Table of Contents
When conducting statistical analysis, the decision regarding the removal of outliers is one of the most critical and debated steps. Generally, outliers should be removed only when they are demonstrably the result of an experimental error, measurement failure, or other egregious data collection inaccuracies. Allowing these erroneous points to remain can significantly skew the data, potentially leading to inaccurate statistical inferences and fundamentally flawed conclusions.
However, analysts must proceed with extreme caution. Outliers are not inherently bad; they sometimes represent genuine, albeit rare, events within the underlying population distribution. Removal should only occur after rigorous investigation confirms that the data point is not a legitimate observation. The process requires careful consideration, transparency, and often, documentation of the results both with and without the suspect data points.
1. Understanding the Nature of Outliers
An outlier is formally defined as an observation that lies an abnormal distance from other values in a random sample from a population. They stand apart, often dramatically, from the bulk of the dataset. Identifying these points is the first step; deciding how to handle them is the true challenge of robust statistical practice.
The primary concern regarding outliers stems from their immense leverage on standard statistical metrics. They possess the power to distort measures of central tendency, inflate estimates of variance, and compromise the integrity of predictive models. For example, a single extreme value can drastically pull the sample mean away from the median, misrepresenting the typical value of the distribution.
Conversely, outliers are not always contaminants. They can be incredibly informative, revealing abnormal cases, rare events, or subgroups with distinct characteristics. In epidemiology, for instance, an outlier might indicate a rare drug resistance mechanism; in finance, it could signal a sudden, high-impact market event. Therefore, the decision to remove or retain an observation hinges on its suspected origin—is it error or genuine phenomenon?
2. A Systematic Approach to Outlier Management
Given the dual nature of outliers—potentially harmful noise or valuable signal—a systematic approach is essential. Data scientists and statisticians must employ a structured decision-making process before arbitrarily deleting observations. This structure ensures objectivity and accountability in the data cleaning process.
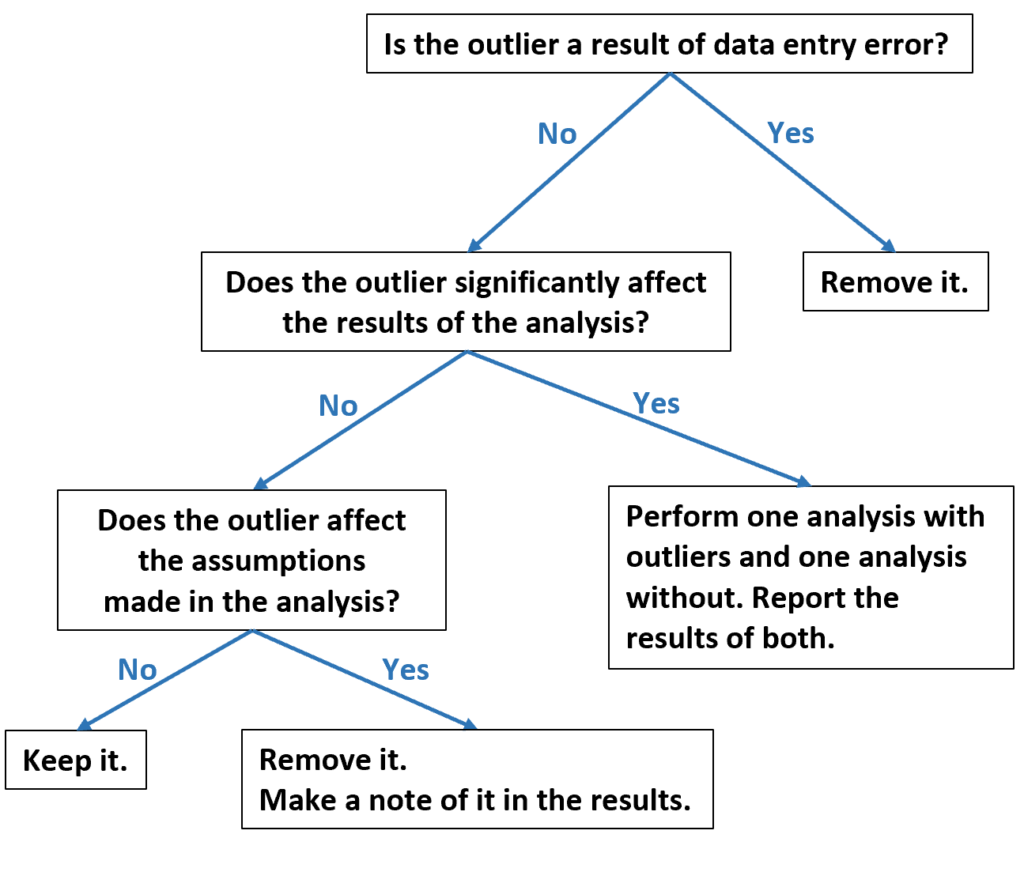
Fortunately, a structured flowchart can guide this critical decision. By addressing a sequence of increasingly complex questions about the outlier’s source and influence, analysts can determine the most statistically sound path forward. The following visual summary outlines the key stages in this decision pathway:

We will now delve into a detailed examination of each pivotal question posed in this diagnostic flow chart, starting with the most straightforward case: data entry errors.
