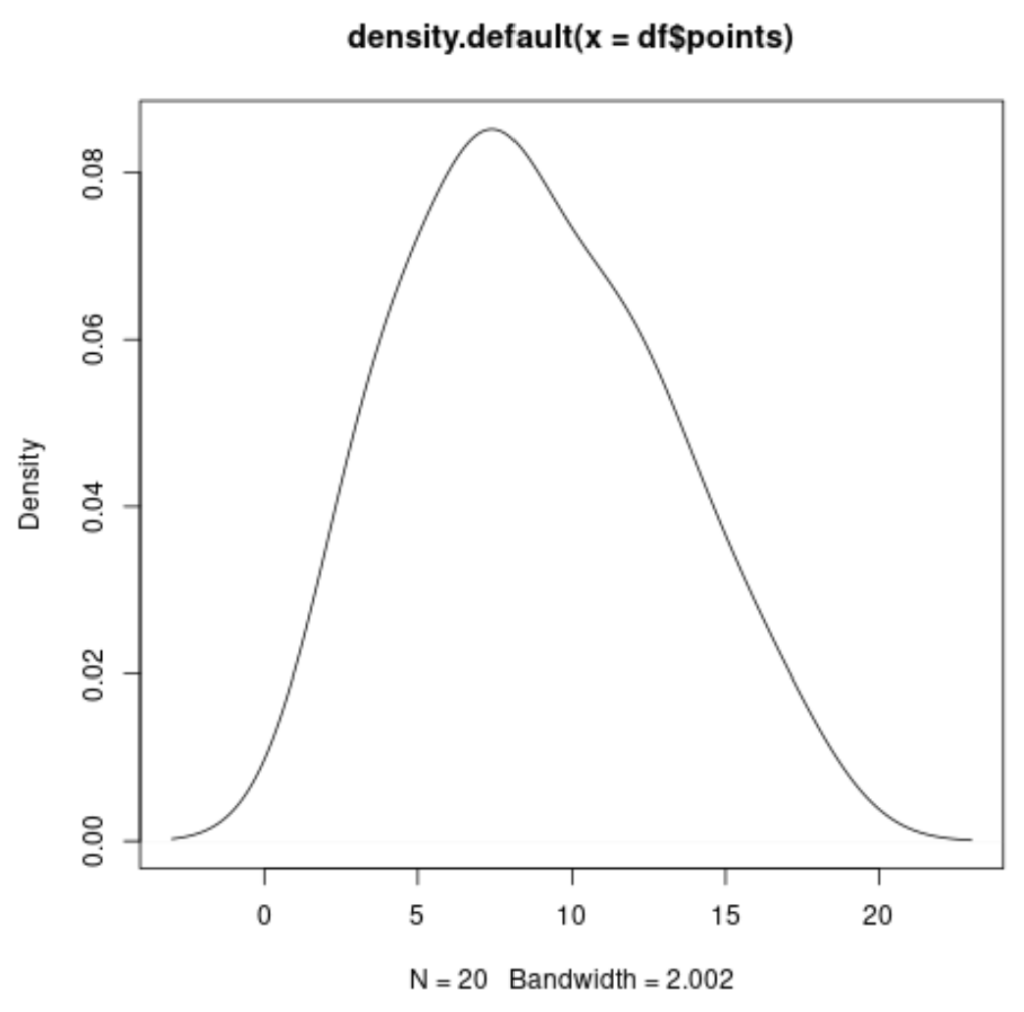
To generate a basic density plot in R, we utilize the density() function within the standard plot() command. The density() function calculates the kernel density estimate for the specified column—in our case, df$points—and the plot() function then renders this estimate graphically. The resultant visualization immediately reveals the underlying frequency structure of the scores in the points column.
The following code executes the basic density calculation and plotting for the points column:
#plot distribution of values in points column
plot(density(df$points))
This syntax produces a continuous, smooth curve that effectively summarizes the shape of the distribution for the variable. The resulting graphic shows the probability density along the vertical axis against the observed values on the horizontal axis, providing a clear visual representation of where most of the data points are concentrated.

Enhancing the Density Plot with Customization
While the default density plot provides the necessary statistical information, professional data visualization often requires customization to improve readability, aesthetic appeal, and communication effectiveness. The base R plotting system is highly flexible, allowing users to modify virtually every aspect of the plot using optional parameters within the plot() function. Key elements subject to modification include the plot title, the axis labels, and the color of the density line itself.
By specifying arguments such as main for the title, xlab for the horizontal axis label, and col for the line color, we transform the generic output into a publication-ready figure. Incorporating these arguments is essential for producing visualizations that are immediately understandable to any audience, clearly defining what the plot represents and what units the axes measure. This practice ensures that the statistical insights derived from the density plot are conveyed without ambiguity.
The following code demonstrates how to apply these modifications to the density plot, changing the line color to red and specifying descriptive titles and labels:
#plot distribution of values in points column plot(density(df$points), col='red', main='Density Plot of Points', xlab='Points')
Notice how the addition of these parameters significantly enhances the plot’s communicative value. This process underscores the importance of graphical attributes in data analysis, transitioning raw output into meaningful visual evidence. The ability to manipulate these parameters is a core skill for effective data reporting in the R environment.

