Table of Contents
The Chow test is a fundamental statistical tool used primarily in econometrics to determine if the true regression models from two different datasets, or two distinct periods within the same dataset, are statistically identical. Fundamentally, it tests the equality of the coefficients of two separate linear regressions.
This powerful methodology is indispensable when analyzing time series data where the relationship between variables might change abruptly due to external events, policy shifts, or technological innovation. Such an abrupt change is known as a structural break, and identifying its presence is critical because ignoring it can lead to severely biased coefficient estimates and unreliable forecasts.
This comprehensive tutorial serves as an expert guide, providing a precise, step-by-step procedure for executing the Chow test within the R programming environment. We will utilize simulated data to illustrate the process, ensuring clarity on data preparation, visualization, computation, and, crucially, the interpretation of the statistical output.
The Importance of Identifying Structural Breaks
In many economic and financial applications, researchers often assume that the underlying relationships governing variables remain constant over time. However, this assumption is frequently violated in practice. A structural break signifies a point where the parameters (intercept and slopes) of the underlying linear regression models change significantly. Failure to account for a structural break can lead to invalid statistical inference, resulting in misleading conclusions and poor predictive power.
Consider, for example, modeling the relationship between interest rates and inflation. If a central bank fundamentally changes its monetary policy regime (e.g., switching from inflation targeting to quantitative easing), the parameters defining this relationship will likely shift. The Chow test allows us to formally test whether such a change has occurred at a specified point in time, providing statistical evidence to support the segmentation of the data. This rigorous approach is standard practice in advanced econometrics.
The core philosophy of the test involves comparing the sum of squared residuals (SSR) from three different regressions: a pooled regression using all data points (assuming no break), and two separate regressions run on the partitioned segments of the data (assuming a break). The test statistic is derived from the difference in the predictive power of these models, following an F-distribution under the null hypothesis that the coefficients are stable across the regimes.
Setting Up the R Environment and Packages
Before initiating the statistical analysis, it is essential to ensure that the necessary statistical packages are installed and loaded into the R session. While base R functionality is powerful, the Chow test, particularly when testing for breaks at a specific known point, is most efficiently handled by specialized packages. For this tutorial, we rely primarily on the strucchange package, which is designed specifically for testing, monitoring, and dating structural changes in linear regression models.
Additionally, we will utilize the popular ggplot2 package for high-quality data visualization, which is crucial for initially identifying potential break points graphically. We strongly recommend ensuring these packages are installed using the install.packages() command if they are not already present on your system. Properly loading these libraries is the prerequisite for running the subsequent analysis smoothly and accurately, ensuring all specialized functions are accessible.
The structured approach to package management ensures reproducibility and consistency throughout the entire data analysis pipeline, a hallmark of rigorous statistical research. The reliance on established libraries like strucchange provides validated, peer-reviewed implementations of complex statistical tests, minimizing the risk of computational errors.
Step 1: Generating the Simulated Data
To demonstrate the utility of the Chow test, we will first construct a representative dataset. This simulated data intentionally incorporates a distinct change in the underlying linear relationship between the predictor variable (x) and the response variable (y) around a specific observation point. This deliberate introduction of a structural break allows us to validate the effectiveness of the test in a controlled environment.
The following R code generates thirty observations for two variables, x and y, stored within an R data frame named data. Notice how the values for y seem to follow a tighter, steeper positive relationship initially, which visually loosens or changes its slope after the midpoint, mimicking a real-world shift in economic parameters or physical processes. This controlled setup ensures our demonstration clearly illustrates the detection mechanism of the test.
We use the head() function to verify the successful creation and structure of the dataset, confirming that the initial rows reflect the intended structure before proceeding to the analytical steps. Data creation is the essential foundational step for any empirical study involving regression models, ensuring the input data is correctly formatted for R’s statistical functions.