3. Is the Outlier a Result of Data Entry Error or Measurement Failure?
The most justifiable reason for removing an outlier is when it is directly traceable to an unambiguous mistake in data acquisition, recording, or transcription. These are not legitimate data points reflecting the studied phenomenon; they are artifacts of the measurement process itself.
Consider the following scenario often encountered in biological studies. A biologist is meticulously collecting data on the height of a specific plant species, typically ranging between five and eight inches. The recorded data points are:
- 6.83 inches
- 7.51 inches
- 5.21 inches
- 5.84 inches
- 7.83 inches
- 755 inches
- 6.53 inches
- 6.31 inches
- 5.91 inches
In this sequence, the observation of 755 inches stands out as a clear and egregious data entry error. It is biologically impossible for this species to reach such a height, strongly suggesting a misplaced decimal point (the true value was likely 7.55 inches). If this erroneous observation were retained, and a measure of central tendency like the mean height were calculated, this single point would drastically distort the result, generating a completely inaccurate representation of the plant sample’s average size.
In such compelling scenarios, where the outlier’s origin is purely clerical or mechanical error and not a reflection of the population’s true variance, removal is the appropriate and responsible action. The analyst should document the identified error, the corrected or removed value, and the rationale for the action taken.
4. Does the Outlier Significantly Affect Descriptive Statistics?
Once data entry errors are ruled out, the next step involves assessing the statistical impact of the legitimate outliers. The most immediate influence is often seen on descriptive statistics, particularly the mean. A single extreme value can pull the mean dramatically in its direction, thereby failing to represent the typical value of the sample.
If an observation is a genuine, non-error outlier, we must test its influence. We calculate the key descriptive statistics both including and excluding the observation. If the removal results in minimal change (e.g., less than a 5% shift in the mean or median), the outlier might be safely retained, assuming no other violations occur. However, if the outlier causes a substantial shift, we must proceed to examine its influence on inferential models.
5. Evaluating the Outlier’s Influence on Regression Models
Beyond simple descriptive statistics, the critical test for an outlier’s retention involves assessing its leverage in inferential modeling, such as fitting a regression model. A regression analysis aims to characterize the relationship between a predictor variable and a response variable. An outlier can exert disproportionate influence, changing the slope and intercept of the fitted line.
Consider the biologist example again, now studying the relationship between fertilizer applied (predictor) and plant height (response). She intends to fit a simple linear regression model. The initial data points are recorded:

Visually, the final observation (high fertilizer, slightly low height) appears isolated. However, simply being distant does not necessitate removal. We must assess its specific leverage. If we plot the data, we can visualize how this point interacts with the overall trend:

In this initial scatterplot, the outlier is clearly visible, but its horizontal position relative to the main cloud of data is not extreme. The resulting regression line (the blue line) might not shift dramatically if this point were removed. This type of outlier, which lies far from the bulk of the data vertically but close to the mean of the predictor variable, often does not exert high leverage on the regression slope.
Contrast this with a high-leverage outlier, which sits far away from the mean of the predictor variable and also far from the predicted response. Suppose we encounter the following scenario:

This second outlier significantly affects the slope of the regression model, pulling the fit dramatically towards itself. In such a case, the model fitted including the outlier provides a distorted view of the true relationship among the majority of the data points. Best practice here involves fitting two separate models: one with the outlier retained and one with it removed. Both results should be reported, allowing the audience to assess the robustness of the findings and the specific impact of the influential observation.
