Table of Contents
Understanding the Role of the Mean in Statistics
In the expansive field of statistics, researchers and analysts rely on various metrics to summarize and interpret complex information. Among these, the concept of central tendency serves as a foundational pillar, providing a single value that identifies the central point or “typical” value of a data set. The arithmetic mean, commonly referred to simply as the mean, is perhaps the most ubiquitous of these measures. It offers a mathematical representation of the average, calculated by aggregating every individual value in a collection and dividing that total by the quantity of observations present. This process ensures that every data point contributes to the final result, making the mean a highly inclusive metric for general data analysis.
While the mean is frequently utilized in academic, professional, and everyday contexts, its application is not without nuance. It serves as a critical tool for identifying trends, making predictions, and performing comparative analyses between different groups. However, to use the mean effectively, one must understand both its mathematical strengths and its inherent limitations. In many scenarios, the mean provides a clear and concise snapshot of a population, but in others, it can be deceptive, failing to reflect the true reality of the data. This duality makes it essential for anyone working with quantitative information to recognize when the mean is the most appropriate measure of center and when alternative metrics, such as the median or mode, might be more reliable.
The primary objective of this article is to explore the advantages and disadvantages of employing the mean within statistical frameworks. By examining its mathematical properties, its behavior in various distributions, and its practical implications in real-world scenarios like economic forecasting or demographic studies, we can develop a more sophisticated approach to data interpretation. Throughout the following sections, we will break down the formula for the mean, highlight why it is favored in many computational models, and illustrate the specific circumstances—such as the presence of outliers or significant skewness—where its utility begins to diminish. Understanding these factors is key to producing accurate and ethical statistical reports.
The Mathematical Framework and Calculation of the Mean
To fully appreciate the utility of the mean, one must first grasp its underlying mathematical construction. The arithmetic mean is defined as the sum of a collection of numbers divided by the count of those numbers. This is represented formally by the equation: Mean = Σxi / n. In this formula, the Greek letter Σ (sigma) acts as the summation operator, indicating that every value in the data set should be added together. The variable xi represents the individual observations within the set, while n signifies the total number of observations. This straightforward arithmetic makes the mean one of the most accessible tools in statistics, allowing for quick calculations even with larger datasets using modern computing power.
The components of this formula highlight the mean’s comprehensive nature. Because the numerator involves the summation of every single xi, the resulting value is inherently tied to every piece of information available. This property distinguishes the mean from the median, which only considers the middle value in an ordered list, or the mode, which only tracks the most frequent occurrence. In statistics, this “total inclusion” is often viewed as a significant benefit, as it ensures that the resulting average is a function of the entire population or sample under review, rather than just a subset of the data points.
Furthermore, the mean possesses unique algebraic properties that make it indispensable for higher-level statistics. For instance, the sum of the deviations of individual data points from the mean is always zero. This characteristic is vital for calculating other important metrics, such as variance and standard deviation. These secondary metrics provide insight into the “spread” or volatility of a data set, and since they are derived from the mean, the mean remains the starting point for almost all advanced quantitative modeling, including regression analysis and hypothesis testing.
Advantage: Comprehensive Integration of Data Observations
The first major advantage of using the mean is its ability to incorporate every observation within a data set into its final calculation. In many scientific and social research contexts, the goal is to capture as much information as possible to minimize the risk of missing subtle variations in the population. Because the mean accounts for the magnitude of every value, it reflects shifts in the data more sensitively than other measures of central tendency. If a single value in a dataset changes, even by a small amount, the mean will shift to reflect that change, ensuring that the final average is always an up-to-date representation of the total information available.
This comprehensive nature is particularly beneficial when the data is roughly symmetrical and follows a normal distribution. In such cases, the mean provides a highly stable and reliable estimate of the “center” because it balances the weight of all values on either side of the peak. Analysts prefer this because it maximizes statistical efficiency. By using all available data, the mean often has a smaller sampling error than the median in a normal population, meaning that if you were to take multiple samples from the same population, the means of those samples would likely be closer to each other than the medians would be.
In addition to efficiency, the inclusion of all data points allows for more complex mathematical manipulations. Since the mean is based on the sum of values, it is “additive.” For example, if you know the means and sample sizes of two separate groups, you can easily calculate the combined mean of both groups. This is not possible with the median without having access to the raw data of both sets. This flexibility makes the mean the preferred choice for large-scale meta-analyses and industrial applications where data is continuously aggregated from multiple sources.