Example 2: Plotting Distribution Using the Histogram
The histogram provides an alternative, equally powerful approach to visualizing the data distribution. Unlike the smooth curve of the density plot, the histogram relies on discrete bars to represent the frequency or count of data points falling within predefined intervals, known as bins. This method offers a direct view of the data’s raw frequency structure and is highly intuitive for interpreting the concentration of values across the range of the variable. Histograms are particularly valuable when the exact count of observations in specific ranges is of primary interest.
In R, the histogram is generated using the dedicated hist() function. This function automatically calculates the optimal number and placement of bins based on statistical rules (though this can be overridden) and then plots the resulting bar structure. For our example, applying hist() to the df$points column generates a visualization that clearly shows the relative frequency of the scores achieved, providing immediate clarity on which score ranges are most common within the dataset.
The following concise R command is sufficient to generate the basic histogram for our points column:
#plot distribution of values in points column using histogram
hist(df$points)
Executing this command produces a visualization where the bars depict the frequencies of values in the points column, contrasting sharply with the smooth line used by the density plot to summarize the overall shape. This initial histogram serves as a quick diagnostic tool, highlighting the general spread and modality of the data before any visual adjustments are made.

Advanced Histogram Customization: Breaks and Aesthetics
While the default histogram is statistically valid, customizing its appearance is often essential for effective data presentation. The base R hist() function accepts numerous parameters for aesthetic control, similar to the plot() function. These include specifying the main title, xlab for the horizontal axis, and col for the color of the bars. However, a uniquely important parameter for the histogram is breaks, which determines the number of bins or the specific locations of the bin boundaries.
The choice of breaks significantly impacts the visual interpretation of the distribution. Too few breaks can obscure important details (oversmoothing), while too many breaks can introduce visual noise, making the distribution appear choppy and overly sensitive to minor data variations. By explicitly setting the breaks parameter, the analyst gains precise control over the granularity of the frequency representation, ensuring the plot accurately reflects the underlying patterns without misrepresentation. In our detailed example, we specify 12 breaks to provide a finer resolution than the R default.
The following code demonstrates applying advanced formatting, including a steel blue color, a clear title, and crucially, setting the breaks argument to 12:
#plot distribution of values in points column using histogram hist(df$points, main='Histogram of Points', xlab='Points', col='steelblue', breaks=12)
The result is a highly polished and informative histogram that clearly displays the frequency distribution of the points data, optimized for detail by the increased number of breaks. Understanding and manipulating the breaks parameter is fundamental to mastering histogram generation in R, as it directly governs the visual resolution of the frequency analysis. Remember that a larger value chosen for the breaks argument will result in more bars being displayed in the histogram, offering finer detail but potentially leading to a more jagged appearance.

Note: The larger the value you choose for the breaks argument, the more bars there will be in the histogram, which can either reveal subtle features or introduce noise, depending on the dataset’s size and complexity.
Comparing Density Plots and Histograms
While both the density plot and the histogram are essential tools for visualizing data distribution, they serve slightly different purposes and offer distinct advantages. The histogram provides a direct, unmediated count of observations within specific ranges, making it excellent for understanding the raw frequency structure and identifying exact modes based on counts. It relies heavily on the definition of its bins, and its shape is discrete.
In contrast, the density plot provides a continuous, estimated probability density function. This smoothness is achieved through kernel estimation, which essentially averages nearby points to create a flowing curve. This is advantageous when the analyst wishes to generalize the shape of the distribution, compare it against theoretical distributions (like the normal curve), or present a less visually cluttered image. However, the density plot relies on bandwidth selection (the size of the kernel used for smoothing), which can influence the final shape.
For a comprehensive analysis, it is often beneficial to overlay a density curve onto a histogram, or to view both plots side-by-side. The histogram shows the discrete empirical evidence, while the density plot provides a smooth hypothesis about the population distribution from which the sample was drawn. Understanding these nuances allows the expert analyst to choose the appropriate visualization technique based on whether they need to emphasize exact counts (histogram) or the underlying theoretical shape (density plot).
Summary of Best Practices for Distribution Plotting
Effective visualization of column distributions in R requires more than just knowing the syntax; it demands adherence to best practices that ensure clarity, accuracy, and professionalism. Always begin by inspecting the raw data using functions like summary() and str() to understand the scale, type, and range of the variable before plotting. This preliminary step helps in setting appropriate axis limits and choosing suitable aesthetic customizations.
When selecting a visualization method, consider the purpose: use the density plot for comparison and generalization of shape, and use the histogram for displaying raw frequency counts. If opting for a histogram, always pay critical attention to the breaks parameter, adjusting it until the plot reveals the inherent structure of the data without becoming overly sparse or aggregated. It is often recommended to experiment with several break values to confirm that the observed modality is robust.
Finally, regardless of the chosen method, rigorous plot customization is mandatory. Ensure all plots include descriptive titles (main), clearly labeled axes (xlab, ylab), and appropriate colors (col). These elements transform a statistical output into an impactful communication tool, guaranteeing that the viewer correctly interprets the distribution of the analyzed column values in your data frame.
Cite this article
stats writer (2025). How to Easily Visualize Column Value Distributions in R. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-to-plot-distribution-of-column-values-in-r/
stats writer. "How to Easily Visualize Column Value Distributions in R." PSYCHOLOGICAL SCALES, 21 Nov. 2025, https://scales.arabpsychology.com/stats/how-to-plot-distribution-of-column-values-in-r/.
stats writer. "How to Easily Visualize Column Value Distributions in R." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/how-to-plot-distribution-of-column-values-in-r/.
stats writer (2025) 'How to Easily Visualize Column Value Distributions in R', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-to-plot-distribution-of-column-values-in-r/.
[1] stats writer, "How to Easily Visualize Column Value Distributions in R," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, November, 2025.
stats writer. How to Easily Visualize Column Value Distributions in R. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.