6. Does the Outlier Violate Statistical Assumptions?
Even if an outlier does not drastically skew the central tendency or exert high leverage on a regression line, it must be evaluated against the underlying statistical assumptions required by the chosen analysis method. Many parametric tests, such as ANOVA or T-tests, rely on assumptions of normality, homogeneity of variance, and independence of errors.
An extreme outlier can severely compromise these assumptions. For example, a single extreme value can introduce severe non-normality or heteroscedasticity (non-constant variance) into the residual distribution. If the outlier does not affect the assumptions, and it is a genuine data point, it can typically be retained.
If, however, a genuine outlier is found to violate a fundamental statistical assumption—a scenario often determined through examining residual plots or running specific diagnostic tests (like Shapiro-Wilk for normality)—the analyst faces a choice among several remedial options.
7. Strategies for Handling Assumption Violations
When an outlier is genuine but introduces assumption violations, removal is one path, but not the only one. Analysts must weigh the loss of information incurred by removal against the statistical instability caused by retention. The primary strategies for mitigation include removal, transformation, or employing robust statistical methods.
Removal and Reporting: We can choose to simply remove the problematic observation. This is often the simplest solution, provided the loss of a single data point does not compromise the overall sample size or representation. Crucially, this removal must be documented transparently in the analysis report, noting the observation removed, the reason (assumption violation), and the impact on the final results.
Data Transformation: Instead of discarding information, a powerful alternative is applying a data transformation. Common transformations include taking the square root, the logarithm (log transformation), or the reciprocal of all data values. Data transformation is mathematically designed to “shrink” extreme outlier values relative to the rest of the dataset, thereby mitigating their influence and often achieving a distribution that better satisfies the required parametric assumptions, such as normality.
Employing Robust Methods: A final, sophisticated approach involves utilizing statistical techniques that are inherently robust to outliers. These methods, such as non-parametric tests (e.g., Mann-Whitney U or Wilcoxon signed-rank test) or robust regression (e.g., M-estimators), reduce the weight given to extreme observations during calculation, thus providing reliable estimates without requiring the physical removal of the data point.
8. Final Best Practices in Outlier Documentation
Regardless of the chosen method—removal due to error, retention due to low influence, transformation, or application of robust statistics—the decision process must be meticulously documented. Transparency is paramount in scientific reporting.
Analysts should maintain a clear record in the output of their analysis detailing:
- The method used to identify potential outliers (e.g., Z-scores, IQR method, Mahalanobis distance).
- The source investigation for each identified point (error vs. genuine).
- The rationale for the final decision (e.g., “removed because 755 inches was identified as a data entry error,” or “retained because it did not significantly impact the regression slope”).
- If removed, the results should compare the analysis performed on the raw data versus the cleaned data, demonstrating the impact of the removal.
This comprehensive reporting ensures reproducibility and allows readers and peer reviewers to fully understand the integrity and limitations of the statistical findings.
9. Technical Tutorials for Outlier Handling
The following resources provide practical, software-specific guidance on identifying and managing outliers within various statistical environments, enabling users to implement the decision-making framework discussed above:
Cite this article
stats writer (2025). How to Easily Identify and Remove Outliers in Your Data. PSYCHOLOGICAL SCALES. Retrieved from https://scales.arabpsychology.com/stats/when-should-outliers-in-data-be-removed/
stats writer. "How to Easily Identify and Remove Outliers in Your Data." PSYCHOLOGICAL SCALES, 2 Dec. 2025, https://scales.arabpsychology.com/stats/when-should-outliers-in-data-be-removed/.
stats writer. "How to Easily Identify and Remove Outliers in Your Data." PSYCHOLOGICAL SCALES, 2025. https://scales.arabpsychology.com/stats/when-should-outliers-in-data-be-removed/.
stats writer (2025) 'How to Easily Identify and Remove Outliers in Your Data', PSYCHOLOGICAL SCALES. Available at: https://scales.arabpsychology.com/stats/when-should-outliers-in-data-be-removed/.
[1] stats writer, "How to Easily Identify and Remove Outliers in Your Data," PSYCHOLOGICAL SCALES, vol. X, no. Y, ص Z-Z, December, 2025.
stats writer. How to Easily Identify and Remove Outliers in Your Data. PSYCHOLOGICAL SCALES. 2025;vol(issue):pages.