Advantage: Conceptual Simplicity and Universal Interpretability
Beyond its mathematical rigor, the mean is favored for its simplicity and ease of interpretation. Most individuals are introduced to the concept of an “average” early in their education, making it a universally understood metric. Whether discussing sports statistics, school grades, or corporate earnings, the mean provides a common language that allows experts and laypeople alike to communicate complex findings without requiring a deep dive into advanced theory. This clarity is a significant advantage in fields like journalism, marketing, and public policy, where information must be communicated quickly and effectively to a broad audience.
The ease of calculation also plays a vital role in its widespread adoption. While modern software can calculate any measure of central tendency instantly, the mean remains a practical tool that can be estimated or calculated manually with minimal effort. This accessibility ensures that it is the first metric people turn to when they need a quick overview of a situation. For instance, a business owner can quickly sum their daily sales and divide by thirty to find their mean daily revenue, providing immediate insight into the health of their enterprise without needing a specialized statistics consultant.
Moreover, the mean serves as a intuitive benchmark for comparison. When we say a value is “above average” or “below average,” we are almost always referring to the arithmetic mean. This creates a standard point of reference that helps individuals contextualize their own data. For example, knowing that the mean fuel efficiency for a certain class of vehicles is 30 miles per gallon allows a consumer to instantly judge whether a specific car is efficient or inefficient relative to its peers. This comparative utility is a cornerstone of decision-making processes across various industries.
Disadvantage: Vulnerability to Extreme Outliers
Despite its many benefits, the mean has a significant weakness: it is highly sensitive to outliers. An outlier is an observation that lies an abnormal distance from other values in a random sample from a population. Because the mean incorporates the magnitude of every value, a single extreme number—whether exceptionally high or exceptionally low—can disproportionately “pull” the mean in its direction. This sensitivity can lead to a calculated average that does not actually represent any of the values in the data set, potentially leading to incorrect conclusions or misguided policies.
Consider a scenario where you are calculating the mean wealth of a group of ten people. If nine of them earn $50,000 a year and the tenth person is a billionaire, the mean income for the group would be in the millions of dollars. In this case, the mean fails entirely to describe the “typical” experience of the group members; none of the nine average earners are millionaires, and the billionaire’s wealth is vastly understated by the group average. This is why, in studies of wealth and income, statistics professionals often prefer the median, which remains unaffected by these extreme values.
The impact of outliers is particularly problematic in small data sets. In a sample of five items, one outlier represents 20% of the total influence on the mean. As the sample size increases, the influence of a single outlier diminishes, but the risk never fully disappears. This vulnerability requires analysts to perform “data cleaning” or to use robust statistical methods to identify and handle outliers before reporting a mean value. Without these precautions, the mean can act as a distorting lens rather than a clear window into the data.
Disadvantage: Limitations in Skewed Distributions
Another major drawback of the mean emerges when dealing with skewness. A data set is considered skewed when its distribution is not symmetrical, meaning it has a “tail” that extends further in one direction than the other. In a normal distribution, the mean, median, and mode are all located at the same central point. However, in a skewed distribution, the mean is dragged away from the peak toward the long tail. This results in a value that may be misleading because it does not align with the most frequent or the most central values in the set.
In a positively skewed distribution (where the tail extends to the right), the mean will be greater than the median. This often happens in real-world data such as housing prices or individual tax contributions, where a small number of very high values pull the average upward. Conversely, in a negatively skewed distribution (tail to the left), the mean will be lower than the median. Relying solely on the mean in these situations can create a false impression of the “average” experience, as the mean is being influenced more by the rare, extreme values in the tail than by the bulk of the data clustered at the other end.
Consequently, the mean can lead to poor decision-making if the distribution of the data is ignored. For instance, if a city planner looks only at the mean commute time in a city that has a highly skewed distribution due to a few extremely long-distance commuters, they might over-invest in infrastructure that doesn’t actually help the majority of citizens whose commute times are much shorter. Understanding the shape of the distribution is crucial because it tells the analyst whether the mean is a truthful representative or a statistical artifact of skewness.