#create data data <- data.frame(x = c(1, 1, 2, 3, 4, 4, 5, 5, 6, 7, 7, 8, 8, 9, 10, 10, 11, 12, 12, 13, 14, 15, 15, 16, 17, 18, 18, 19, 20, 20), y = c(3, 5, 6, 10, 13, 15, 17, 14, 20, 23, 25, 27, 30, 30, 31, 33, 32, 32, 30, 32, 34, 34, 37, 35, 34, 36, 34, 37, 38, 36)) #view first six rows of data head(data) x y 1 1 3 2 1 5 3 2 6 4 3 10 5 4 13 6 4 15
Step 2: Visualizing Potential Structural Breaks
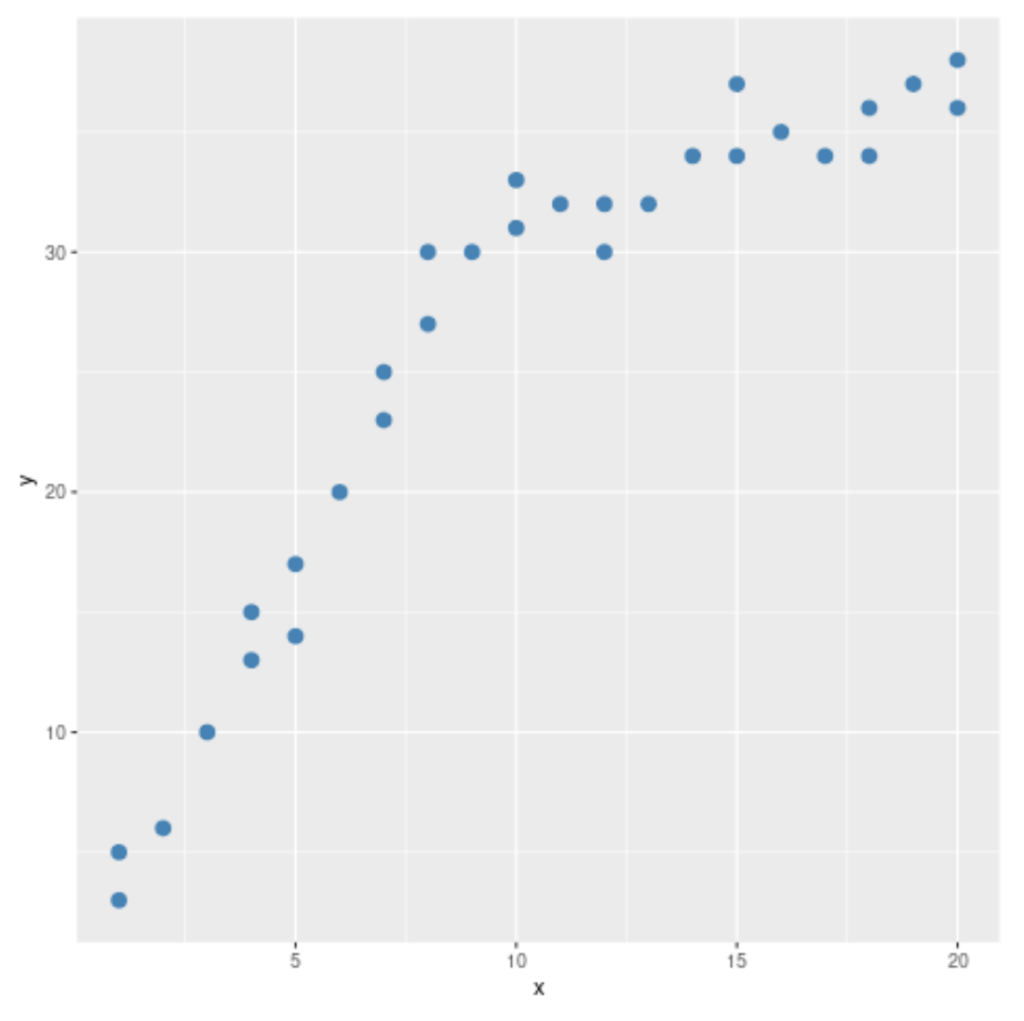
Data visualization is perhaps the most immediate and intuitive method for detecting potential anomalies, like a structural break, before formal statistical testing. By generating a simple scatterplot, we can visually inspect the relationship between the x and y variables and look for any discernible change in the slope or variance across the range of x. This step is particularly valuable in econometrics where data trends often shift due to real-world interventions.
We leverage the ggplot2 package to create a clean, professional visualization. The code below plots the data points, using a distinctive color and size to enhance visibility. This initial graphical inspection acts as crucial supporting evidence for the subsequent formal Chow test, guiding us toward the appropriate break point to test, thereby increasing the power and relevance of the statistical test.
Upon reviewing the resulting graph, a distinct pattern emerges: the positive linear trend appears consistent up until x = 10. After this value, while the relationship remains positive, the slope seems flatter, and the dispersion of points (variance) might change. This visual evidence strongly suggests that the 10th observation is a highly plausible candidate for the structural break point, justifying our decision to test this specific partition formally.
#load ggplot2 visualization package library(ggplot2) #create scatterplot ggplot(data, aes(x = x, y = y)) + geom_point(col='steelblue', size=3)

As clearly observed in the scatterplot, the visual pattern of the data suggests a fundamental change occurring after the observations corresponding to x = 10. This visual confirmation is vital, as the standard Chow test requires the hypothesized break point to be specified in advance, making this graphical exploration an indispensable preliminary step in rigorous quantitative analysis.
Step 3: Executing the Chow Test Using sctest()
With a hypothesized break point identified (at the 10th observation index, corresponding to x = 10), we proceed to the formal statistical test. The strucchange package in R provides the highly versatile sctest() function, which can execute various structural change tests, including the specialized Chow test. This function is designed to handle the complexity of comparing the residual sum of squares across partitioned datasets.
The sctest() function requires three key parameters for a fixed-point Chow test: the regression formula (data$y ~ data$x, specifying the linear relationship), the type of test explicitly specified as "Chow", and the specific index or observation number where the break is hypothesized to occur (point = 10). It is critical to note that the Chow test assesses whether the entire set of regression models coefficients—both the intercept and the slopes—are different between the two segmented periods.
This procedure essentially runs three separate ordinary least squares (OLS) regressions internally: one pooled model and two subset models. It then calculates the necessary sums of squared residuals to compute the final F-statistic, which follows an F-distribution. The resulting F-statistic effectively measures the relative reduction in the residual sum of squares achieved by fitting two separate regression models compared to fitting a single, pooled model across the entire dataset. A large F-statistic suggests the pooled model is significantly inferior.
#load strucchange package library(strucchange) #perform Chow test sctest(data$y ~ data$x, type = "Chow", point = 10) Chow test data: data$y ~ data$x F = 110.14, p-value = 2.023e-13
Interpreting the Statistical Results
The output generated by the sctest() function provides the necessary statistics to make a formal decision regarding the presence of a structural break at the specified point. The interpretation hinges on assessing the calculated F test statistic and its corresponding P-value against a predetermined significance level (typically $alpha = 0.05$).
The null hypothesis ($H_0$) of the Chow test states that the coefficients (intercept and slope) of the two separate regression models are equal, meaning no structural break exists at the specified point. This implies that a single regression model is adequate for describing the relationship across the entire sample. Conversely, the alternative hypothesis ($H_A$) posits that the coefficients are significantly different, indicating a structural change has occurred.
Analyzing the specific statistics derived from our R output leads to the following observations:
- F test statistic: 110.14
- P-value: 2.023e-13
The extremely large F-statistic (110.14) and the vanishingly small P-value (which is essentially zero when compared to common thresholds) provide compelling evidence. Since the P-value (2.023e-13) is vastly smaller than the conventional significance level of 0.05, we must strongly reject the null hypothesis. This decisive rejection confirms the presence of a statistically significant structural change in the relationship between x and y occurring at the 10th observation.
Conclusion and Practical Modeling Implications
The statistical evidence derived from the Chow test overwhelmingly supports the conclusion that a significant structural break is present in our data at the observation point corresponding to x = 10. The rejection of the null hypothesis confirms that the underlying relationship between variables x and y changes fundamentally after this point, necessitating careful consideration in subsequent modeling efforts.
In practical modeling terms, this result suggests that any subsequent analysis of this relationship should not rely on a single, pooled regression models across all thirty observations. Such a pooled model would suffer from omitted variable bias or functional form misspecification, leading to inefficient and inconsistent coefficient estimates. Instead, two separate regression models should be estimated: one for the observations up to x = 10, and another for the observations starting from x = 11 onwards. This segmentation ensures that the estimated coefficients accurately reflect the distinct relationships present in the data during these two separate regimes.
The Chow test is thus a vital tool in applied econometrics, ensuring robust and accurate model specification. By correctly identifying and accounting for structural instability, researchers can mitigate bias, improve forecast accuracy, and gain deeper insights into the dynamic processes driving their time series or cross-sectional data, ultimately leading to more trustworthy statistical conclusions.
Cite this article
stats writer (2025). How do I perform a Chow test in R?. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/how-do-i-perform-a-chow-test-in-r/
stats writer. "How do I perform a Chow test in R?." PSYCHOLOGICAL SCALES, 11 Dec. 2025, https://scales.arabpsychology.com/stats/how-do-i-perform-a-chow-test-in-r/.
stats writer. "How do I perform a Chow test in R?." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/how-do-i-perform-a-chow-test-in-r/.
stats writer (2025) 'How do I perform a Chow test in R?', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/how-do-i-perform-a-chow-test-in-r/.
[1] stats writer, "How do I perform a Chow test in R?," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, December, 2025.
stats writer. How do I perform a Chow test in R?. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.