Practical Examples: Analyzing Salaries and Real Estate
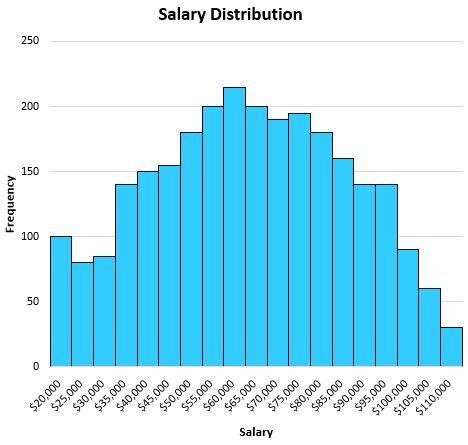
To see these principles in action, let us examine how the mean behaves in different real-world contexts. First, consider a city where the salaries of residents are distributed fairly evenly, as shown in the following histogram:

In this scenario, the distribution is symmetrical. If you were to divide the graph down the center, both halves would appear roughly identical. Because there are no significant outliers and the data is not skewed, the mean serves as an excellent measure of the “center” of this data set. It provides a reliable summary of what a typical resident earns.
As illustrated below, the calculated mean salary is $63,000, which sits perfectly in the heart of the distribution:

In this instance, the mean succeeds because it utilizes every salary in the city to arrive at a figure that feels “typical.” However, the situation changes drastically when the data becomes right-skewed, a common occurrence in economic data where a small percentage of the population earns significantly more than the rest:

Notice how the high values on the right side pull the mean away from the cluster where most people are located. In this example, the mean suggests an “average” salary of $47,000, but the median is only $32,000. The median here is a much better reflection of the “typical” individual’s earnings. A final example involves housing square footage, where a few massive estates can distort the mean for an entire neighborhood:

Here, the presence of a few extremely large houses causes the mean square footage to rise sharply. Prospective buyers looking at the “average” size would be misled into thinking the typical house on the street is much larger than it actually is. These examples underscore why it is vital to pair the mean with a visual inspection of the data or with other statistics like the standard deviation to get the full picture.
Conclusion: Balancing the Strengths and Weaknesses of the Mean
The arithmetic mean remains one of the most powerful and widely used tools in statistics for good reason. Its mathematical elegance, which incorporates every available data point, allows for high statistical efficiency and serves as the basis for many advanced analytical techniques. Furthermore, its conceptual simplicity makes it an ideal metric for communicating data to a general audience, providing a clear and familiar benchmark for understanding the “average” value within a population. When applied to symmetrical normal distributions, the mean is often the most precise and useful measure of central tendency available to researchers.
However, as we have explored, the mean is not a universal solution. Its sensitivity to outliers and its tendency to be pulled by skewness mean that it can easily provide a distorted view of reality. In datasets characterized by extreme inequality or irregular patterns, the mean can become an “unreliable narrator,” suggesting a typical value that no one in the group actually experiences. To avoid these pitfalls, it is essential for analysts to evaluate the shape and spread of their data before deciding which metric to prioritize. By understanding both the advantages and disadvantages of the mean, we can ensure our statistical conclusions are both accurate and meaningful.
Ultimately, the choice of whether to use the mean, median, or mode depends on the specific goals of the analysis and the nature of the data itself. A robust statistical approach often involves reporting multiple measures of center and spread—such as the mean alongside the standard deviation—to provide a comprehensive view. By doing so, we respect the complexity of the data and provide a more honest representation of the trends and patterns we seek to uncover. For those looking to deepen their understanding of these concepts, the following resources and tutorials provide further exploration into the world of statistical analysis.
- Standard Error: Understanding the precision of your mean.
- Central Limit Theorem: Why the mean is so important in large samples.
- Weighted Mean: How to calculate an average when some values are more important than others.
- Interquartile Range: A robust way to measure spread alongside the median.
Cite this article
stats writer (2026). How to Calculate and Interpret the Mean in Statistics. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/what-are-the-advantages-and-disadvantages-of-using-mean-in-statistics/
stats writer. "How to Calculate and Interpret the Mean in Statistics." PSYCHOLOGICAL SCALES, 20 Feb. 2026, https://scales.arabpsychology.com/stats/what-are-the-advantages-and-disadvantages-of-using-mean-in-statistics/.
stats writer. "How to Calculate and Interpret the Mean in Statistics." PSYCHOLOGICAL SCALES, 2026. https://scales.arabpsychology.com/stats/what-are-the-advantages-and-disadvantages-of-using-mean-in-statistics/.
stats writer (2026) 'How to Calculate and Interpret the Mean in Statistics', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/what-are-the-advantages-and-disadvantages-of-using-mean-in-statistics/.
[1] stats writer, "How to Calculate and Interpret the Mean in Statistics," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, February, 2026.
stats writer. How to Calculate and Interpret the Mean in Statistics. PSYCHOLOGICAL SCALES. 2026;vol(issue):pages.